全文共1910字,预计学习时长5分钟

图源:unsplash
每个Netflix的数据科学家,不管其背景是来自生物学、心理学、物理学、经济学、数学、统计学还是生物统计学,都对Netflix分析因果效应的方式做出过有意义的贡献。
在过去的几十年里,这些领域的科学家已经在因果效应研究方面取得了许多进展,涉及工具变量、森林方法、非均匀效应、动态效果、分位数效应等等。这些方法可以为决策提供充分的信息,例如在实验平台(“XP”)或算法策略引擎方面。
我们希望通过提供能够有效估计因果关系模型,并将因果关系整合到大型工程系统中的软件,来提升研究人员的效率。这是具有挑战性的,因为因果效应算法需要与模型拟合,考虑上下文和可能采取的措施,评估反应变量并计算反事实推论间的差异。
当面对大规模的资料组、高维度的特征、可供选择的大量备选措施以及众多的回应,计算会激增,变得不堪重负。要广泛地获得因果效应模型的软件集成,软件工程的重大投资(尤其在计算方面)是必需的。
为应对这些挑战,Netflix构建了跨学科的交叉领域,包括因果推论、算法设计和数值计算,我们想将其作为计算因果推论(CompCI)在其他行业分享。
计算因果推论将软件的实现重点放在因果推论,尤其是在高性能数值计算方面。我们执行的几个算法将会是高性能、低内存占用的。例如,我们的试验平台正从两项样本t测验转向平均效应、非均匀效应和时间动态处理效应评估。这些效应帮助企业了解用户基数、用户基数中的不同时间段,以及时间段长期以来是否有趋向。
我们同时利用模型中的用户协变量来提高统计能力。虽然这项丰富的业务分析帮助告知业务战略并增加成员满意度,但众多的数据需要大量的内存,对如此大容量数据的因果效应评估在计算方面是十分繁重的。
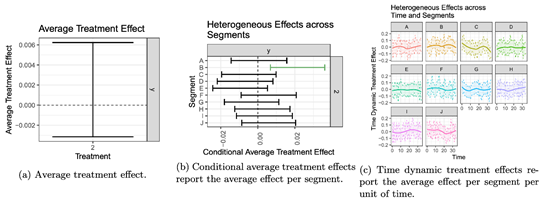
过去,非均匀效应和时间动态效应的协变量调整计算是缓慢、内存负担重、难以调试、工程风险来源多,最终无法拓展到许多大型实验中去的。
通过计算因果推论的优化,我们可以仅用一台机器,在10秒内对一个1000万个观测值的数据集进行数百个条件平均效应及其方差估计。更极致的是,我们还可以在一小时内用一台机器分析数以亿计的数值的时间动态处理条件效应。
为达到这个程度,我们利用了一个针对稀疏线性代数进行了完全优化的软件栈,这是一个可以缩减数据容量的无损数据压缩策略,同时也是一个专为评估因果效应优化的数学表达式。我们还对内存和数据调整进行了优化。
这种级别的计算很奢侈。首先,缩放复杂模型的能力意味着可以为商业提供丰富的见解。其次,能够在几秒内分析大型数据集的因果效应增加了研究的敏捷性。再者,在单台机器上分析数据使调试简便。最后,可伸缩性使得大型工程系统的计算易于处理,减少了工程风险。
计算机因果推论是一个跨学科的新领域,我们想在拥有更多实验、研究者和软件工程师的条件下将其共同建立起来。因果推论与工程系统的融合会带来大量的革新。
它需要当地该领域的专家团体联合起来。我们已经发布了开启该讨论的白皮书(https://arxiv.org/abs/2007.10979)。在其中,我们描述了计算因果推论在研究和软件工程系统中的日益增长的需求,也描述了共同因果效应模型的状况,以及我们认为好的评估和优化因果效应的软件框架。

图源:unsplash
最后,计算因果推论白皮书以一系列开放性挑战收尾,例如:
· 众所周知,时间动态处理效应难以缩放。需要不断重复观测,生成大型数据集。这个过程同时包含自相关数,使评估因果效应的变化复杂化。我们该如何计算时间动态处理效应,使其分布更具扩展性呢?
· 在机器学习中,列举损失函数并用数值方法优化,使得开发者能够与跨越数个模型的单个包罗框架进行交互。是否存在这样的包罗框架,能以统一的方式列举不同的因果效应模型?例如,它能通过广义矩方法实现吗?它能够在计算上易于处理吗?
· 我们应该如何开发能够识别因果参数的软件?这个解决办法能帮助构建使用安全,并且能为因果效应分析提供安全编程访问的软件。相信在鉴别方面还有很多边缘情况需要跨学科的团队去解决。

一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)