1.概述
1.1 不变性
底层是final修饰的char数组,当修改一个字符串的时候其实是重新得到一个新的字符串,修改引用的地址。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[];
}
我们可以看出来两点:
- String 被 final 修饰,说明 String 类绝不可能被继承了,也就是说任何对 String 的操作方法,都不会被继承覆写;
- String 中保存数据的是一个 char 的数组 value。我们发现 value 也是被 final 修饰的,也就是说 value 一旦被赋值,内存地址是绝对无法修改的,而且 value 的权限是 private 的,外部绝对访问不到,String 也没有开放出可以对 value 进行赋值的方法,所以说 value 一旦产生,内存地址就根本无法被修改。
1.2 字符串乱码
String str ="nihao 你好 喬亂";
// 字符串转化成 byte 数组
byte[] bytes = str.getBytes("ISO-8859-1");
// byte 数组转化成字符串
String s2 = new String(bytes);
log.info(s2);
// 结果打印为:
nihao ?? ??
打印的结果为??,这就是常见的乱码表现形式。这时候有同学说,是不是我把代码修改成 String s2 = new String(bytes,“ISO-8859-1”); 就可以了?这是不行的。主要是因为 ISO-8859-1 这种编码对中文的支持有限,导致中文会显示乱码。唯一的解决办法,就是在所有需要用到编码的地方,都统一使用 UTF-8,对于 String 来说,getBytes 和 new String 两个方法都会使用到编码,我们把这两处的编码替换成 UTF-8 后,打印出的结果就正常了。
2.取子串
name.substring(0, 1).toLowerCase() + name.substring(1);,使用 substring 方法,该方法主要是为了截取字符串连续的一部分,substring 有两个方法:
- public String substring(int beginIndex, int endIndex) beginIndex:开始位置,endIndex:结束位置;前闭后开
- public String substring(int beginIndex)beginIndex:开始位置,结束位置为文本末尾。即从beginIndex到最后
substring 方法的底层使用的是字符数组范围截取的方法 :Arrays.copyOfRange(字符数组, 开始位置, 结束位置); 从字符数组中进行一段范围的拷贝。
还有一个返回类型为CharSequence的取子串的方法
public CharSequence subSequence(int beginIndex, int endIndex) {
return this.substring(beginIndex, endIndex);
}
仅仅只是返回类型不一样
3.相等判断
我们判断相等有两种办法,equals 和 equalsIgnoreCase。后者判断相等时,会忽略大小写,近期看见一些面试题在问:如果让你写判断两个 String 相等的逻辑,应该如何写,我们来一起看下 equals 的源码,整理一下思路:
public boolean equals(Object anObject) {
// 判断内存地址是否相同
if (this == anObject) {
return true;
}
// 待比较的对象是否是 String,如果不是 String,直接返回不相等
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
// 两个字符串的长度是否相等,不等则直接返回不相等
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
// 依次比较每个字符是否相等,若有一个不等,直接返回不相等
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
判断引用地址是否相同,类型是否相同,字符串长度是否一致,再逐个判断字符是否相同
4.替换、删除
替换在工作中也经常使用,有 replace 替换所有字符、replaceAll 批量替换字符串、replaceFirst 替换遇到的第一个字符串三种场景。
其中在使用 replace 时需要注意,replace 有两个方法,一个入参是 char,一个入参是 String,前者表示替换所有字符,如:name.replace(‘a’,‘b’),后者表示替换所有字符串,如:name.replace(“a”,“b”),两者就是单引号和多引号的区别。
需要注意的是, replace 并不只是替换一个,是替换所有匹配到的字符或字符串哦。
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
// 先找到第一个和oldChar匹配的字符位置
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
// i之前的字符直接拷贝
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
// i之后的字符 若是oldChar则将其替换
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);
}
}
return this;
}
值得一提的是,最后return的String 的构造方式中多了一个boolean类型的参数。
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
