作为刚毕业不到一年的数据产品经理,今天和大家分享一下我接触到和认知范围内的数据产品经理关于数据指标标签体系的构建过程是什么样子的
1、解读数据库数据
①在我们公司(家居互联网行业),我们作为数据部门,能够查看公司全部的数据,所以我们日常会接收到来自其他部门的提数申请,有简单的导出关于家居行业中设计方案的素材的使用情况、也有需要我们经过数据加工分析后的数据分析表等,说这个不是想说我们日常工作只是提数分析,而是想说,在一个数据中台和业务中台还没成体系化的公司中,开放这样一个数据出口,能够让我们快速接触到各条业务线中对于数据的需求情况,以及各业务线关注的业务信息。
②通过自己试用期期间的业务积累,当然不当当通过上面的提数通道了解到的,以及每次数据需求的积累,给我最大的感受就是:作为试用期的数据产品经理,最需要的就是对公司底层数据的熟悉度,已经能够运用sql查询出业务方所需要的数据,并能在excel进行分析。
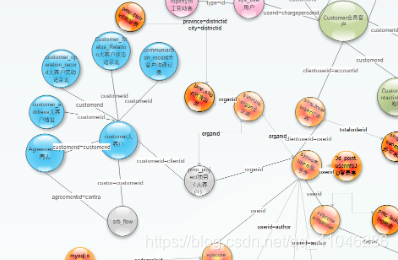
③回顾自己对解读数据库数据的认知经历,大概就是:业务需求->业务对应的数据库是什么->不同库之间是怎么关联的,包括业务关联和字段关联->该库里面存放的表的业务是什么->表里面的字段含义是什么。对于前部分的业务和数据库、数据库和数据库之间的关联,在我入职时去年的师姐已经整理好了好几份比较详细的文档,我觉得这样的数据逻辑图非常重要,非常能够辅助我快速认知业务关系和数据库关系,样例如下图:
2、解读业务需求
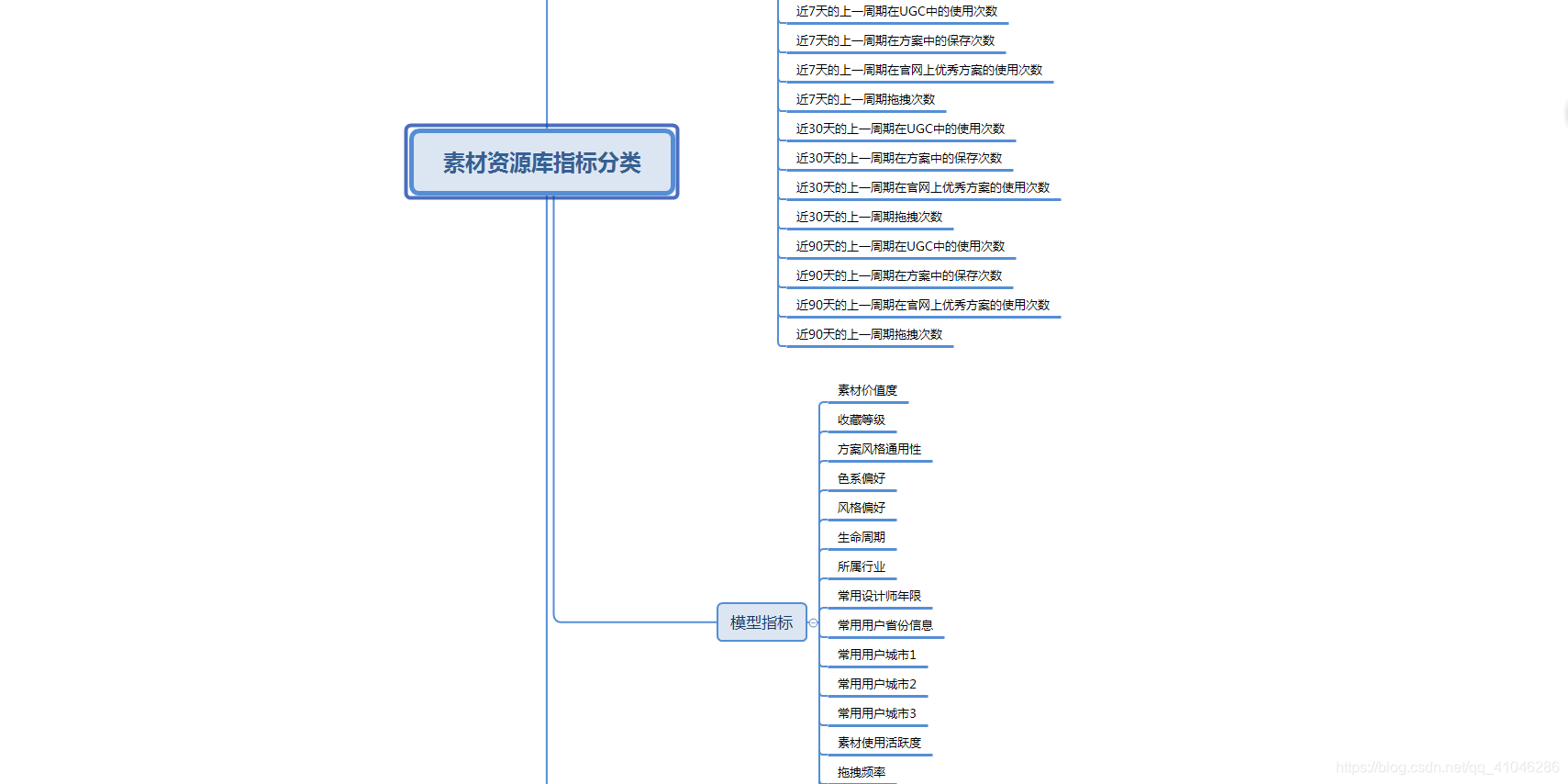
通过试用期期间对底层数据有了很好的认知之后,这里的很好认知我认为至少是你知道大部分数据库都是存放什么样子的业务数据,每个库里面经常用的表有哪些,这些表里面那些字段是比较常用的,并能够在不看相关的解释文档的前提下,运用sql快速查找出你想要的数据。有了数据认知后,我觉得对自己核心竞争力有帮助的不是你对底层数据的了解情况,更重要的是你能够把你接触到的数据需求汇总成为具体的业务共性,就比如:常用部门想知道某些东西的拖拽频率、使用频率。但他们的最终需求都是想要把更好的东西推荐给用户,这就是一个共性的东西,而作为数据产品经理,就是需要把这些共性的需求聚合成为整个能够指导业务发展的东西,并用相关的指标标签进行描述。下面这个是之前的一个项目中构建的一些指标标签的部分截图:
3、指标逻辑实现
①构建完相关业务的指标标签体系之后,就是又要回归底层数据了。像我之前做的项目,我们所有新构建的指标和标签,都是需要通过大数据部门,重新建立新的数据库和数据表,因此我们需要对每个字段的源数据逻辑和数据聚合逻辑进行详细的中文说明和sql说明,一方面是便于大数据进行开发建表,另一方面是方面后面内容推出后,其他部门的人对我们东西使用的方便性。在这个过程中,我才后知后觉原来数据产品已经是半个开发了,不仅要梳理底层指标sql,对于可视化在BI界面上面的sql也要我们来梳理。但是有个好处就是,作为数据产品,我暂时还不需要考虑到sql的效率问题,因为我们的sql只是辅助大数据的人员理解指标和标签,他们在新建表的时候会对你的sql进行优化提升。
②为了方便指标的实现,前期还是需要做很多相关的整理工作的,比如对指标进行分类整理,因为你不可能把所有的指标标签都建在一张表里面,所以还需要了解一下建表的一些简单事项,比如标关联、索引等,比如要是大数据的小伙伴人比较好的话,会帮你一起想这些东西。这里说下指标和标签的区别,指标可能就是最基础,常用用户认知的,比如使用量,近七天活跃这些,但是标签是对这些进行分层处理,比如使用量,那多少时高,多少是低,可能你就需要通过聚类算法,构建出一个能够衡量高低的定义了。比如我当初构建的其中一个标签:素材价值度,通过对历史使用数据的聚类分析,后面构建出的公式和定义为:
价值度划分=>划分为五个等级:一星-两星-三星-四星-五星
价值量=搜索次数0.3+在优秀方案中使用次数0.4+收藏数*0.3
一星:价值量=0
二星:0<价值量<=1.5
三星:1.5<价值量<=10
四星:10<价值量<=40
五星:价值量>40
接下来讲下指标标签的具体实现过程,这里我会拿一些例子来做解释,主要是讲解一下sql的实现,当然,其实我自己的sql也不是很好,但是我觉得够用就行,能够满足自己日常业务工作的数据提取需求,很多函数都是在业务中在慢慢去百度查找。之前的项目我是把全部构建的指标和在BI上面可视化的逻辑分成了五个表,下面只对部分进行说明:
