1 加深和加宽的对比
1.1 网络加深,有助于提升模型性能
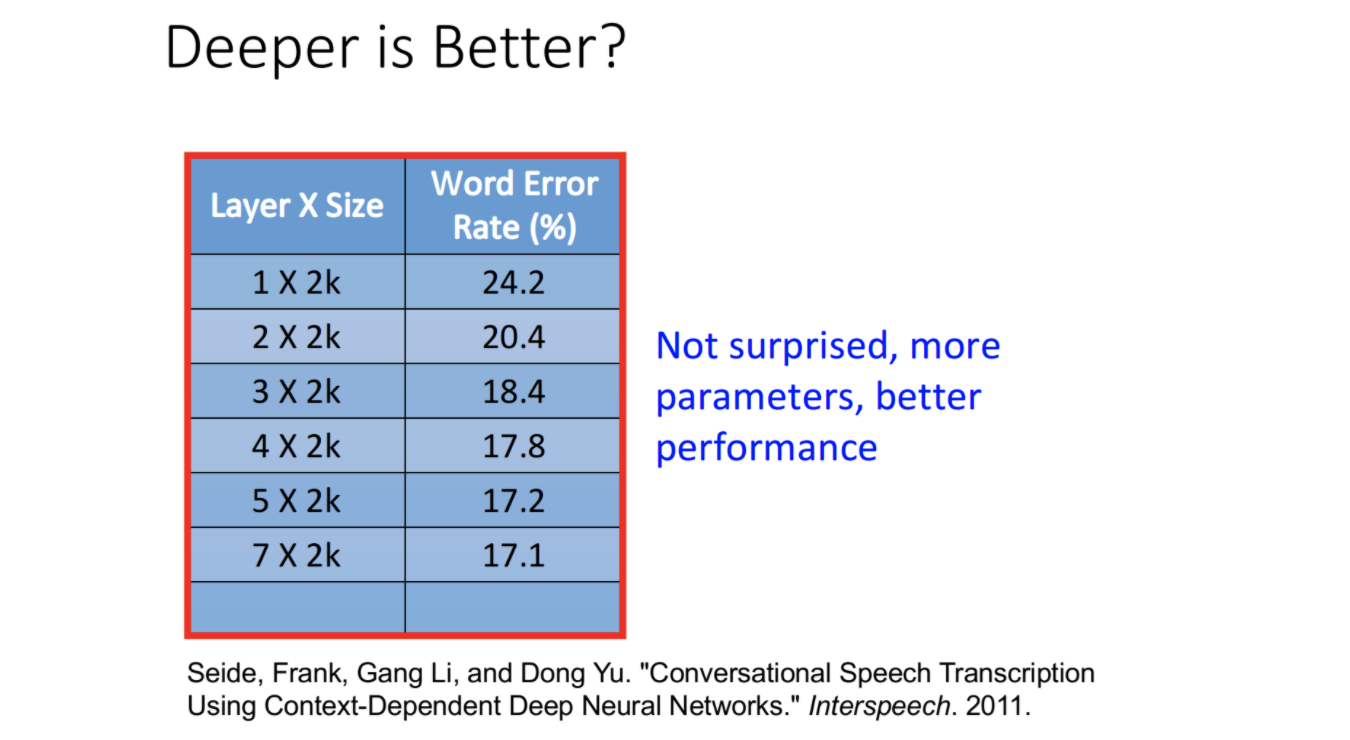
很早以前就有人研究过模型加深加宽的作用。由上图可见,随着模型越深,错误率逐步下降。这个其实很好理解,可能有人会问,模型加深带来了模型参数量的提升,有助于bias降低。通过增加训练数据和各种正则,可以降低variance。从而降低整体的误差。
1.2 加深和加宽的对比
那加深是不是仅仅就带来了模型复杂度和拟合能力的提升呢?所以研究人员也做了模型加深和加宽的对比。在相同参数量(不代表神经元个数相同)情况下,加深的效果是远远好于加宽的。如下
深度5层,宽度2k的模型,和深度1层,宽度3772的模型,参数量大体一致,但错误率小很多。甚至两层2k的模型,在参数量小很多情况下,性能比单层16k的模型还要好。从上可见,加深效果比加宽要好的。所以模型加深绝对不是仅仅带来复杂度和拟合能力的提升。
那为什么模型加深这么有用呢?加深又带来了哪些能力的提升呢?
2 模型加深的作用
2.1 提升模块化能力
深度模型DNN一个比较大的优势就是,Modularization模块化。每个神经元都可以想象成是一个特征分类器,浅层的输出可以给深层的多个神经元重复使用,从而提升了模块化能力和复用能力,提升了参数的效率。如下
理解起来还是比较晦涩,看一个例子。我们现在有一个分类任务,共4个类别,长头发女生、长头发男生、短头发女生、短头发男生。如果只使用单层DNN,原始图片直接通过单层神经元,就得到输出结果。
如上所示,图片直接通过单层神经元(看作是弱分类器)进行分类,每个神经元负责一个类别。如果数据量足够大,倒是马马虎虎还可以。但长头发男生这个类别,数据量很少。这就会导致classifier2得不到充分训练,性能很差。
那我们现在来看看换成多层DNN后的效果。多层DNN将任务划分为了两个子分类
- 男生或女生
- 长发或短发
通过浅层分类和特征提取,在深层进行融合,从而最终得到输出类别。划分为子问题会带来一个比较大的好处,一方面降低了分类难度,另一方面两个子分类任务数据量都足够。浅层的神经元是模块化的,可以被深层的多个神经元重复利用,从而提升了参数效率。
2.2 提升Transform变换能力
神经网络的每个神经元,通过w * x + b,可以对输入特征进行线性变换。浅层的变换可以被深层使用。故网络层数加深,可以带来变换次数的提升,从而提升变换能力。下面是手写字识别,不同layer特征的分布。可以看出随着层数越深,输出特征区分度越来越大。这就是因为层数越深,特征变换能力越强的原因。
如上图,4和9在输入层和layer1中,很难区分出来。因为他们两个确实比较接近。但随着layer加深,特征变换次数增多,它们区分度也越来越高。
2.3 end2end 端到端
端到端是现在提得很多,深层DNN一个很大的优势就是可以端到端。使用多个模型串联,而不是端到端,缺点有
- 误差会级联,下游模型受上游模型干扰特别大
- 模型之间是割裂的,无法联合起来调参。
- 设计多个模型,甚至需要一定背景知识,工作量大。
而深度神经网络则可以实现端到端。但在特别复杂的任务中会有训练难度大、可解释性差、不容易规则干预、可控性差的问题。此时我们会倾向于使用串联子模型来上线。但最终还是会朝端到端努力的。这在taskBot中就是一个典型例子。
3 加深的挑战
从上面三点可知,神经网络需要加深。甚至有人说,在能力范围内,尽量深。CV领域Resnet有人做出了1000多层,NLP领域Transformer也是比之前的常用的LSTM加深了很多倍。模型加深是大家普遍认知。那为啥不做特别特别深的模型呢。主要原因有
- 加深容易导致梯度弥散和梯度爆炸问题。梯度爆炸还好处理,通过clip可以解决。梯度弥散则容易导致反向传播时,级联的梯度越来越小,传播到浅层后就几乎为0,从而导致学习特别慢,甚至无法更新参数并学习了。
- 不同layer无法并行计算,导致前向计算比较慢,降低了模型预测和训练速度。
- 训练时,由于反向传播,必须保存所有layer的输出,内存消耗也比较大。不过这个有一些解法,比如Reformer利用时间换空间,优化了这个问题。