目录
一、SGD的遇到的问题
在深度学习中,通常采用SGD来作为优化算法来更新参数。因为传统的梯度下降算法每更新一次,都要计算所有的样本,浪费时间,而SGD每次迭代使用一个样本来对参数进行更新,使得训练速度加快。
而SGD会陷入局部最优解
由于局部最优解的梯度值也为0,而且SGD只考虑当前时刻的梯度,当前时刻的梯度为0时,就会停止更新参数,这样就陷入了一个局部最优解的情况。
二、指数加权移动平均值
在介绍Momentum之前先了解下什么时指数加权移动平均值,听起来名字很长很复杂,其实用一句话概括就是:考虑了历史问题。这句话先放这,大家一会就懂了。
用吴恩达老师视频课中的例子给大家讲一下吧:
指数加权移动平均值的公式为:
其中代表当天的实际温度,
代表历史温度,系数 β 表示加权下降的速率。
在上图中有两条不同颜色的线,分别对应着不同的 β值。
当 β=0.9 时,有 ,对应着图中的红线,此时虽然曲线有些波动,但总体能拟合真实数据
当 β=0.98 时,有,对应着图中的绿线,此时曲线较平,但却有所偏离真实数据
从上面的公式可以看出,计算当前的温度的时候,会考虑到历史温度
的情况。
指数加权移动平均值,我们目前只了解了考虑历史问题。那么指数、加权、移动是什么呢?一张图搞定:
从上图中可以看到如何计算,把上图中蓝色的式子整合后就是如下的式子:
可以看出,指数有了、加权有了,就差个移动了,其实移动也有了,从上面式子可以看出,我们计算第100天的温度,需要计算历史温度值,但是这个历史温度值其实并不需要从第1天算到第99天,因为第一天前面的系数已经无限接近于0,就没有了什么意义,也就是说由于时间隔得太久了,第一天的温度值对第一百天的温度值起不到什么作用,实际上起作用的天数为:天,当β=0.9时,则只需要计算10天的历史温度就行了,也就是说如果计算第100天的温度,只需要从第90天开始计算历史温度即可,如果说时计算第200天的温度,只需要从第190天开始计算历史温度即可,这样就形成了移动的效果。
总结一句话就是:历史问题不能太遥远。
三、Momentum
有了前面的铺垫,接下来就可开始讲解Momentum了。在SGD中,我们知道在优化参数时会陷入局部最优解,因为它只考虑当前的梯度。而Momentum却不同,它在SGD的基础上考虑了历史梯度,这样即使碰到局部最优解使得当前梯度为0,由于还存在一个历史梯度,相当于惯性,那么它是能够冲过局部最优解的,如下图:
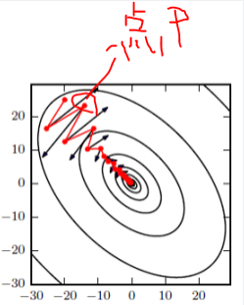
如上图,黑色时SGD,红的是Momentum,可以看出有了Momentum之后,梯度下降的震动没有SGD那样的剧烈,比如在P处,它的前后两个梯度方向是相反的,在SGD中动荡很大。而在Momentum中,在P处,前一个时刻的梯度是斜向上,当前时刻的梯度为斜向下。由于两个方向相反而且历史梯度斜向上的存在,导致当前的梯度方向下降的就不会那么剧烈,这个时候可以把历史梯度当作阻力。如果历史梯度和当前梯度方向相同,那么就可以把历史梯度当作动力。
总结:如果历史梯度和当前梯度方向相同,增速,反之,减速。

本人为中海洋计算机研究生,主要研究深度学习,机器学习和python,希望大家可以关注下面的公众号,我会持续更新原创文章,也欢迎来投稿,咱们一块交流,一块进步。
QQ交流群:1147776174