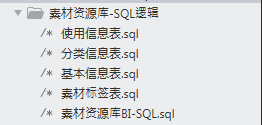
数据逻辑分层表
①基本信息表中:主要是对一些不可或缺的字段的直接迁移,因为不管构建什么样子的标签,有些基本属性是不可或缺的,所以这一块 的逻辑一般是比较简单的,一般是直接从源库中把字段提取出来就行。这里有个建议就是:竟然我们的逻辑是写给大数据开发看的,所以就尽可能的解释的详细,可以减少很多后面的沟通工作
#素材的基本信息#
#放置位置:pmc.designmaterial#
#字段:素材名称-素材id-素材url-上传时间-上传人员-上传部门-上传机构-产品id#
#是否在3D中-是否公用-是否可渲染-素材标志-材质属性-使用区域#
#-素材是否有商品-零售价格-批发价格-成本价格-搭配组合内容-放置规则-素材颜色-是否关联到组合#
select materialid,materialname,imagepath,posttime,author,deptid,organid,
productid,IS3D,ispublic,isrender,modelflag,property,usearea,
ishasproduct,retailprice,wholesaleprice,costprice,placeheight,placerule,color,isrelate
from pmc_kudu.designmaterial
②使用信息表中:主要是对一些常用的使用情况进行统计,因为有很多业务部分会经常想知道某些商品素材的七天使用情况、30天使用情况、收藏情况等等,每次我们查询的时候都需要关联很多表才能够查出来,效率非常低下,所以就考虑直接构建相关字段,便于后面查找。当然,这里不是说想构建啥就能构建啥的哈,因为每个字段后台每天都回去更新,都会消耗服务器资源的呀,而且后面项目结束时,所有构建的字段都需要有合理的解释,说明你构建的意义的。所以还是回归产品的初心,做什么都要讲价值。
#以下的使用信息都只统计一个时间段,其他时间段的只要改变时间信息就可以#
#统计素材的拖拽信息,近30天拖拽次数#
select materialid,sum(dragTimes) as darg_cnt30,substr(sendtime,1,10) as nowtime from 3D_point_kudu.materialDragInfo
where datediff(now(),sendtime )<=30
group by materialid,substr(sendtime,1,10)
#统计素材在UGC中的使用次数,近30天#
select a.materialid,sum(a.dragtimes) as use_yx_cnt30,a.nowtime from
(select materialid,dragtimes,schemeid,substr(sendtime,1,10) as nowtime from 3D_point_kudu.materialInfo
where datediff(now(),sendtime )<=30)a
left join
(select id,scheme_name from ugc_scheme_kudu.home_scheme)b
on a.schemeid=b.id
group by a.materialid,a.nowtime
③标签表:标签表是构建指标标签的核心,因为这里的所有标签的合理程度一定要明确,而且逻辑一定要说得通,要不很容易别人就质疑你构建的标签合不合理或者必不必要。特别是用了相关数据挖掘的东西的话,也需要做相关的技术说明。我觉得构建标签也是最难的一块,当你对业务认知不深的时候,你所构建的标签所描述的东西就很浅,这也是我在做完这个项目后一直在思考的问题。但是东西总是循序渐进的,那时候的自己也懂的很少。所以我建立以后再做相关的数据产品时,一定要多调研,不管是对自己公司内部的还是对公司外部竞品相关的,都要有足够的认知。还有就是标签的sql逻辑一般比较复杂,当初有好几个都是我中文描述逻辑,然后让同组的小伙伴帮忙写的,还好她们人都比较好,所以我学的sql很多也是她们教我的,还是挺感谢的。下面就只举两个标签吧,偷偷说下,查询效率超级低,要跑很久才能跑出数据哈哈,不过大数据的小伙伴会帮你优化的,不用管那么多。
