在深度学习中,如果模型太复杂则会产生过拟合现象。
一种常用的防止过拟合的方法是正则化,通过在成本函数中添加正则项来起到惩罚参数的作用,不熟悉正则化的小伙伴可以看我之前发布的文章:一文搞定正则化(作用,方法,原理)。
而另一种常用的防止过拟合的方法就是:Drop out
在2012年,Hinton提出了Drop out的思想,它的原理是在前向传播的时候,可以使某个神经元以概率p停止工作,达到一个泛化的效果。

上图为Drop out的原理,它这样做的好处我认为有两点:
1、可以使复杂的神经网络变得简单。
2、由于每一个神经元都有机会失活,所以不敢把权值设的太高,这样就不会只关注某几个特征,起到了泛化的效果。
如何使用Drop out?
这个是一张知乎大佬文章里的图,讲述了有Drop out 和无Drop out的计算方法。
没有使用Dropout的计算公式:

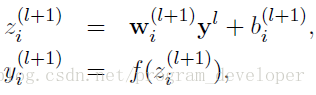
使用Dropout的网络计算公式:
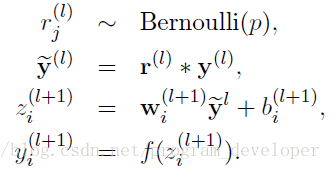
可见在有了Dropout中的公式有了一定的变化,首先先用Bernoulli()函数定义一个概率为p的0、1向量,然后用第L层的0、1向量去乘以第L层的激活值,比如我们第L层有20个神经元,而概率P为0.4,这样就相当于第L层的0、1向量中0出现的概率为0.4,相乘以后就会有20*0.4=8个神经元被置为0。向量y1……y20还要乘以1/(1-p),因为p为丢弃概率,那么1-p就为保留概率,缩放的时候某个点的输出期望为E(x) = (1-p)(x/(1-p)) + p * 0 = x,这样就和测试集上神经元的输出期望保持一致。
如果在训练集上不做y1……y20乘以1/(1-p),那么就需要在测试集上做点手脚了。
因为测试的时候为了保证预测结果的准确性,通常不采用Drop out,因为Drop out中神经元的关闭时随机的,导致了预测结果不稳定。作为补偿,会让测试机中神经元的权重乘以1-p,这样的话训练的时候的期望为,测试的时候也为(1-p)x。
也可以这么理解:设p=0.5,某一层有20个神经元,每一个神经元的输出都为1。那么在训练集上,使用Dropout后,值为20*1*0.5=10。而在测试集中没有Dropout,但是我们缩小了权值使得权值变成原来的一半,这样得到值也是10。

本人为中海洋=计算机研究生,主要研究深度学习,机器学习和python,希望大家可以关注以下公众号,分享原创文章,也欢迎来投稿,咱们一块交流,一块进步。
