Python黑帽第二篇文章将分享Python网络攻防基础知识,看看Python能做什么,以及正则表达式、网络爬虫和套接字通信入门基础。本文参考了i春秋ADO老师的课程内容,这里真心推荐大家去学习ichunqiu的课程,同时也结合作者的经验进行讲解。希望这篇基础文章对您有所帮助,更希望大家提高安全意识,也欢迎大家讨论。
娜璋AI安全之家于2020年8月18日开通,将专注于Python和安全技术,主要分享Web渗透、系统安全、CVE复现、威胁情报分析、人工智能、大数据分析、恶意代码检测等文章。真心想把自己近十年的所学所做所感分享出来,与大家一起进步。
声明:本人坚决反对利用教学方法进行恶意攻击的行为,一切错误的行为必将受到严惩,绿色网络需要我们共同维护,更推荐大家了解技术背后的原理,更好地进行安全防护。虽然作者是一名安全小白,但会保证每一篇文章都会很用心地撰写,希望这些基础性文章对你有所帮助,在安全路上一起前行。
文章目录
一.为什么使用Python做网络攻防
首先,你需要了解网络攻防的七个基础步骤。
- 侦查: 漏洞挖掘
- 武器制作: 攻击、载荷
- 分发: 垃圾邮件等
- 利用: 漏洞利用
- 安装: 恶意代码、网页
- 远程控制: 僵尸网络
- 行动: 窃密、破坏、跳板
下图是ATT&CK框架,包括12个步骤。

其次,为什选择Python作为开发工具呢?
真正厉害的安全工程师都会自己去制作所需要的工具(包括修改开源代码),而Python语言就是这样一个利器。Python开发的平台包括Seebug、TangScan、BugScan等。在广度上,Python可以进行蜜罐部署、沙盒、Wifi中间人、Scrapy网络爬虫、漏洞编写、常用小工具等;在深度上,Python可以实现SQLMAP这样一款强大的SQL注入工具,实现mitmproxy中间人攻击神器等。由于Python具有简单、易学习、免费开源、高级语言、可移植、可扩展、丰富的第三方库函数特点,Python几行代码就能实现Java需要大量代码的功能,并且Python是跨平台的,Linux和Windows都能使用,它能快速实现并验证我们的网络攻防想法,所以选择它作为我们的开发工具。
那么,我们又可以用Python做什么呢?
- 目录扫描:Web+多线程(requests+threading+Queue)、后台敏感文件(svn|upload)、敏感目录(phpmyadmin)。
- 信息搜集:Web+数据库、中间件(Tomcat | Jboss)、C段Web信息、搜集特点程序。例如:搜索某个论坛上的所有邮箱,再进行攻击。
- 信息匹配&SQL注入:Web+正则、抓取信息(用户名|邮箱)、SQL注入。
- 反弹shell:通过添加代码获取Shell及网络信息。
最后,建议读者做好以下准备。
- 选择一个自己喜欢顺手的编辑器
- 至少看一本关于Python的书籍
- 会使用Python自带的一些功能,学习阅读开源代码
- 阅读官方文档,尤其是常用的库
- 多练习,多实战
下面举个简单Python示例,通过import导入扩展包base64,它是将字符串base64加解码的模块, 通过print dir(base64)、help(base64)可以查看相关功能。
# -*- coding: utf-8 -*-
import base64
print dir(base64)
print base64.__file__
print base64.b64encode('eastmount')
输出结果如下图所示,包括查看源代码文件位置和“eastmount”转码。

接下来我们开始学习Python正则表达式、Python Web编程和Python网络编程。
二.Python正则表达式
(一) 正则表达式基础
在使用正则表达式之前,我们需要基本了解Python基础知识、HTTP协议,熟悉使用BurpSuite、SQLMAP工具。Python正则表达式被广泛应用在爬虫开发、多线程、网络编程中,而hacker应用也会涉及到正则表示式相关知识,比如扫描、爆破、POC等。
正则表达式(RegEx)使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。 例如,如果想获取里面的ip地址,就需要使用正则表达式实现。Python通过re模块提供正则表达式的支持,其基本步骤如下:
- 先将正则表达式的字符串形式编译我Pattern实例(compile)
- 使用Pattern实例处理文本并获得匹配结果(match find findall)
- 使用实例获得信息,进行其他的操作( 匹配结果)
举一个简单例子:
import re
pattern = re.compile('east')
match = pattern.match('eastmount!')
print(match.group())
word = re.findall('east', 'east mount')
print(word)
输出结果为:
- east
- [‘east’]
点(.)表示匹配任意换行符“\n”以外的字符。
import re
word = "http://www.eastmount.com Python_9.29"
key = re.findall('t.', word)
print key
输出结果为:[‘tt’, ‘tm’, ‘t.’, ‘th’],依次匹配t加任意字符的两个字符。
斜杠(\)表示匹配转义字符 如果需要匹配点的话,必须要\转义字符。
import re
word = "http://www.eastmount.com Python_9.29"
