1 为什么要自监督学习 self-supervised learning
自监督学习是无监督学习的一种特殊方式。我们在无监督学习中讲过了,标注label是十分宝贵的,一般需要人工打标,时间和人力成本都十分高昂。但现实中,获取无标注data确实相对比较easy的事情。我们可以在网络上爬取很多很多的文本、图片、语音、商品信息等。如何利用这些无标注data,一直以来都是无监督学习的一个重要方向。而自监督学习则给出了一种解决方案。
自监督学习通过data的一部分,来predict其他部分,由自身来提供监督信号,从而实现自监督学习。利用自监督学习,可以学到一定的文本或图片的表征,从而有利于下游任务的展开。这就是pretrain-finetune

2 自监督学习实现方案
自监督学习实现方案主要有
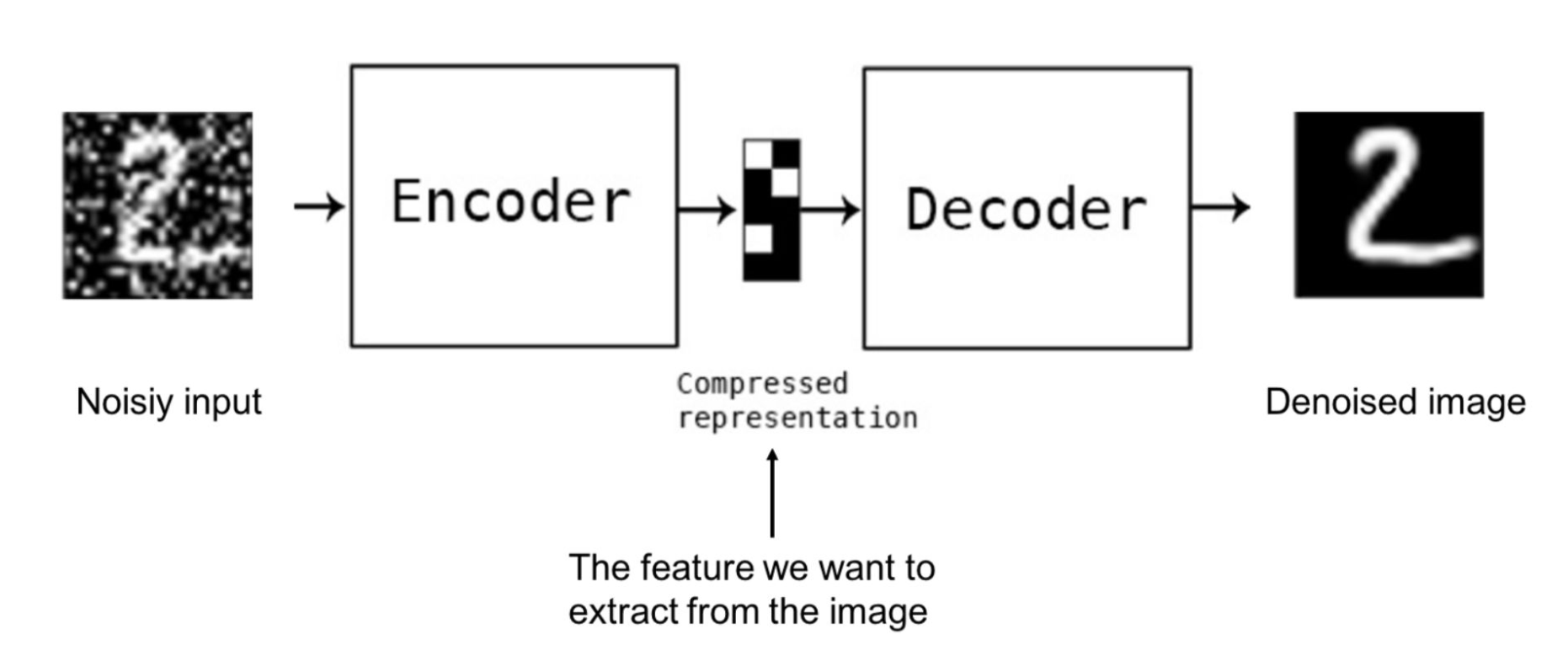
- 利用部分data来重建整个data。这其实就是Denoising Auto-Encoder的一种。NLP方面BERT系列的Mask language model,和CV领域的图像还原In-painting,都是采用了这种方案