相比于String(char value[])
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
share参数指定限定是true,该方法仅仅是直接将value的数组的地址返回给一个新的引用。
而第二个构造方法则是将value数组进行了拷贝,开辟了一个新的空间保存拷贝后的数组,将新的数组给一个新的引用。
效率上来说第一个更快,共享内部数组节约内存。但第一种方法是私有的,外部无法访问。
在Java 7 之前有很多String里面的方法都使用这种“性能好的、节约内存的、安全”的构造函数。
但是在Java 7中,substring已经不再使用这种“优秀”的方法了,为什么呢? 虽然这种方法有很多优点,但是他有一个致命的缺点,可能造成内存泄露。
String aLongString = "...a very long string...";
String aPart = data.substring(20, 40);
return aPart;
在这里aLongString只是临时的,真正有用的是aPart,其长度只有20个字符,但是它的内部数组却是从aLongString那里共享的,因此虽然aLongString本身可以被回收,但它的内部数组却不能(如下图)。这就导致了内存泄漏。
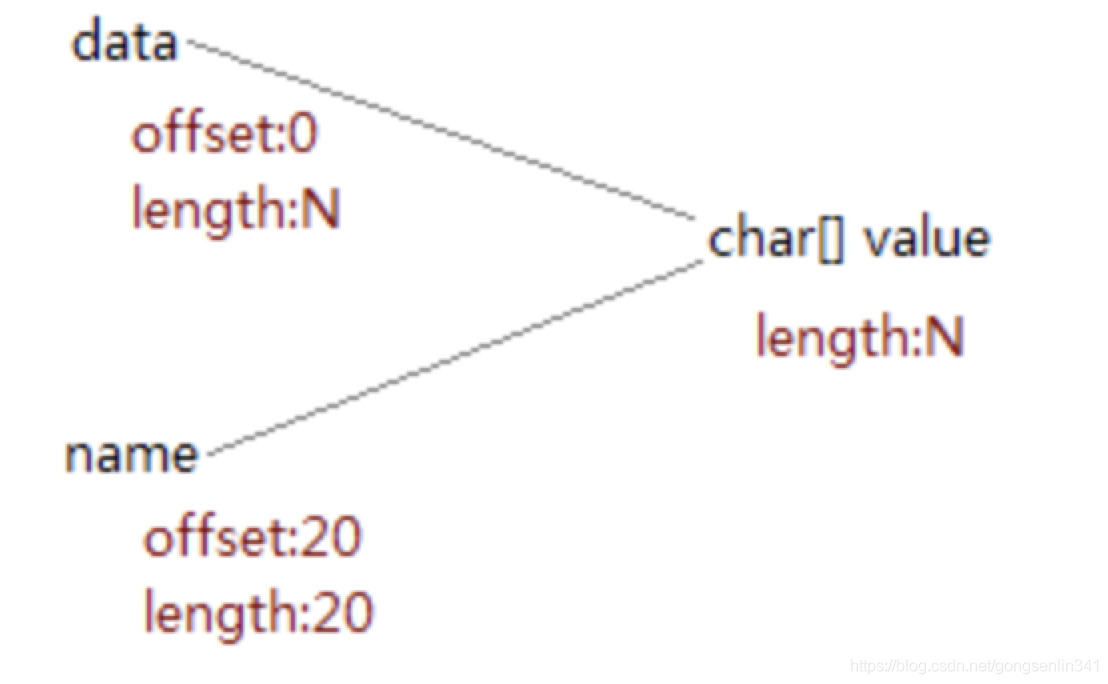
内存泄漏是指,一部分没有被引用的内存但是无法被释放。
上面提到的是替换字符
下面是字符串的替换
- replaceFirst(String regex, String replacement)
替换满足正则表示的第一个字符串,替换成replacement - replaceAll(String regex, String replacement)
替换所有符合正则表达式的字符串为replacement - replace(CharSequence target, CharSequence replacement)
将字符串中按顺序满足target的字符串 替换成replacement
5.拆分和合并
拆分我们使用 split 方法,该方法有两个入参数。第一个参数是我们拆分的标准字符,第二个参数是一个 int 值,叫 limit,来限制我们需要拆分成几个元素。如果 limit 比实际能拆分的个数小,按照 limit 的个数进行拆分。
public String[] split(String regex, int limit) {
char ch = 0;
if (((regex.value.length == 1 &&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
boolean limited = limit > 0;
ArrayList<String> list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) { // 找第一个匹配ch字符的位置
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;//修改匹配寻找位置
} else { // 最后一个
//assert (list.size() == limit - 1);
list.add(substring(off, value.length));
off = value.length;
break;
}
}
// If no match was found, return this
if (off == 0)
return new String[]{this};
// Add remaining segment
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// Construct result
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).length() == 0) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
}
String s ="boo:and:foo";
// 我们对 s 进行了各种拆分,演示的代码和结果是:
s.split(":") 结果:["boo","and","foo"]
s.split(":",2) 结果:["boo","and:foo"]
s.split(":",5) 结果:["boo","and","foo"]
s.split(":",-2) 结果:["boo","and","foo"]
s.split("o") 结果:["b","",":and:f"]
s.split("o",2) 结果:["b","o:and:foo"]
从演示的结果来看,limit 对拆分的结果,是具有限制作用的,还有就是拆分结果里面不会出现被拆分的字段。
那如果字符串里面有一些空值呢,拆分的结果如下:
String a =",a,,b,";
a.split(",") 结果:["","a","","b"]
从拆分结果中,我们可以看到,空值是拆分不掉的,仍然成为结果数组的一员,如果我们想删除空值,只能自己拿到结果后再做操作,但 Guava(Google 开源的技术工具) 提供了一些可靠的工具类,可以帮助我们快速去掉空值,如下:
String a =",a, , b c ,";
// Splitter 是 Guava 提供的 API
List<String> list = Splitter.on(',')
.trimResults()// 去掉空格
.omitEmptyStrings()// 去掉空值
.splitToList(a);
log.info("Guava 去掉空格的分割方法:{}",JSON.toJSONString(list));