--1、素材价值度
#价值度划分=>划分为五个等级:一星-两星-三星-四星-五星#
#字段名:active_value#
#价值量=搜索次数*0.3+在优秀方案中使用次数*0.4+收藏数*0.3
#一星:价值量=0
#二星:0<价值量<=1.5
#三星:1.5<价值量<=10
#四星:10<价值量<=40
#五星:价值量>40
select z.materialid,
case when (isnull(z.sc_cnt,0)*0.3+isnull(h.ss_cnt,0)*0.3+isnull(y.yxsy_cnt,0)*0.4)=0 then '一星'
when (isnull(z.sc_cnt,0)*0.3+isnull(h.ss_cnt,0)*0.3+isnull(y.yxsy_cnt,0)*0.4)>0 and (isnull(z.sc_cnt,0)*0.3+isnull(h.ss_cnt,0)*0.3+isnull(y.yxsy_cnt,0)*0.4)<=1.5 then '两星'
when (isnull(z.sc_cnt,0)*0.3+isnull(h.ss_cnt,0)*0.3+isnull(y.yxsy_cnt,0)*0.4)>1.5 and (isnull(z.sc_cnt,0)*0.3+isnull(h.ss_cnt,0)*0.3+isnull(y.yxsy_cnt,0)*0.4)<=10 then '三星'
when (isnull(z.sc_cnt,0)*0.3+isnull(h.ss_cnt,0)*0.3+isnull(y.yxsy_cnt,0)*0.4)>10 and (isnull(z.sc_cnt,0)*0.3+isnull(h.ss_cnt,0)*0.3+isnull(y.yxsy_cnt,0)*0.4)<=40 then '四星'
when (isnull(z.sc_cnt,0)*0.3+isnull(h.ss_cnt,0)*0.3+isnull(y.yxsy_cnt,0)*0.4)>40 then '五星'
end as active_value
from
(
--统计素材的收藏次数,没有时间信息#
select c.materialid,d.collectcount as sc_cnt from
(select materialid,materialname from pmc_kudu.designmaterial)c
left join
(select materialid,collectcount from pmc_kudu.modelcollectext)d
on c.materialid=d.materialid
)z
left join
(--统计素材在优秀方案总的使用次数,近30天#
select a.materialid,sum(a.dragtimes) as yxsy_cnt from
(select materialid,dragtimes,schemeid from 3D_point_kudu.materialInfo
where datediff(now(),sendtime )<=90)a
inner join
(select id,scheme_name from ugc_scheme_kudu.home_scheme)b
on a.schemeid=b.id
group by a.materialid
)y
on z.materialid=y.materialid
left join
(--统计被搜索次数
select d.materialid,a.cnt as ss_cnt from pmc_kudu.designmaterial d
left join
(select value,count(uuid) cnt from 3d_point_kudu.datainfo
where value in (select materialid from pmc_kudu.designmaterial) and datediff(now(),sendtime )<=90
group by value)a
on d.materialid = a.value
)h
on z.materialid=h.materialid
--20、优推指示
#字段名:advantage_level