key = re.findall('\.', word)
print key
输出结果为:[’.’, ‘.’, ‘.’]。
[…] 中括号是对应位置可以是字符集中任意字符。
字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c],第一个字符如果是^表示取反,如 [ ^ abc]表示不是abc的其他字符。例如:a[bcd]e 能匹配到 abe、ace、ade。
匹配数字和非数字案例。
# -*- coding: utf-8 -*-
import re
#匹配数字
word = "http://www.eastmount.com Python_9.29"
key = re.findall('\d\.\d\d', word)
print key
#匹配非数字
key = re.findall('\D', word)
print key
输出结果如下图所示:
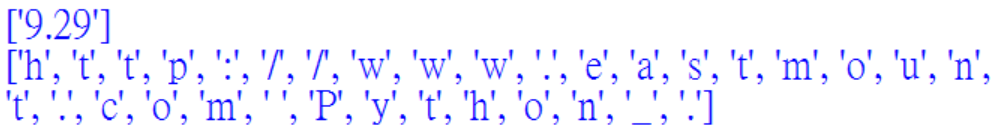
正则表达式较为难理解,更推荐读者真正使用的时候学会去百度相关的规则,会使用即可。同时,更多正则表达式的使用方法建议读者下来之后自行学习,常见表如下图所示。
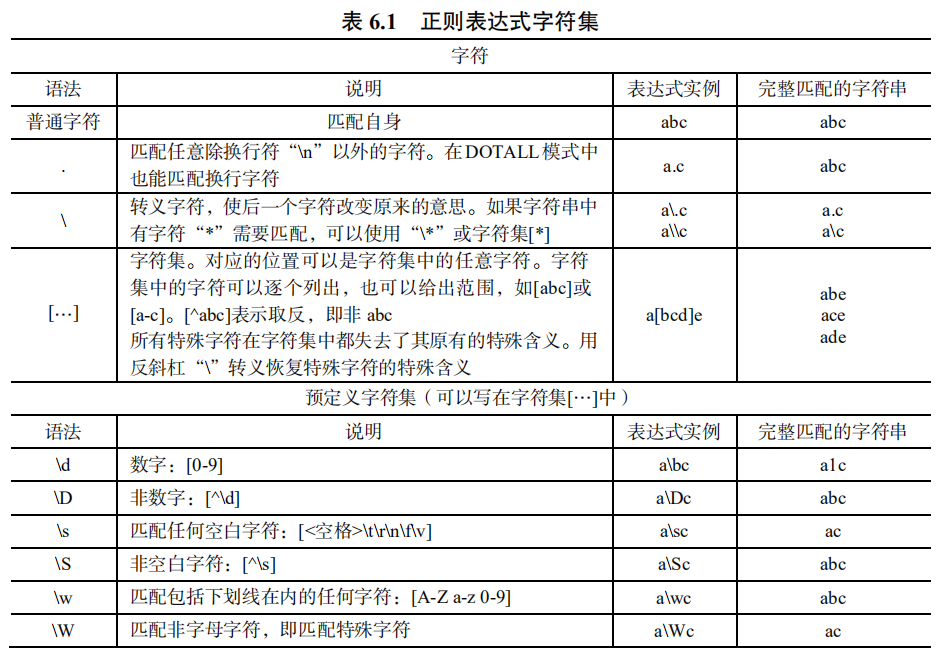
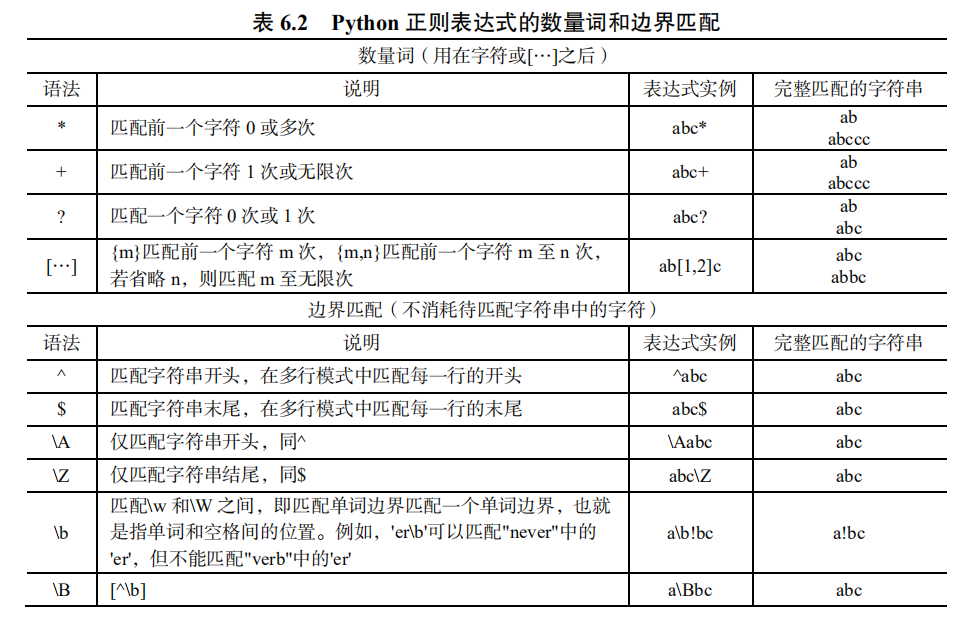
(二) 常用正则表达式规则
下面讲解比较常见的正则表达式规则,这些规则可能会对我们的网络攻防有一定帮助。
1.获取数字
# -*- coding: utf-8 -*-
import re
string="A1.45,b5,6.45,8.82"
regex = re.compile(r"\d+\.?\d*")
print(regex.findall(string))
输出结果为:
[‘1.45’, ‘5’, ‘6.45’, ‘8.82’]
2.抓取标签间的内容
# coding=utf-8
import re
import urllib
html = u'<title>欢迎走进Python攻防系列专栏</title>'
title = re.findall(r'<title>(.*?)</title>', html)
for i in title:
print(i)
输出结果为:

3.抓取超链接标签间的内容
# coding=utf-8
import re
import urllib.request
url = "http://www.baidu.com/"
content = urllib.request.urlopen(url).read()
#print(content)
#获取完整超链接
res = r"<a.*?href=.*?<\/a>"
urls = re.findall(res, content.decode('utf-8'))
for u in urls:
print(u)
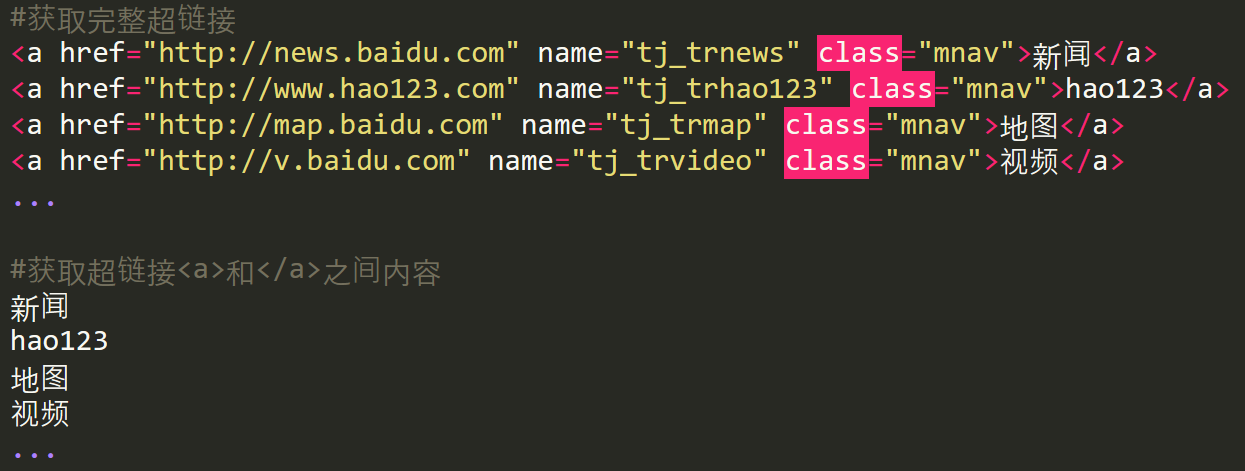
#获取超链接<a>和</a>之间内容
res = r'<a .*?>(.*?)</a>'
texts = re.findall(res, content.decode('utf-8'), re.S|re.M)
for t in texts:
print(t)
输出结果部分内容如下所示,中文编码是常见的问题,我们需要注意下,比如utf-8编码。
4.抓取超链接标签的url
# coding=utf-8
import re
content = '''
<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a>
<a href="http://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a>
<a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图</a>
<a href="http://v.baidu.com" name="tj_trvideo" class="mnav">视频</a>
'''
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
urls = re.findall(res, content, re.I|re.S|re.M)
for url in urls:
print(url)
获取的超链接输出结果如下图所示:

5.抓取图片超链接标签的url和图片名称
在HTML中,我们可以看到各式各样的图片,其图片标签的基本格式为“< img src=图片地址 />”,只有通过抓取了这些图片的原地址,才能下载对应的图片至本地。那么究竟怎么获取图片标签中的原图地址呢?下面这段代码就是获取图片链接地址的方法。
content = '''<img alt="Python" src="http://www.yangxiuzhang.com/eastmount.jpg" />'''
urls = re.findall('src="(.*?)"', content, re.I|re.S|re.M)
print(urls)
# ['http://www.yangxiuzhang.com/eastmount.jpg']
其中图片对应的原图地址为“http://www.xxx.com/eastmount.jpg”,它对应一张图片,该图片是存储在“www.xxx.com”网站服务器端的,最后一个“/”后面的字段为图片名称,即为“eastmount.jpg”。那么如何获取url中最后一个参数呢?
