文章目录
主要内容
- Image to Image Translation
1.1. UNIT
1.2. MUNIT - Semantic Segmentation
2.1. AdaptSegNet
2.2. CBST - Person Re-ID
3.1. SPGAN
3.2. ECN
本节内容由助教赵崇皓和杨晟甫讲解。
公式输入请参考:在线Latex公式
1.Image-to-Image translation
1.1UNIT
●Cross-Domain Image Translation
○ Unsupervised Image-to-Image Translation Networks (UNIT)
季节变化

真实转合成

Unsupervised Image-to-Image Translation Networks (UNIT)的特征如下:
●Two distinct domains 两个不同的domain
● Unpaired training data 数据不对应,就是一个domain中图片,没有和他对应的另外一个domain的照片
● Share the same latent space
● Domain Invariant feature

结构就是VAE+GAN

要找到两个domain的share latent space,通过三个方面的loss来进行训练
VAE Loss
在模型的位置如下图红框所示:

VAE就是要使得抽取的特征reconstruction回原输入,输入和输出之间的reconstruction error越小越好,这里用的是L1损失:
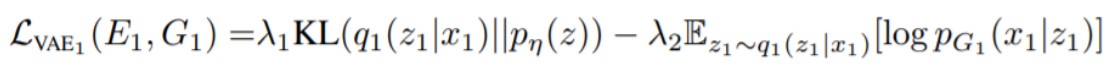
GAN Loss
在模型的位置如下图红框所示:

Discriminator要分辨出影像是哪个Domain的(这里的Domain分为两个:一个是原影像,一个是风格迁移后的)
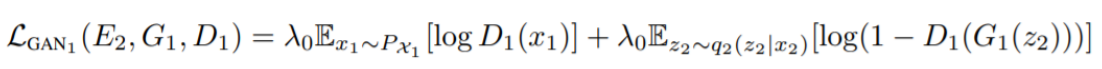
Cycle Consistency Loss
这里Cycle Consistency Loss和CycleGAN类似
第一项在模型的位置如下图红箭头所示:

这一项希望这个Encoder生成的latent space 符合正态分布
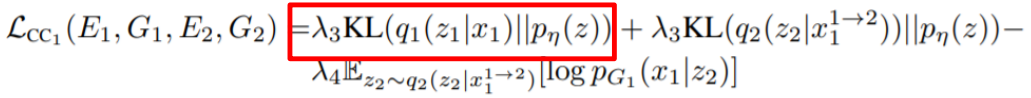
第二项在模型的位置如下图红箭头所示:

将
转换到另外一个domain,得到
经过Encoder得到latent space 符合正态分布
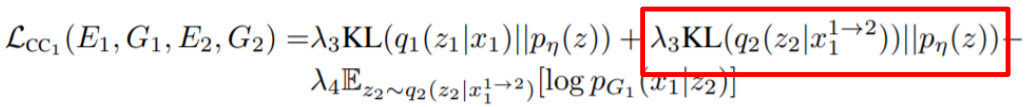
第三项在模型的位置如下图红箭头所示:

这里是
转换为
,然后再从Encoder2得到
,我们希望这里的reconstruction error越小越好。
结果
例如input为白色狗狗,然后风格转成哈士奇和柯基等其他种类的狗,可以看下姿态,舌头,眼神都没怎么变。

1.2MUNIT
Multi-modal Image Translation有两种方法,只讲一种:
○ Multimodal Unsupervised Image-to-Image Translation (MUNIT)
○ Diverse Image-to-Image Translation via Disentangled Representations (DRIT)(这个不讲)
例子:
给左边得右边,反之亦然


MUNIT特点
● Two distinct domains (Diverse image)
● Unpaired training data
● Disentangle features into content and style features
这里的content可以看做是姿态或者是类别
style可以看做是外表


MUNIT架构
有两个Encoder,分别提取Content Feature和Style Feature,然后把它们结合,结合后做up-sampling,还原得到Reconstructed image

涉及到的loss有两块:
第一块是:Bidirectional reconstruction loss ,这个loss又分两块:
- Image reconstruction loss:

- Latent reconstruction loss:

这里是用原来的content
加上新的style
,生成新风格的图片,然后重新抽取
,还原回原来的content
第二块是Adversarial loss

用原来的content
加上新的style
,生成新风格的图片,要骗过Discriminator。
结果

2. Semantic Segmentation
就是要对像素进行标签,在Semantic Segmentation做Domain Adaptation的用途有两个方面,第一,由于直接在真实场景进行像素级别的label是非常麻烦的,可以用虚拟的游戏场景来训练,然后迁移到真实场景;第二,可以从亚洲风格的街景迁移到其他地域的街景。
● Unsupervised Domain Adaptation
○ Learning to Adapt Structured Output Space for Semantic Segmentation (AdaptSegNet)
○ Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training (CBST)

2.1. AdaptSegNet
特点:
● Two distinct domains (Syntheic vs Real)
● Only source domain has labeled data
● Structured output share many similarities
下图是GTA 5的场景和真实场景的对比。