// 打印出的结果为:
["a","b c"]
从打印的结果中,可以看到去掉了空格和空值,这正是我们工作中常常期望的结果,所以推荐使用 Guava 的 API 对字符串进行分割。
合并我们使用 join 方法,此方法是静态的,我们可以直接使用。方法有两个入参,参数一是合并的分隔符,参数二是合并的数据源,数据源支持数组和 List,在使用的时候,我们发现有两个不太方便的地方:
- 不支持依次 join 多个字符串,比如我们想依次 join 字符串 s 和 s1,如果你这么写的话 String.join(",",s).join(",",s1) 最后得到的是 s1 的值,第一次 join 的值被第二次 join 覆盖了;
- 如果 join 的是一个 List,无法自动过滤掉 null 值。
而 Guava 正好提供了 API,解决上述问题,我们来演示一下:
// 依次 join 多个字符串,Joiner 是 Guava 提供的 API
Joiner joiner = Joiner.on(",").skipNulls();
String result = joiner.join("hello",null,"china");
log.info("依次 join 多个字符串:{}",result);
List<String> list = Lists.newArrayList(new String[]{"hello","china",null});
log.info("自动删除 list 中空值:{}",joiner.join(list));
// 输出的结果为;
依次 join 多个字符串:hello,china
自动删除 list 中空值:hello,china
从结果中,我们可以看到 Guava 不仅仅支持多个字符串的合并,还帮助我们去掉了 List 中的空值,这就是我们在工作中常常需要得到的结果。
6.匹配
匹配的方法有很多
- regionMatchesregionMatches(int toffset, String other, int ooffset,int len)
从调用这个方法的字符串的 toffset位置开始,匹配传入的参数other从offset开始 长度为len的一段是否一致 - regionMatches(boolean ignoreCase, int toffset,String other, int ooffset, int len)
同上,仅多了一个忽略大小写的不同 - startsWith(String prefix, int toffset)
判断从toffset开始的字符串和prefix是否一致,若toffset为0或者直接调用startsWith(String prefix),则表示判断字符串的前缀是不是prefix - endsWith(String suffix) 判断字符串的后缀是不是suffix
- indexOf(int ch) indexOf(int ch, int fromIndex)
匹配满足字符ch的下标,没有则返回-1;若fromIndex<0 则和=0是一样的效果。 - indexOfSupplementary(int ch, int fromIndex)从fromIndex寻找ch匹配的下标
private int indexOfSupplementary(int ch, int fromIndex) {
if (Character.isValidCodePoint(ch)) {
final char[] value = this.value;
final char hi = Character.highSurrogate(ch);
final char lo = Character.lowSurrogate(ch);
final int max = value.length - 1;
for (int i = fromIndex; i < max; i++) {
if (value[i] == hi && value[i + 1] == lo) {
return i;
}
}
}
return -1;
}
java中使用UTF-16编码 16位 有65536种取值 和char类型的位数一样,但是Unicode包含的字符远超有65536,所以使用2个char来存储这一个字符,分别用高位和低位来存储Character.highSurrogate(ch), Character.lowSurrogate(ch);
- lastIndexOf(int ch) lastIndexOf(int ch, int fromIndex) lastIndexOfSupplementary(int ch, int fromIndex) 和6 差不多 只是这里是从后往前找
- indexOf(String str) 匹配字符串的首位的下标
- static int indexOf(char[] source, int sourceOffset, int sourceCount,char[] target, int targetOffset, int targetCount,int fromIndex)
这是一个静态方法,从source中第sourceOffset开始sourceCount个字符中 寻找 target中 从targteOffset开始targetCount个字符组成的字符串串匹配的下标 - lastIndexOf(String str) lastIndexOf(String str, int fromIndex)
lastIndexOf(char[] source, int sourceOffset, int sourceCount,String target, int fromIndex)
从后往前找 - matches(String regex)
匹配正则表达式 - contains(CharSequence s)
查看是否包含某一个序列