content = '''<img alt="Python" src="http://www..csdn.net/eastmount.jpg" />'''
urls = 'http://www..csdn.net/eastmount.jpg'
name = urls.split('/')[-1]
print(name)
# eastmount.jpg
更多正则表达式的用法,读者结合实际情况进行复现。
三.Python Web编程
这里的Web编程并不是利用Python开发Web程序,而是用Python与Web交互,获取Web信息。主要内容包括:
- urllib、urllib2、requests
- 爬虫介绍
- 利用Python开发一个简单的爬虫
(一) urllib\urllib2
urllib是Python用于获取URL(Uniform Resource Locators,统一资源定址器)的库函数,可以用来抓取远程数据并保存,甚至可以设置消息头(header)、代理、超时认证等。urllib模块提供的上层接口让我们像读取本地文件一样读取www或ftp上的数据。它比C++、C#等其他编程语言使用起来更方便。其常用的方法如下:
urlopen(url, data=None, proxies=None)
该方法用于创建一个远程URL的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。参数url表示远程数据的路径,一般是网址;参数data表示以post方式提交到url的数据;参数proxies用于设置代理。urlopen返回一个类文件对象。
# -*- coding:utf-8 -*-
import urllib.request
url = "http://www.baidu.com"
content = urllib.request.urlopen(url)
print(content.info()) #头信息
print(content.geturl()) #请求url
print(content.getcode()) #http状态码
该段调用调用urllib.urlopen(url)函数打开百度链接,并输出消息头、url、http状态码等信息,如下图所示。

urlretrieve(url, filename=None, reporthook=None, data=None)
urlretrieve方法是将远程数据下载到本地,参数filename指定了保存到本地的路径,如果省略该参数,urllib会自动生成一个临时文件来保存数据;参数reporthook是一个回调函数,当连接上服务器,相应的数据块传输完毕时会触发该回调,通常使用该回调函数来显示当前的下载进度;参数data指传递到服务器的数据。
# -*- coding:utf-8 -*-
import urllib.request
url = 'https://www.baidu.com/img/bd_logo.png'
path = 'test.png'
urllib.request.urlretrieve(url, path)
它将百度Logo图片下载至本地。

注意:Python3和Python2代码有少许区别,Python2直接调用urllib.urlopen()。
(二) requests
requests模块是用Python语言编写的、基于urllib的第三方库,采用Apache2 Licensed开源协议的http库。它比urllib更加方便,既可以节约大量的工作,又完全满足http测试需求。requests是一个很实用的Python http客户端库,编写爬虫和测试服务器响应数据时经常会用到。推荐大家从 requests官方网站 进行学习,这里只做简单介绍。
假设读者已经使用“pip install requests”安装了requests模块,下面讲解该模块的基本用法。
1.发送网络请求
r = requests.get("http://www.eastmountyxz.com")
r = requests.post("http://www.eastmountyxz.com")
r = requests.put("http://www.eastmountyxz.com")
r = requests.delete("http://www.eastmountyxz.com")
r = requests.head("http://www.eastmountyxz.com")
r = requests.options("http://www.eastmountyxz.com")
2.为URL传递参数
import requests
payload = {
'key1':'value1', 'key2':'value2'}
r = requests.get('http://httpbin.org/get', params=payload)
