一.搜索
需求:根据书名或者作者名字来进行搜索:
html文件:
地址:html
<form class="form-inline">
<div class="form-group">
<select name="search_field" id="search_field" class="form-control">
<option value="title__contains">书名</option>
<option value="authors__name__contains">作者</option>
</select>
</div>
<div class="form-group">
<input type="text" class="form-control" name="kw" placeholder="content">
</div>
<button type="submit" class="btn btn-default">搜索</button>
</form>
效果:
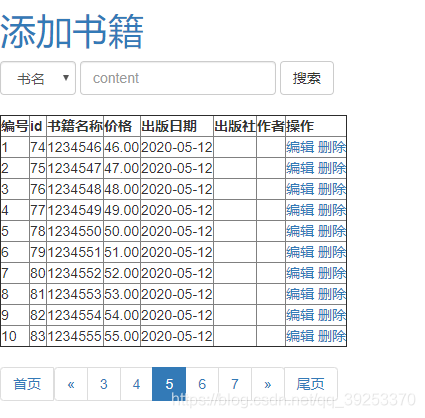
后端通过获取前端选择的内容和输入的内容来进行查询:
#当前页
page_num = request.GET.get('page')
req_path = request.path
search_field = request.GET.get('search_field')
kw = request.GET.get('kw')
if kw:
#如果kw有值就进行搜索返回
book_list = models.Book.objects.filter(**{search_field:kw}) #这种只能进行并且的查询,or查询不能应用
优化:
q_obj = Q() #实例化Q对象
q_obj.connector = 'or' #默认是and
q_obj.children.append((search_field,kw))
# q_obj.children.append((search_field2,kw2)) # 和上面一个就是或的关系
book_list = models.Book.objects.filter(q_obj)
else:
#如果没有就返回所有
book_list = models.Book.objects.all()
#这样有没有内容都会进行分页
#总数
page_num_count = book_list.count()
#分页内容
page_obj = MyPage(page_num,page_num_count,req_path,5,10,get_data)
page_html = page_obj.page_html()
book_data = book_list[page_obj.start_num:page_obj.end_num]
return render(request, 'manytable/show_book.html',{'book_data': book_data, 'page_html': page_html})
这里测试的时候会发现一个问题,搜索结果很多的时候,点击下一页并不是带有搜索结果的下一页,而是全部内容的第二页:
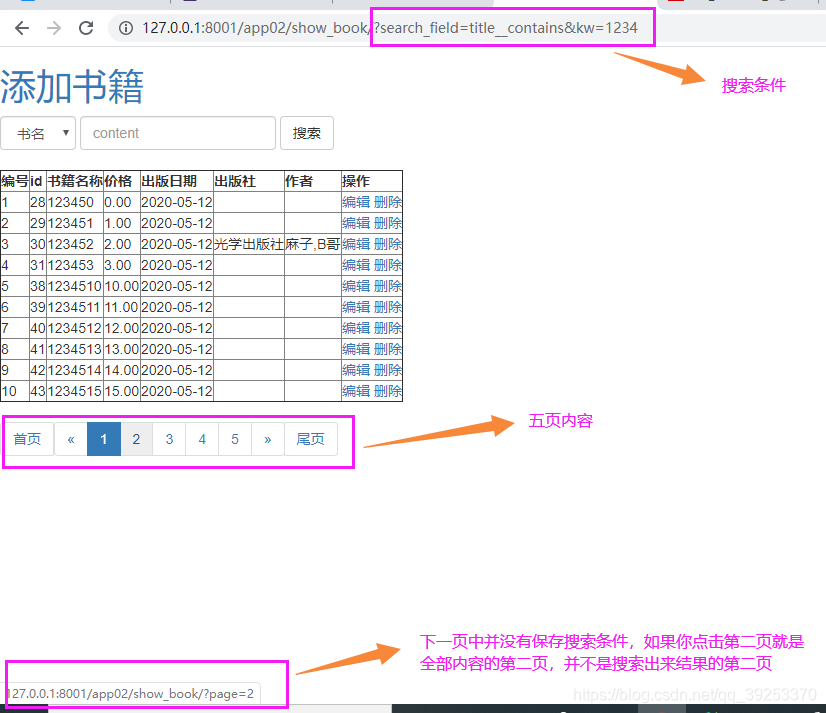
解决办法:
urlencode:会获取查询参数并以&拼接成一个字符串
get_data = request.GET.urlencode()
print(get_data) #结果:search_field=title__contains&kw=123
分页中使用:
for i in page_num_range: #起始页
if self.page_num == i:
page_html += '''<li class="active"><a href="{0}?{1}&page={2}">{3}</a></li>'''.format(self.req_path,self.get_data,i,i)
else:
page_html += '''<li><a href="{0}?{1}&page={2}">{3}</a></li>'''.format(self.req_path,self.get_data,i,i)
这样是解决问题了,但是后面多了很多page:
原因分析:urlencode获取到page之后分页中又拼接了page,这就会你点击一次页码就会在后面添加一个page。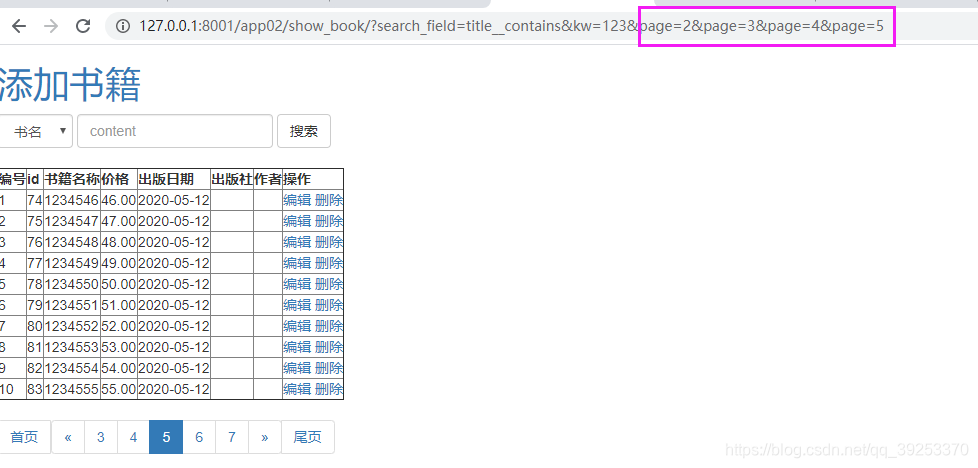