#一级指示(近7天都被拖拽)-二级指示(近14天都被拖拽)-三级指示(近21天都被拖拽)-四级指示(近28天都被拖拽)-五级指示(近35天都被拖拽)
select materialid,
case when max(cnt)=7 then '一级指示'
when max(cnt)=14 then '两级指示'
when max(cnt)=21 then '三级指示'
when max(cnt)=28 then '四级指示'
when max(cnt)=35 then '五级指示'
end as advantage_level
from (
select materialid,count(distinct substr(sendtime,1,10)) as cnt from 3D_point_kudu.materialDragInfo
where datediff(now(),sendtime )<=7 group by materialid having count(distinct substr(sendtime,1,10))=7
union all
select materialid,count( distinct substr(sendtime,1,10))as cnt from 3D_point_kudu.materialDragInfo
where datediff(now(),sendtime )<=14 group by materialid having count(distinct substr(sendtime,1,10))=14
union all
select materialid,count( distinct substr(sendtime,1,10))as cnt from 3D_point_kudu.materialDragInfo
where datediff(now(),sendtime )<=21 group by materialid having count(distinct substr(sendtime,1,10))=21
union all
select materialid,count( distinct substr(sendtime,1,10))as cnt from 3D_point_kudu.materialDragInfo
where datediff(now(),sendtime )<=28 group by materialid having count(distinct substr(sendtime,1,10))=28
union all
select materialid,count( distinct substr(sendtime,1,10))as cnt from 3D_point_kudu.materialDragInfo
where datediff(now(),sendtime )<=35 group by materialid having count(distinct substr(sendtime,1,10))=35
)a
group by materialid
4、可视化产品
经过上面的指标和标签逻辑梳理后,就是要可视化成数据产品了。在对于一个数据中台还很不完善的公司来说,要想让别人看到我们的价值,最好的方式就是拿出实际的产品出来,因此作为数据产品,我们需要想数据将构建的指标和标签通过业务方所需要的方式进行可视化,而且数据产品和传统的产品有很大的不同,在我认为哈,就是我们的数据产品面向的群里是很分散的,因此我看可视化的东西要很有共性并能够满足绝大部分的需求,而且数据产品最注重的就是逻辑性,这点也是我现在在不断学习的。这里涉及到相关隐私问题,就不把我们最后实现的产品放出来了哈。
5、对外输出
通过这段时间的工作,我深深感受到对外输出的重要性,需要准备好相对应的材料,而且一定要让别人看到你的专业性,因为其实公司很多人都不知道你的水平,你只有准备的足够充分,东西做的足够好,他们才会感受到你的专业性,才会认同你。像我们当初的上线会发很正式的邮件,画出对应的逻辑图,我觉得当初画的这个还挺好看的哈哈

最后,这篇文章是基于我毕业不到一年的认知所写的,有写得不对的地方欢迎和我交流。因为自己认识的做数据产品经理的朋友也比较少,不太清楚别人的数据产品经理是什么样子的。所以有想一起学习成长的朋友可以加个qq:624488342 ,一起交流沟通哈!