print(r.url)
输出结果如下图所示,将参数进行了拼接。
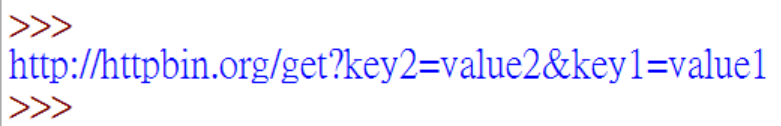
3.响应内容
import requests
r = requests.get('http://www.eastmountyxz.com')
print(r.text)
print(r.encoding)
4.二进制响应内容
r = requests.get('http://www.eastmountyxz.com')
print(r.content)
5.定制请求头
url = 'http://www.ichunqiu.com'
headers = {
'content-type':'application/json'}
r = requests.get(url, headers=headers)
注意:headers中可以加入cookies
6.复杂的POST请求
payload = {
'key1':'value1', 'key2':'value2'}
r = requests.post('http://httpbin.org/post', data=payload)
7.响应状态码和响应头
r = requests.get('http://www.ichunqiu.com')
r.status_code
r.headers
8.Cookies
r.cookies
r.cookies['example_cookie_name']
9.超时
requests.get('http://www.ichunqiu.com', timeout=0.001)
10.错误和异常
遇到网络问题(如:DNS查询失败,拒绝链接等)时,requests会抛出一个ConnectionError异常;遇到罕见的无效HTTP响应式时,requests则会抛出一个HTTPError异常;若请求超时,会抛出一个Timeout异常。
(三) 网络爬虫案例
网络爬虫又称为网页蜘蛛,网络机器人,网页追逐者,是按照一定规则自动抓取万维网信息的程序或脚本。最大好处是批量且自动化获得和处理信息,对于宏观或微观的情况都可以多一个侧面去了解。在安全领域,爬虫能做目录扫描、搜索测试页面、样本文档、管理员登录页面等。很多公司(如绿盟)的Web漏洞扫描也通过Python来自动识别漏洞。
下面两个案例虽然简单,却能解决很多人的问题,希望读者可以独立完成。
1.设置消息头请求(流量分析相关)
假设我们需要抓取360百科的乔布斯信息,如下图所示。
传统的爬虫代码会被网站拦截,从而无法获取相关信息。
# -*- coding: utf-8 -*-
import requests
url = "https://baike.so.com/doc/24386561-25208408.html"
content = requests.get(url, headers=headers)
print(content.text)
右键审查元素(按F12),在Network中获取Headers值。headers中有很多内容,主要常用的就是user-agent 和 host,它们是以键对的形式展现出来,如果user-agent 以字典键对形式作为headers的内容,就可以反爬成功。
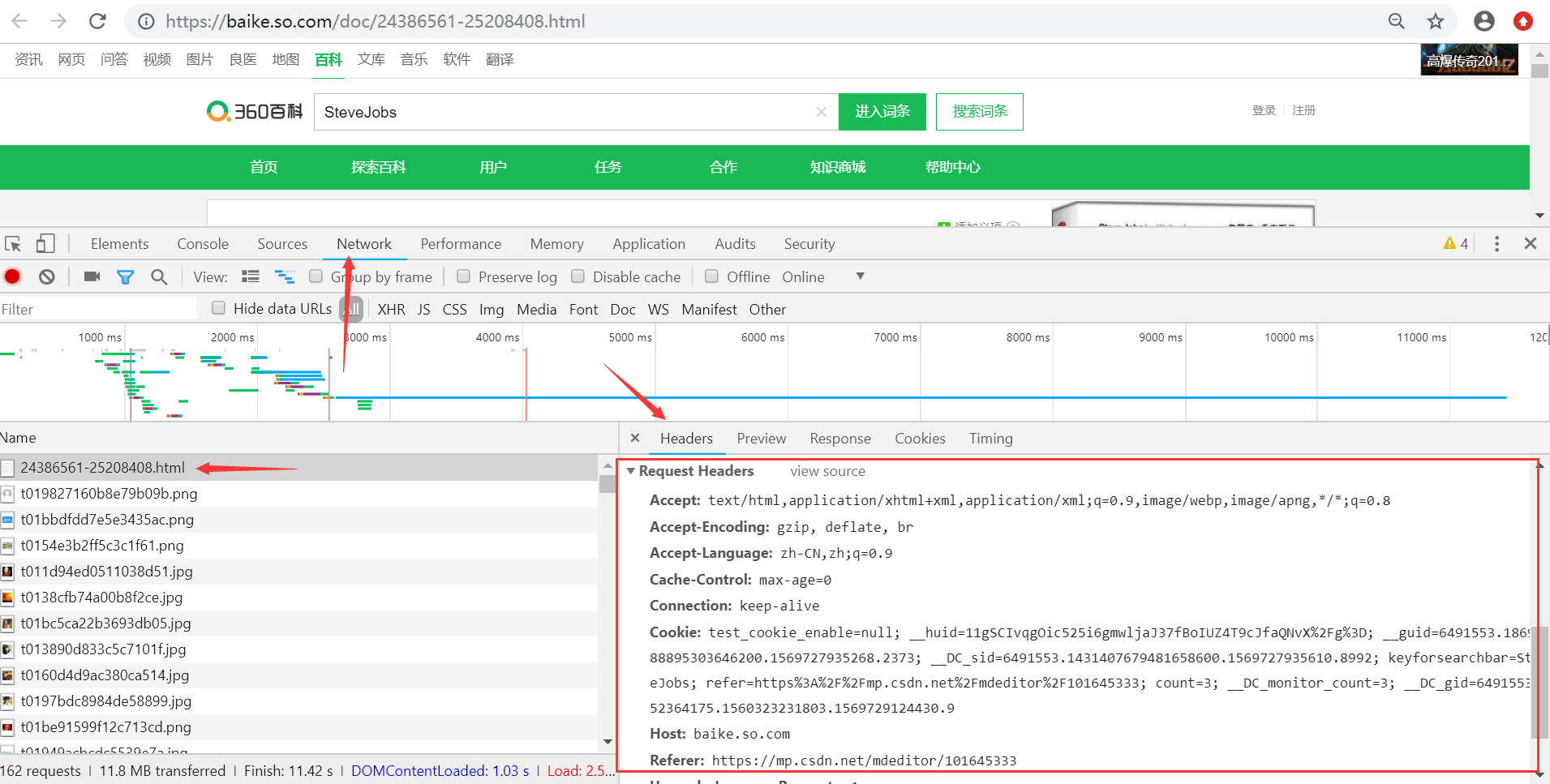
代码如下:
# -*- coding: utf-8 -*-
import requests
#添加请求头
url = "https://baike.so.com/doc/24386561-25208408.html"
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
content = requests.get(url, headers=headers)
content.encoding='utf-8'
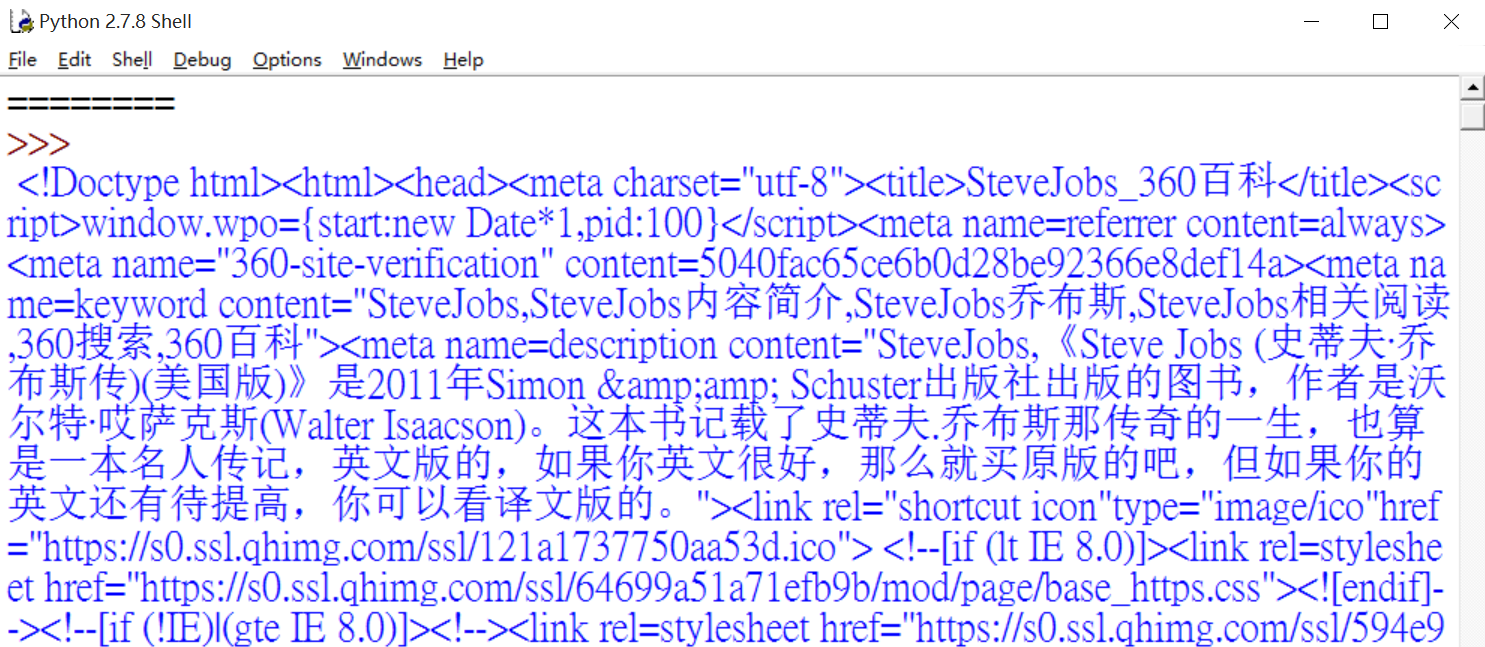
print(content.text)
输出结果如下图所示:
有部分网站会返回Json格式的数据,我们可以通过json模块进行处理。核心代码如下:
data = json.loads(r.text)
print(data['result'])
name_len = len(data['result'])
for i range(name_len):
print(data['result'][i]['courseName'])
2.提交数据请求(盲注相关)
部分网站如果涉及到翻页,需要获取所有页码的信息,最传统的方法是定义一个函数,然后设计一个循环,一次遍历不同页面的内容实现。核心代码如下:
url_start = ""
url_end = ""
def lesson(url):
....