AdaptSegNet架构
分别对source domain和target domain进行Segmentation预测

对于source domain而言,由于有label,可以计算预测结果与真实label的交叉熵:
Segmentation Loss:
Target domain没有标签,因此用GAN的思路来做loss
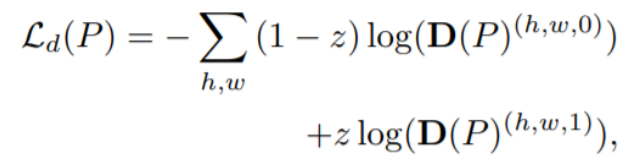
其中:z = 0: target domain
z = 1: source domain
结果

2.2. CBST
特点:
● Two distinct domains (Syntheic vs Real)
● Only source domain has labeled data
● Iterative self-training (pseudo label)创新点
Self-Training
-
Propose pseudo label
先用Source domain的图片来训练我们的模型,训好之后,把Target Domain的图片丢进去,然后得到一系列的预测结果(右下角),然后将结果中比较可信的部分设置为pseudo label。
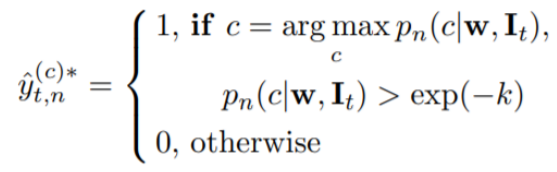
-
Optimize Objective function
这里就是根据pseudo label做supervisor learning。


Propose pseudo label
把Target Domain的图片丢进训练好的模型,然后得到一系列的预测结果,例如下面是两个pixels的预测结果。

● Append the highest probability among softmax output into an array
将分类结果中概率最高的丢进数组中,并排序
● Sort the array
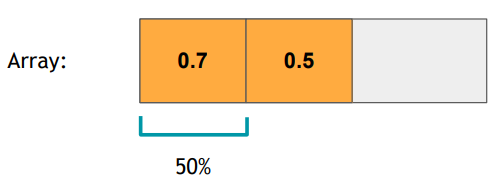
按照一个阈值将高于阈值的结果做为pseudo label,每一轮训练阈值可以取不一样,开始取低一点(0.2表示取数组中前20%的结果)
● Select the (len(array) * p%)th’s largest probability as k
代码描述:

Optimize Objective function
● Source domain: Cross Entropy with ground truth
● Target domain: Cross Entropy with pseudo label
L1 regularization: prevent ignoring all pseudo-labels加这个正则项是为了防止模型抛弃pseudo-label
Class-balanced self-training (CBST)
在图片中一些经常出现的物体,例如行人,汽车,道路等很容易被识别出来,一些不常见的物体,类似垃圾桶、飞机等,出现概率比较低,那么在使用上面的算法的时候就不容易识别出来,因此,我们对算法进行改进,按类来取阈值。这个方法的名字就是:Class-balanced self-training (CBST)
下图中右边是CBST。

可以看到CBST后,dog的概率变高了,最后得到每个分类的各自的取值:

Spatial Priors
另外一个trick就是说在训练自动驾驶任务的街景图像处理的时候,一般而言,汽车是行驶在路上看到的图片中,各个物体会有大概的固定分布,例如建筑物、围墙一般在道路两边,路在中间。
也就是说不同的类别物体会有一个固定的先验空间分布。使用这个分布作为pseudo label的参照,例如建筑物不会出现在中间下方,除非是车祸。
Different classes have different prior distributions.

Softmax output multiplies spatial prior (范围:0~1)

Summary
● Self-Training Scheme
● Each class has unique threshold to determine its pseudo labels
● Incorporate with spatial priors
结果:
不同颜色代表的类别:


3. Person Re-ID
主要讲两篇文章:
○ Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person reidentification (SPGAN)
○ Invariance matters: Exemplar memory for domain adaptive person re-identification (ECN)
先给出Person Re-Identification的概念:
就是根据Query图片从Gallery中找到是同一个人的图片。
3.1. SPGAN
该算法主要是用在摄像头监控上,我们知道,监控一般会有多个,每个拍摄的角度,场景不一样,光线,甚至摄像头的分辨率(品牌或型号)不一样,对所有的摄像头的照片数据做标记是非常困难的,这个算法的思想是某个摄像头的图片有label,通过对其的学习,能用到另外一个摄像头的图片上(无label)。
● Two distinct domains (Market vs Duke,这两个是不同dataset)
● Only source domain has labeled data
● Self-Similarity and Domain-Dissimilarity

整体构架如下:

分为CycleGAN 和SiaNet
CycleGAN
Adversarial loss:主要是能够分辨出是哪个domain的图片。
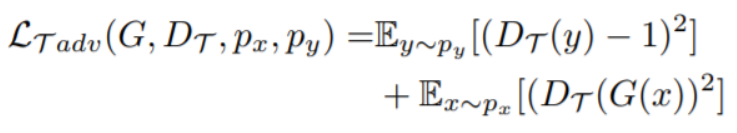
Cycle-Consistent loss :主要是从Source domain转换到target domain要能够还原Source domain,还原后的reconstruction error越小越好,反之亦然。
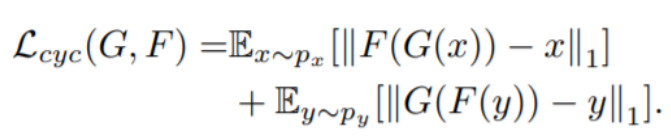
Target domain identity constraint:这里的没听懂,貌似和上面类似,但是是target domain转换后还原回来一定要是其本身的一个约束。
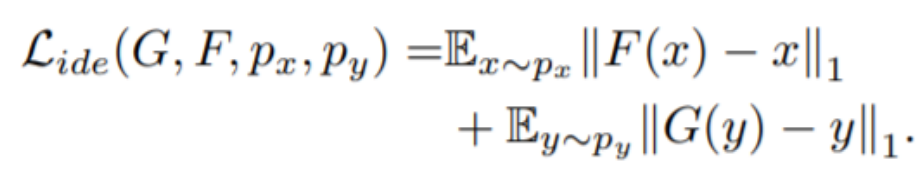
SiaNet
contrastive loss:相同的人要是相同的,不同的人要更加不同(有点绕)

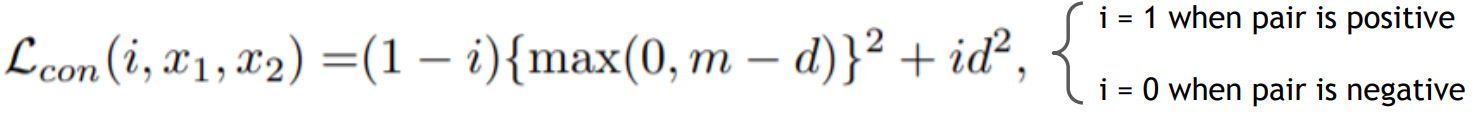
结果:

3.2. ECN
● Two distinct domains (Market vs Duke)
● Only source domain has labeled data
上面条件和上个算法一样
● 创新:Intra-domain variation (Three kinds of invariance)三个invariance见下图:



整体构架:

Source Domain
○ Cross-Entropy Loss
因为有label,所以算交叉熵很简单:
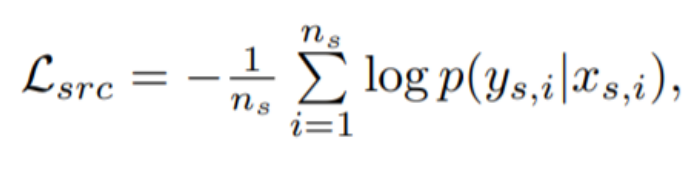
具体见整体构架的红色箭头。
Target Domain
○ Exemplar Memory:Each image is one class
由于Target Domain没有label,我们不知道每个图片对应哪个类别,因此,作者假定每个图片就是一个类别:

Exemplar-invariance
由于每张图片都是独自一个类别(class),那么在分类的时候就是自己和自己最像,和其它都越不像越好。
■ close to itself while far away from others
■ learn apparent representation


Camera-invariance
■ an image and its camera-style transferred counterparts should be close to each other


这一项有点类似StarGAN,不同型号或者位置的摄像头拍摄到的同一对象有区别,但是还是同一对象,如下图中,红衣女子和红衣女子的图片是相同的,而与其它人不同。

Neighborhood-invariance
■ Exploit positive pairs
■ Soft-label loss
把相近的类进行聚合,归为同一对象。


可以看到第一个和第三个invariance是互相矛盾的,要做trade-off
:
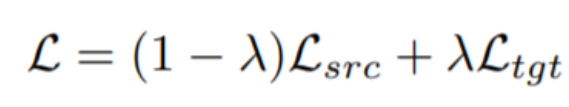
总结本节的Common Trick
● Disentangled Representation -> Interpretable, Controllable
● Adversarial Training -> Domain Invaraint Feature
●Minimize source and target domain’s discrepancy->similarity, share latent space
● Propose pseudo labels
Reference
● Liu, Ming-Yu, Thomas Breuel, and Jan Kautz. “Unsupervised image-to-image translation networks.” Advances in neural information processing systems. 2017.
● Huang, Xun, et al. “Multimodal unsupervised image-to-image translation.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
● Tsai, Yi-Hsuan, et al. “Learning to adapt structured output space for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
● Zou, Yang, et al. “Unsupervised domain adaptation for semantic segmentation via class-balanced self-training.” Proceedings of the European conference on computer vision (ECCV). 2018.
● Deng, Weijian, et al. “Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
● Zhong, Zhun, et al. “Invariance matters: Exemplar memory for domain adaptive person re-identification.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.