- CV领域的一些任务。比如将图片分割为9块,打乱后,进行拼图。将图片旋转一定角度,然后predict旋转的角度。
- 对比学习。比如word2vec,Contrastive Predictive Coding,SimCLR
3 NLP领域的自监督学习
各种NLP预训练模型,就是利用自监督学习实现的。比如Elmo、GPT、BERT、XLNet、Electra、T5等。它们可以看做是一种去噪自编码器denoising Auto-Encoder。
3.1 Auto-Encoder和Auto-regressive LM
它们又分为两种
- 自编码器Auto-Encoder。比如BERT所采用的Mask language model。它将sequence中的部分token,进行mask,然后让模型对mask位置进行predict。它的优点是可以充分利用两个方向的语句信息,在分类、QA、NER等任务上表现很好。缺点是sequence中只有mask位置参与了predict,训练效率较低。另外训练时有mask,而下游任务fine-tune时没有mask,导致两阶段不一致。
- 自回归语言模型 Auto-regressive LM。严格来说MLM掩码语言模型不能认为是一种语言模型。GPT等自回归方式的模型才是真正的语言模型。它利用上文来预测下文的token。它在生成任务上表现较好。优点是pretrain和fine-tune两阶段一致,且sequence中每个位置均参与了predict,训练效率很高。缺点是只能看到上文,无法看到下文,也就是单方向,大大影响了对语句的语义理解。
Auto-Encoder示例如下,它可以获取两个方向的上下文,有助于语义理解
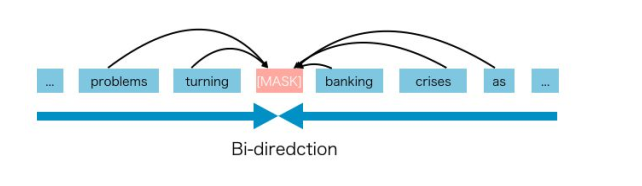
Auto-regressive LM示例如下,不论是从前到后,还是从后到前,均只能单向

3.2 XLNet和PLM
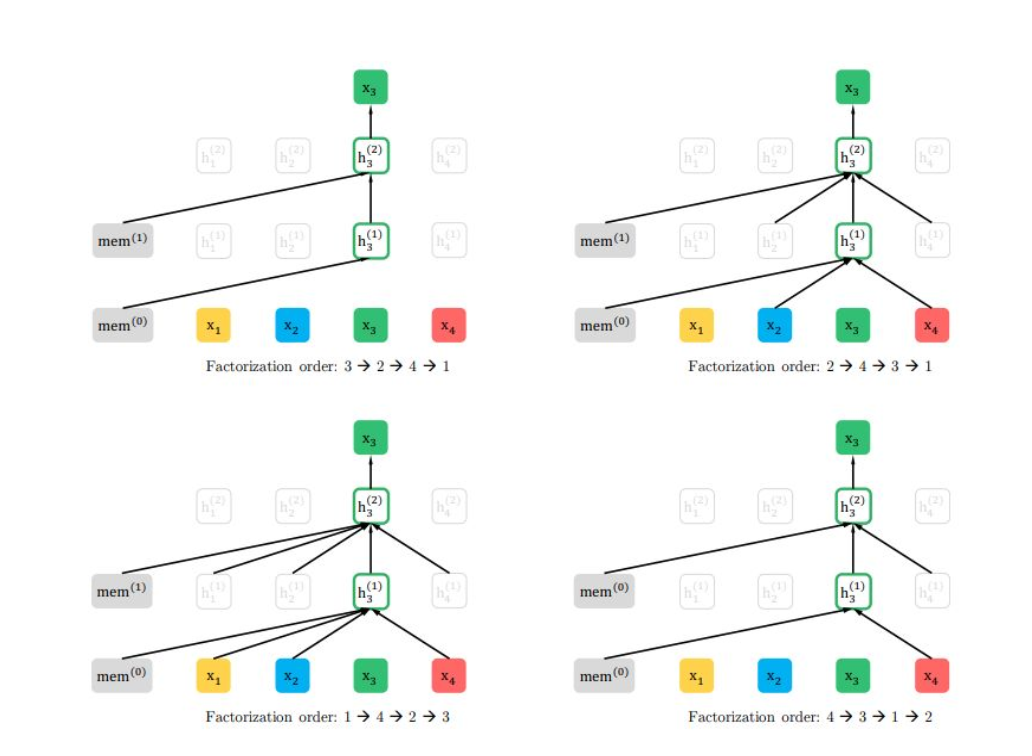
XLNet则结合了二者的优点,它提出了排序语言模型PLM(Permutation LM)。它分为两步