for i in range(1,9)
url = url_start+ str(i) + url_end
lesson(url)
但如果URL始终保持不变,就需要我们深入地分析,或通过Selenium模拟浏览器抓取,这里提供一个技巧性比较强的方法。
假设我们想爬取某网站的公开信息,但通过翻页发现这个页面的url地址是不变的,我们大致就可以判断出,中间表格的数据是通过js动态加载的,我们可以通过分析抓包,找到真实的请求地址。目标网址如下:
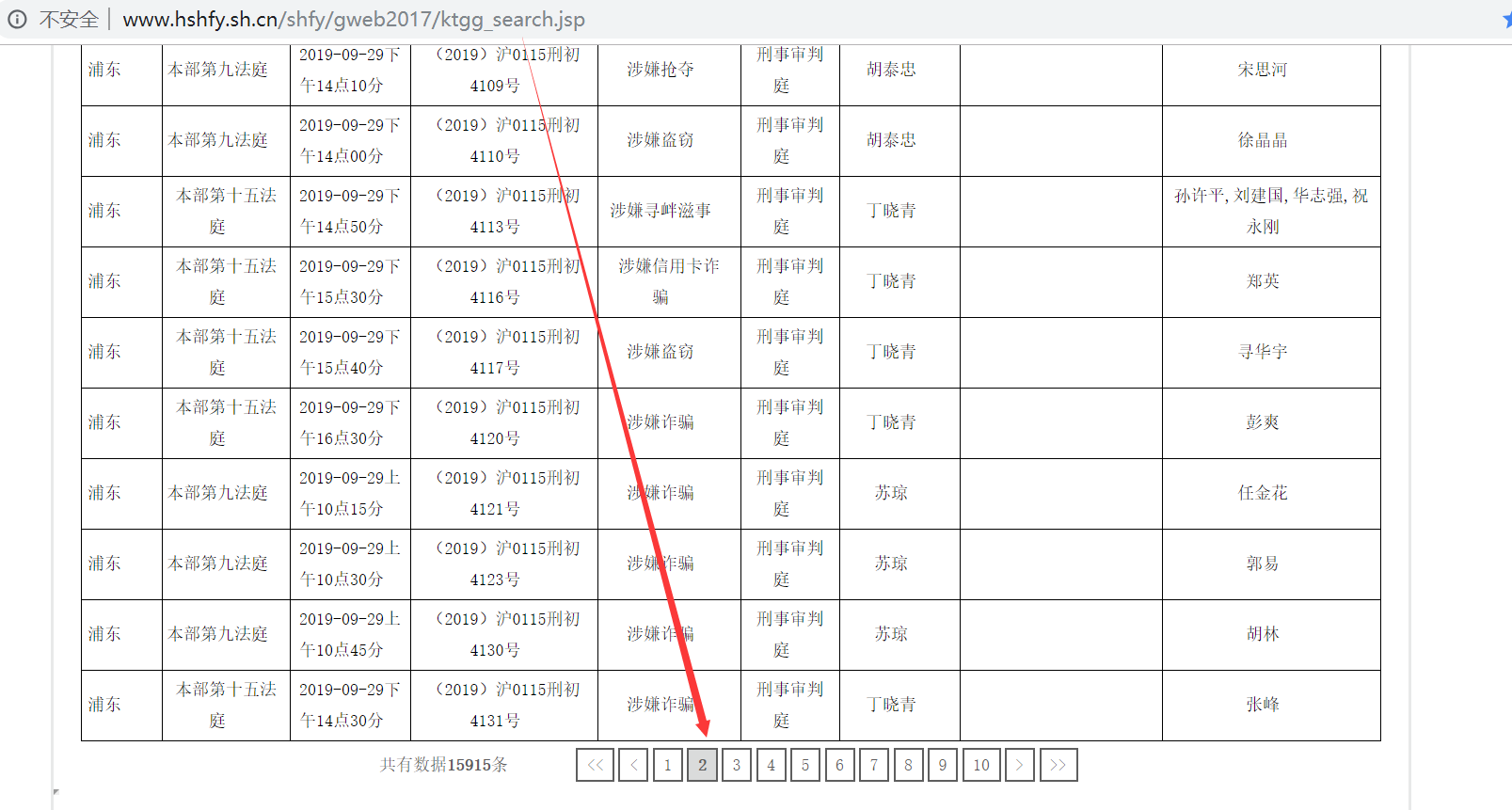
通过审查元素可以发现有个pagesnum变量,它标记为我们的页码,所以这里需要通过requests提交变量数据,就能实现翻页。
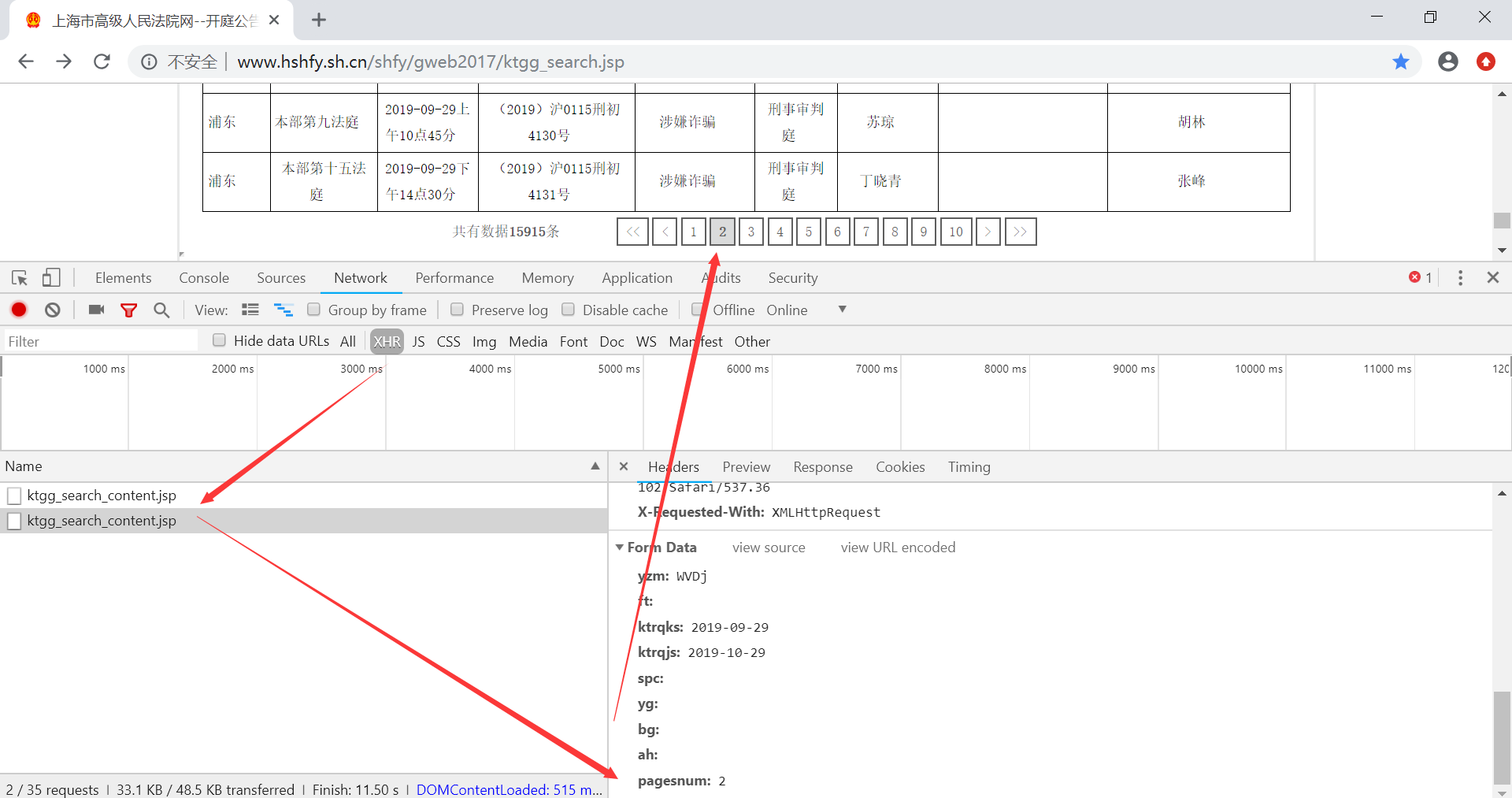
核心代码如下:
# -*- coding: utf-8 -*-
import requests
import time
import datetime
url = "http://www.hshfy.sh.cn/shfy/gweb/ktgg_search_content.jsp?"
page_num = 1
date_time = datetime.date.fromtimestamp(time.time())
print(date_time)
data = {
"pktrqks": date_time,
"ktrqjs": date_time,
"pagesnum": page_num
}
print(data)
content = requests.get(url, data, timeout=3)
content.encoding='gbk'
print(content.text)
四.Python套接字通信
(一) 什么是C/S架构呢?
Python网络通讯主要是C/S架构的,采用套接字实现。C/S架构是客户端(Client)和服务端(Server)架构,Server唯一的目的就是等待Client的请求,Client连上Server发送必要的数据,然后等待Server端完成请求的反馈。
C/S网络编程:Server端进行设置,首先创建一个通信端点,让Server端能够监听请求,之后就进入等待和处理Client请求的无限循环中。Client编程相对Server端编程简单,只要创建一个通信端点,建立到服务器的链接,就可以提出请求了。
(二) 什么是套接字?
套接字是一种具有之前所说的“通信端点”概念的计算网络数据结构,网络化的应用程序在开始任何通信都必须创建套接字。相当于电话插口,没它无法通信,这个比喻非常形象。Python支持:AF_UNIX、AF_NETLINK、AF_INET,其中AF_INET是基于网络的套接字。