解决办法:
第一种:判断一下如果有page就替换掉
page_html += '''<li><a href="?{0}page={1}">{1}</a></li>'''.format(re.sub(r'page=\d+','',self.get_data) if 'page=' in self.get_data else self.get_data + '&',i)
第二种:将request.GET对象传到分页中
get_data = request.GET
分页中使用的时候添加一个page=当前页,在页码中使用urlencode()
for i in page_num_range:
if self.page_num == i:
self.get_data['page'] = i
page_html += '''<li class="active"><a href="{0}?{1}">{2}</a></li>'''.format(self.req_path,self.get_data.urlencode(),i)
else:
self.get_data['page'] = i
page_html += '''<li><a href="{0}?{1}">{2}</a></li>'''.format(self.req_path,self.get_data.urlencode(),i)
报错:This QueryDict instance is immutable
意思是:这个QueryDict实例是不可变的
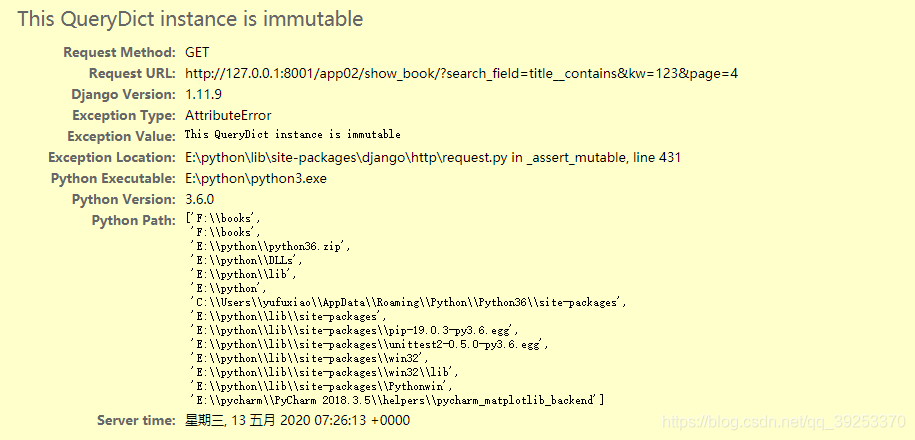
解决办法:
get_data = request.GET.copy()
将request.GET换成request.GET.copy()或者使用copy模块
源码分析:
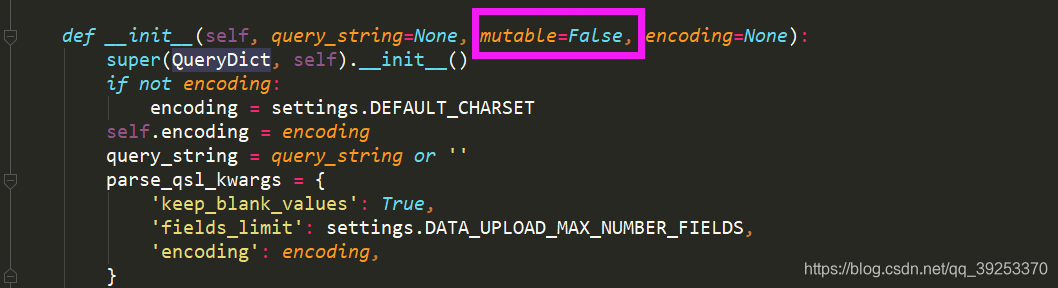
使用copy之后会调用内部的__deepcopy__方法将mutable=True:

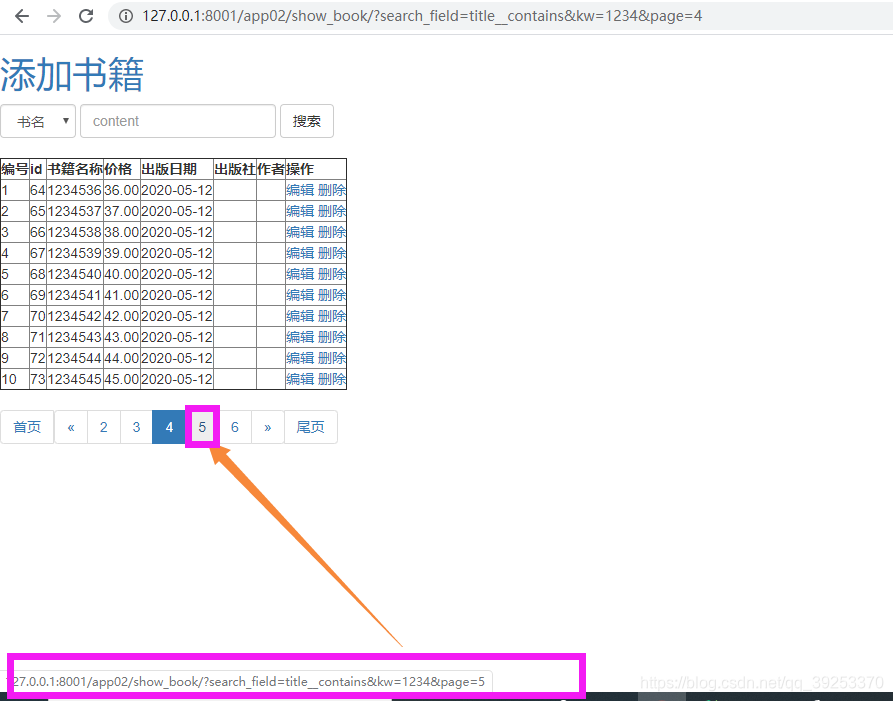
结果,可以看到下一页的页码标签是带有搜索结果的:
续更…