- 排序,将sequence中的token位置打乱,实操中没有直接对token打乱,而是利用了attention mask
- 自回归语言模型predict。由于token的位置打乱了,所以训练语言模型时,可以获取到下文的信息了,有助于对整个sequence的理解。
4 CV领域的自监督学习
CV任务上,也很容易实现自监督学习
4.1 predict missing pieces
将图片中部分区域挖空,然后让模型进行预测,使输出能尽量还原输入图片。
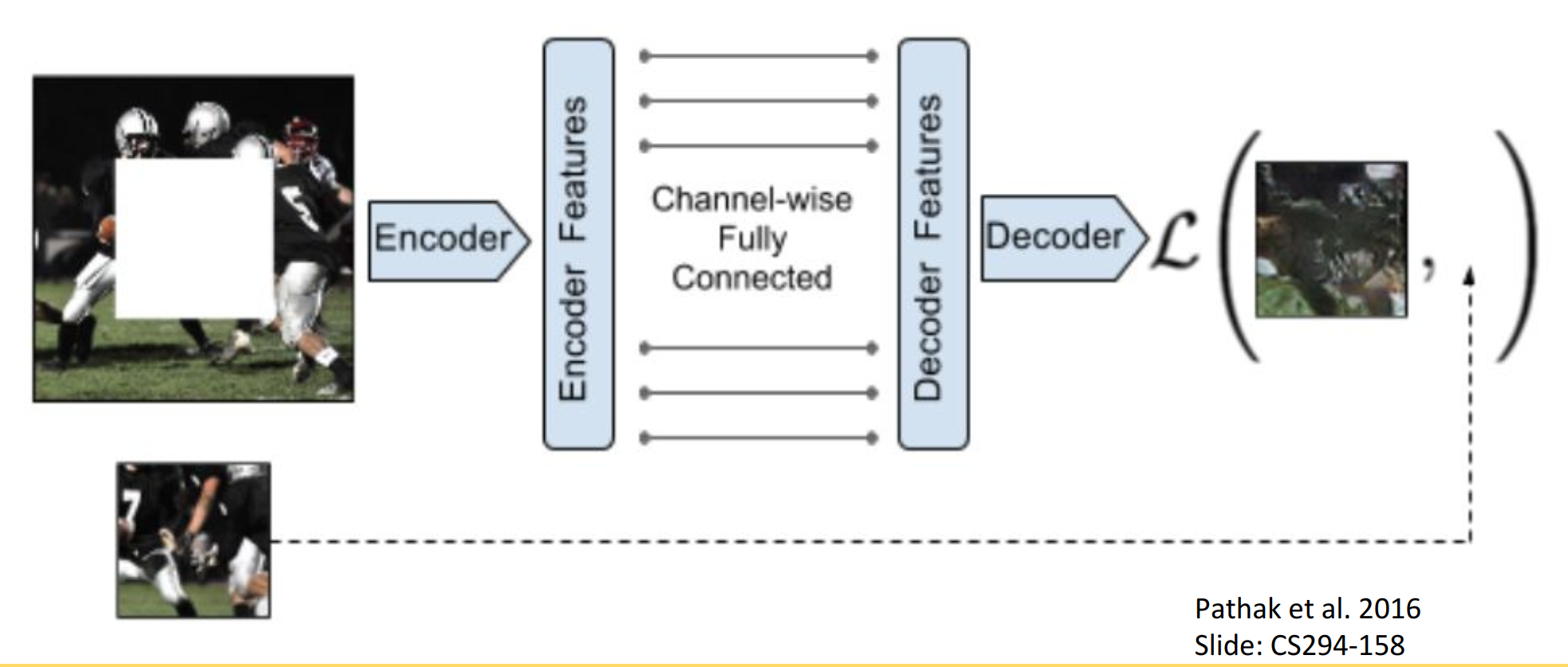
4.2 Jigsaw Puzzles 拼图游戏
将图片分割为多个区域并打乱,然后让模型将它还原为原始图片。和拼图游戏很像。

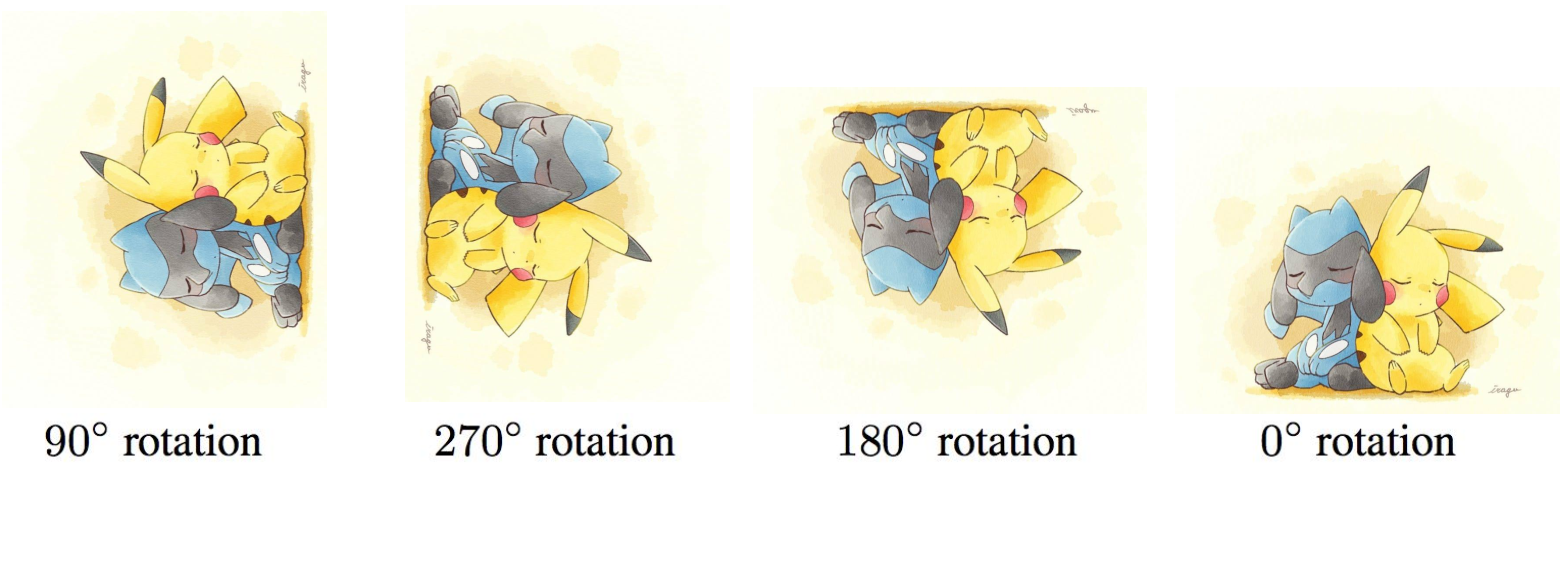
4.3 Rotation 旋转
将图片旋转一定角度,让模型预测旋转了多少度。或者将图片旋转0、90、180、270度四种类别,让模型预测旋转的类别。