套接字起源于20世纪70年代加州伯克利分校版本的Unix,即BSD Unix,又称为“伯克利套接字”或“BSD套接字”。最初套接字被设计用在同一台主机上多个应用程序之间的通讯,这被称为进程间通讯或IPC。
套接字分两种:基于文件型和基于网络
- 第一个套接字家族为AF_UNIX,表示地址家族:UNIX。包括Python在内的大多数流行平台上都使用术语“地址家族”及其缩写AF。由于两个进程都运行在同一台机器上,而且这些套接字是基于文件的,所以它们的底层结构是由文件系统来支持的。可以理解为同一台电脑上,文件系统确实是不同的进程都能进行访问的。
- 第二个套接字家族为AF_INET,表示地址家族:Internet。还有一种地址家族AF_INET6被用于网际协议IPv6寻址。Python 2.5中加入了一种Linux套接字的支持:AF_NETLINK(无连接)套接字家族,让用户代码与内核代码之间的IPC可以使用标准BSD套接字接口,这种方法更为精巧和安全。
如果把套接字比作电话的查看——即通信的最底层结构,那主机与端口就相当于区号和电话号码的一对组合。一个因特网地址由网络通信必须的主机与端口组成。而且另一端一定要有人接听才行,否则会提示“对不起,您拨打的电话是空号,请查询后再拨”。同样你也可能会遇到如“不能连接该服务器、服务器无法响应”等。合法的端口范围是0~65535,其中小于1024端口号为系统保留端口。
(三) 面向连接与无连接
1.面向连接 TCP
通信之前一定要建立一条连接,这种通信方式也被成为“虚电路”或“流套接字”。面向连接的通信方式提供了顺序的、可靠地、不会重复的数据传输,而且也不会被加上数据边界。这意味着,每发送一份信息,可能会被拆分成多份,每份都会不多不少地正确到达目的地,然后重新按顺序拼装起来,传给正等待的应用程序。
实现这种连接的主要协议就是传输控制协议TCP。要创建TCP套接字就得创建时指定套接字类型为SOCK_STREAM。TCP套接字这个类型表示它作为流套接字的特点。由于这些套接字使用网际协议IP来查找网络中的主机,所以这样形成的整个系统,一般会由这两个协议(TCP和IP)组合描述,即TCP/IP。
2.无连接 UDP
无需建立连接就可以通讯。但此时,数据到达的顺序、可靠性及不重复性就无法保障了。数据报会保留数据边界,这就表示数据是整个发送的,不会像面向连接的协议先拆分成小块。它就相当于邮政服务一样,邮件和包裹不一定按照发送顺序达到,有的甚至可能根本到达不到。而且网络中的报文可能会重复发送。那么这么多缺点,为什么还要使用它呢?由于面向连接套接字要提供一些保证,需要维护虚电路连接,这都是严重的额外负担。数据报没有这些负担,所有它会更”便宜“,通常能提供更好的性能,更适合某些场合,如现场直播要求的实时数据讲究快等。
实现这种连接的主要协议是用户数据报协议UDP。要创建UDP套接字就得创建时指定套接字类型为SOCK_DGRAM。这个名字源于datagram(数据报),这些套接字使用网际协议来查找网络主机,整个系统叫UDP/IP。
(四) socket()模块函数
使用socket模块的socket()函数来创建套接字。语法如下,其中socket_family不是AF_VNIX就是AF_INET,socket_type可以是SOCK_STREAM或者SOCK_DGRAM,protocol一般不填,默认值是0。
- socket(socket_family, socket_type, protocol=0)
创建一个TCP/IP套接字的语法如下:
- tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
同样创建一个UDP/IP套接字的语法如下:
- udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
由于socket模块中有太多属性,所以使用"from socket import *"语句,把socket模块里面的所有属性都带到命名空间中,大幅缩短代码。调用如下:
- tcpSock = socket(AF_INET, SOCK_STREAM)
下面是最常用的套接字对象方法:

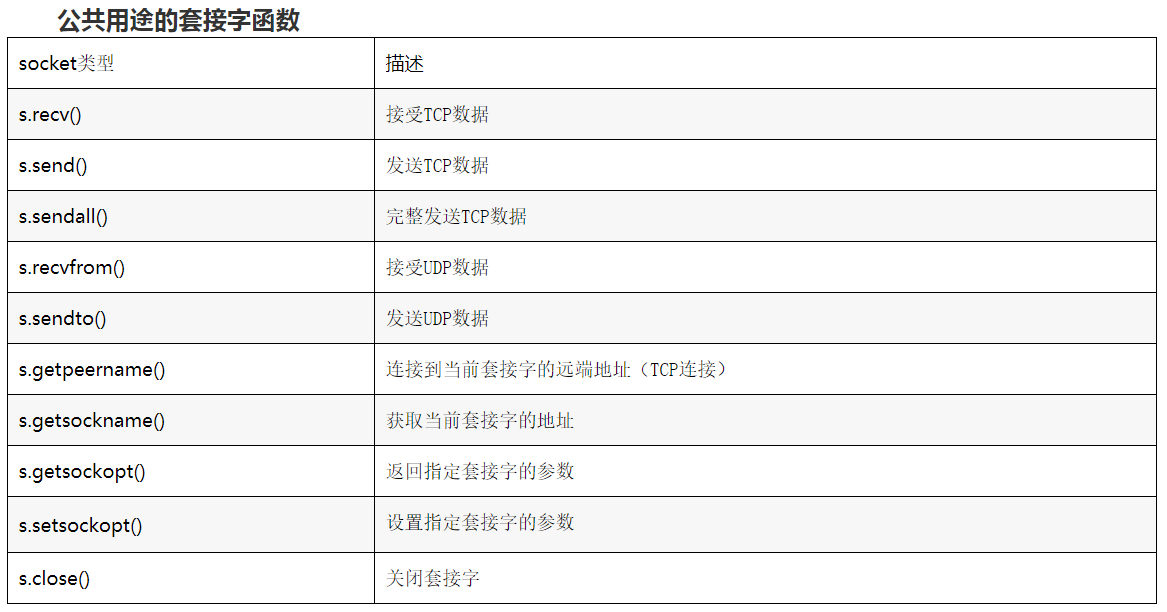
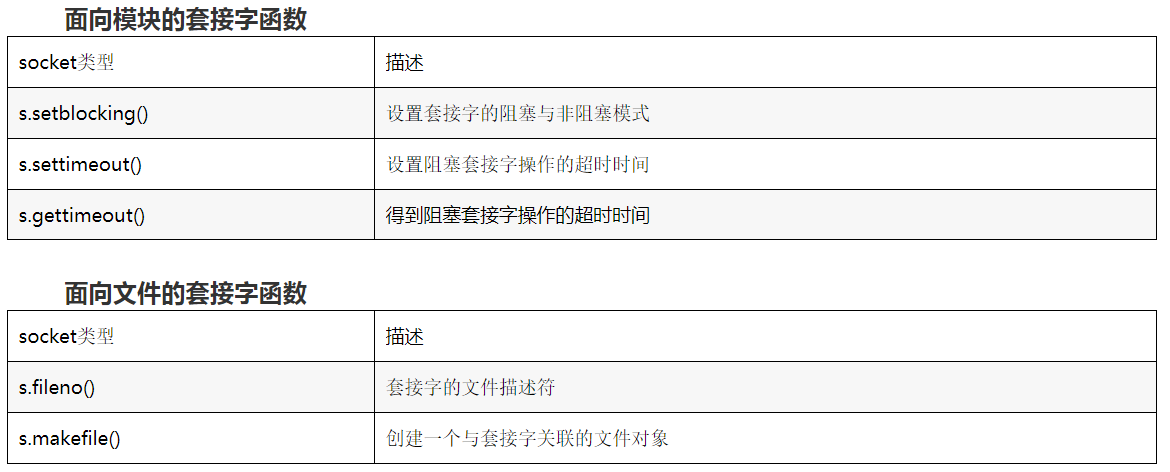
提示:在运行网络应用程序时,如果能够使用在不同的电脑上运行服务器和客户端最好不过,它能让你更好理解通信过程,而更多的是localhost或127.0.0.1。
(五) TCP通信实例
1.服务器 tcpSerSock.py
核心操作如下:

# -*- coding: utf-8 -*-
from socket import *
from time import ctime
HOST = 'localhost' #主机名
PORT = 21567 #端口号
BUFSIZE = 1024 #缓冲区大小1K
ADDR = (HOST,PORT)
tcpSerSock = socket(AF_INET, SOCK_STREAM)
tcpSerSock.bind(ADDR) #绑定地址到套接字
tcpSerSock.listen(5) #监听 最多同时5个连接进来
while True: #无限循环等待连接到来
try:
print('Waiting for connection ....')
tcpCliSock, addr = tcpSerSock.accept() #被动接受客户端连接
print('Connected client from : ', addr)
while True:
data = tcpCliSock.recv(BUFSIZE) #接受数据
if not data:
break
else:
print('Client: ',data)
info = ('[%s] %s' %(ctime(),data))
info = bytes(info, encoding = "utf8")
tcpCliSock.send(info) #时间戳
except Exception as e:
print('Error: ',e)
tcpSerSock.close() #关闭服务器
tcpCliSock.close()
2.客户端 tcpCliSock.py
核心操作如下:

# -*- coding: utf-8 -*-
from socket import *
HOST = 'localhost' #主机名
PORT = 21567 #端口号 与服务器一致
BUFSIZE = 1024 #缓冲区大小1K
ADDR = (HOST,PORT)
tcpCliSock = socket(AF_INET, SOCK_STREAM)
tcpCliSock.connect(ADDR) #连接服务器
while True: #无限循环等待连接到来
try:
data = input('>')
data = bytes(data, encoding = "utf8")
print(data,type(data))
if not data:
break
tcpCliSock.send(data) #发送数据
data = tcpCliSock.recv(BUFSIZE) #接受数据
if not data:
break
print('Server: ', data)
except Exception as e:
print('Error',e)
tcpCliSock.close() #关闭客户端
由于服务器被动地无限循环等待连接,所以需要先运行服务器,再开客户端。又因为我的Python总会无法响应,所以采用cmd运行服务器Server程序,Python IDLE运行客户端进行通信。运行结果如下图所示:
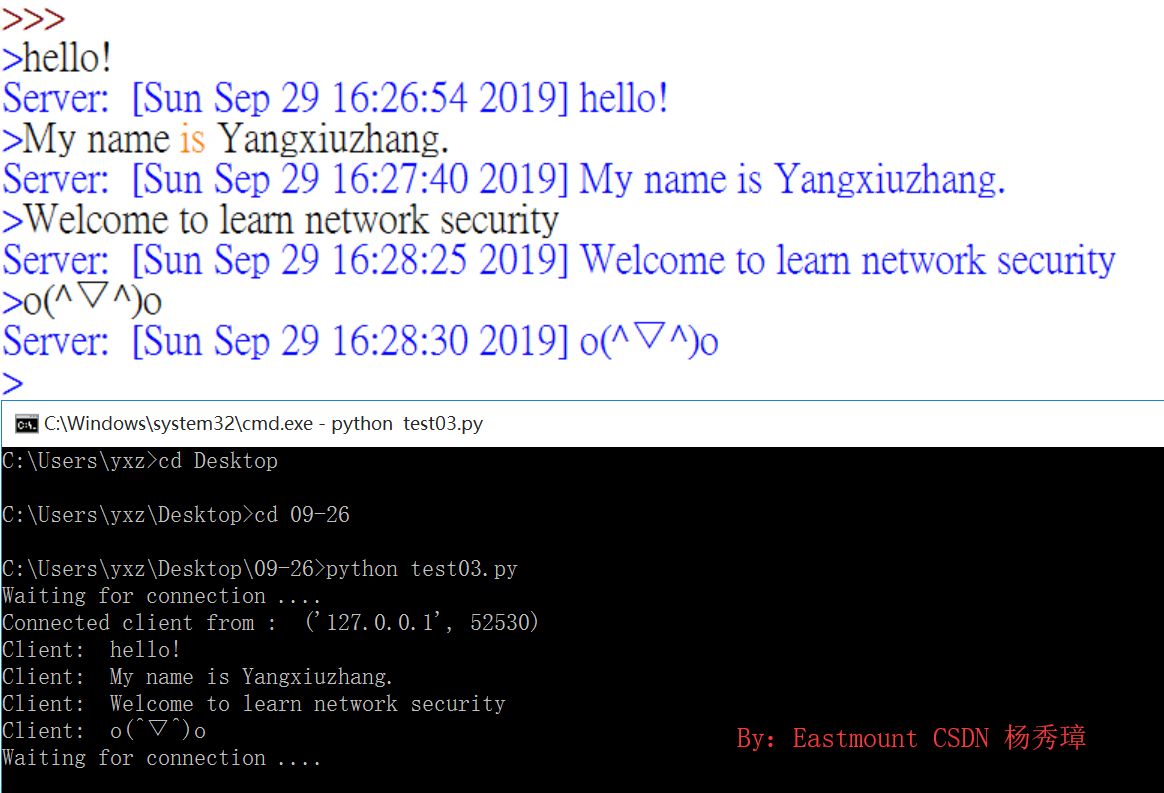
另一种方法同时打开Python3.6和Python3.7进行通信,如下图所示。

建议创建线程来处理客户端请求,SocketServer模块是一个基于socket模块的高级别的套接字通信模块,支持新的线程或进程中处理客户端请求。同时建议在退出和调用服务器close()函数时使用try-except语句。
那么,如何反弹shell程序呢?
使用 from subprocess import Popen, PIPE 导入库,调用系统命令实现。核心代码如下,后续Windows漏洞复现深入讲解后,你就更好理解这部分代码了。

五.总结
希望这篇文章对你有所帮助,这是Python黑帽第二篇博客,后续作者也将继续深入学习,制作一些常用的小工具供大家交流。最后,真诚地感谢您关注“娜璋之家”公众号,也希望我的文章能陪伴你成长,希望在技术路上不断前行。文章如果对你有帮助、有感悟,就是对我最好的回报,且看且珍惜!再次感谢您的关注,也请帮忙宣传下“娜璋之家”,哈哈~初来乍到,还请多多指教。
前文:
三尺讲台,三寸笔,三千桃李。
十年树木,十年风,十万栋梁。
祝天下所有老师节日快乐,也是自己第五个教师节。从我们家女神2011年去山村支教,到我2014年走上支教的讲台,再到2016年真正成为大学老师,感恩这一路走来,也祝女神和我节日快乐,感谢所有人的祝福和帮助。
无论未来是否继续当老师,秀璋都会一直牢记当老师的那份美好,记住分享知识的魅力,记住你们脸上洋溢着灿烂的笑容,我也会线上分享更好的文章,真心希望帮助更多人,把这些年所学所做分享出来。不忘初心,感恩前行。真是奇幻,师范出身的她没成为老师,程序猿却去教书了,哈哈!

(By:娜璋AI安全之家 Eastmount 2020-09-11 夜于武汉)
参考文献:
- 《安全之路Web渗透技术及实战案例解析》陈小兵老师
- 《Wireshark数据包分析实战》第二版 Chris Sanders
- https://www.bilibili.com/video/av29479068
- https://www.bilibili.com/video/av57850011