Linux基础环境搭建(CentOS7)- 安装Hadoop
1 Hadoop下载及安装
Hadoop在大数据技术体系中的地位至关重要,Hadoop是大数据技术的基础,对Hadoop基础知识的掌握的扎实程度,会决定在大数据技术道路上走多远。

Hadoop的下载
Hadoop下载链接:https://pan.baidu.com/s/1q7Z6HLHJbq-HNjzVqljCNQ
提取码:h5bv
将下载的安装包通过Xftp传输到Linux虚拟机中
Hadoop的安装
创建工作路径/usr/hadoop,下载相应软件,解压至工作路径。
mkdir /usr/hadoop #首先在根目录下建立工作路径/usr/hadoop
cd /opt/software #进入安装包的文件夹
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/hadoop
2 配置Hadoop环境变量(3台)
vim /etc/profile
添加如下内容:
#HADOOP
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin
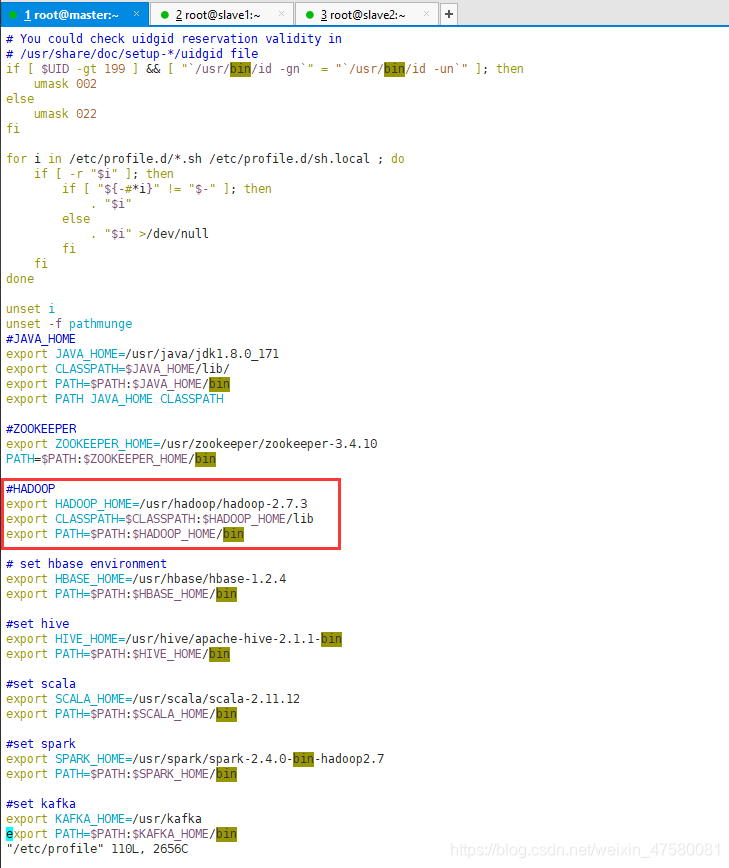
source /etc/profile #使profile生效
3 配置hadoop各组件(配置文件建议直接复制粘贴,防止搞错)
hadoop的各个组件的都是使用XML进行配置,这些文件存放在hadoop的etc/hadoop目录下。
1.hadoop-env.sh
cd $HADOOP_HOME/etc/hadoop
vim hadoop-env.sh
输入以下内容,修改java环境变量:
export JAVA_HOME=/usr/java/jdk1.8.0_171
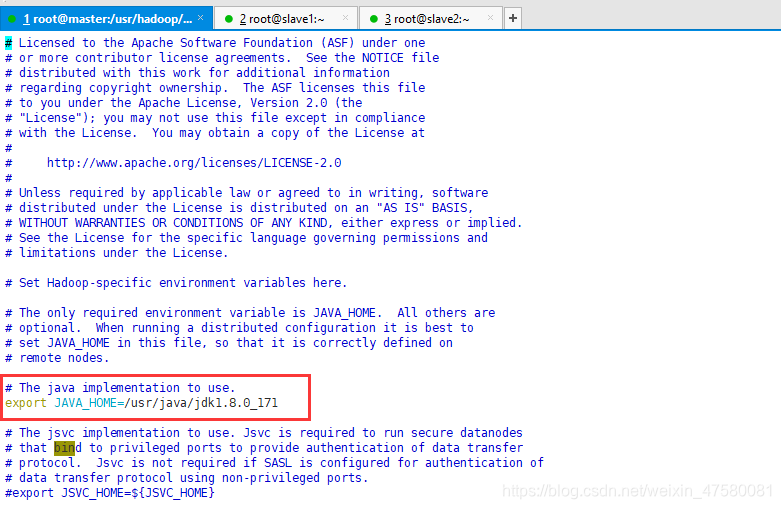
键入“Esc”,退出编辑模式,使用命令“:wq”进行保存退出。
2.core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
</configuration>
master:在主节点的ip或者映射名。
9000:主节点和从节点配置的端口都是9000。

3.mapred-site.xml
hadoop是没有这个文件的,需要将mapred-site.xml.template样本文件复制为mapred-site.xml,对其进行编辑:
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml

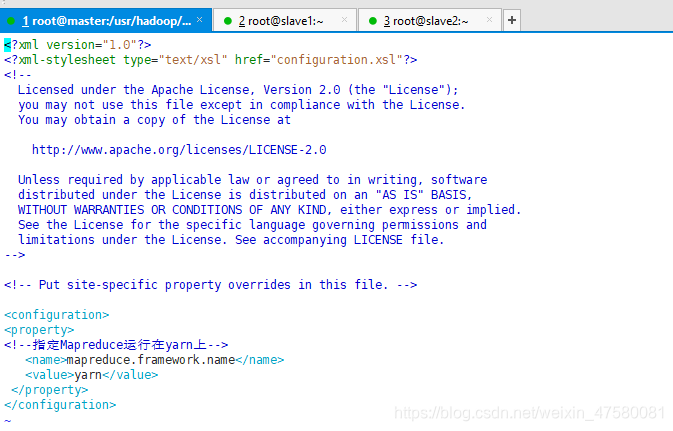
<configuration>
<property>
<!--指定Mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.yarn-site.xml
vim yarn-site.xml
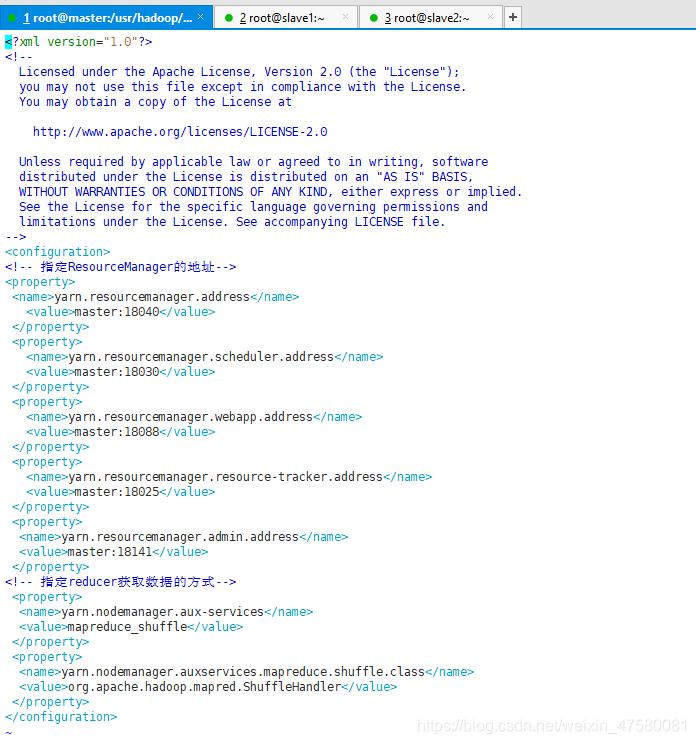
<configuration>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
5.hdfs.site.xml
vim hdfs-site.xml
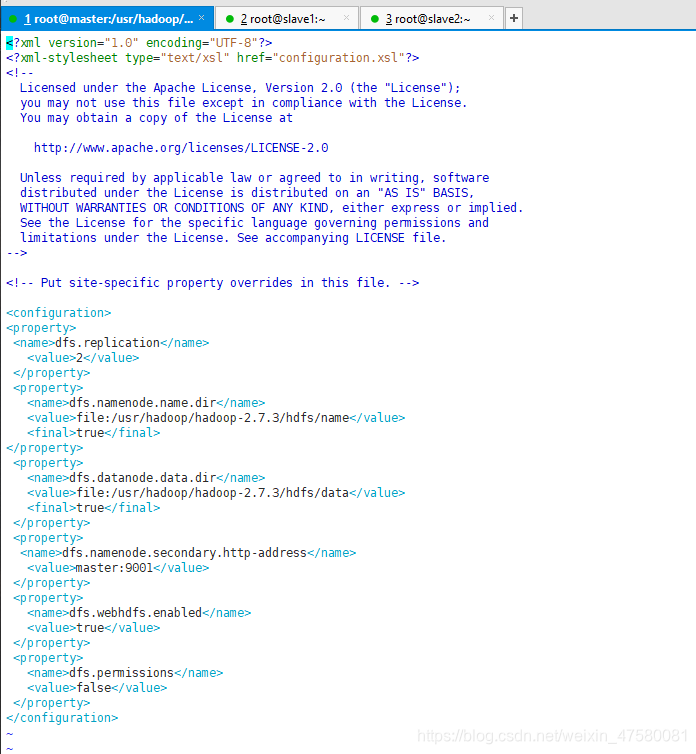
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
dfs.replication:因为hadoop是具有可靠性的,它会备份多个文本,这里value就是指备份的数量(小于等于从节点的数量)。
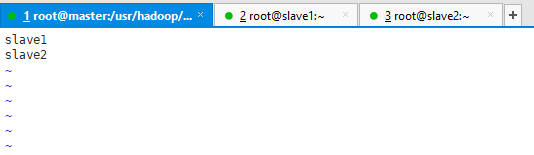
6.slaves & master
编写slaves文件,添加子节点slave1和slave2;
vim slaves
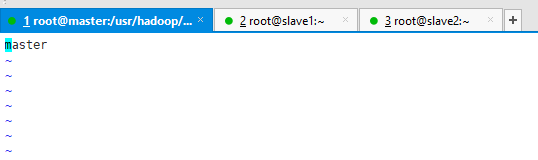
编写master文件,添加主节点master。
vim master
7 同步其他虚拟机
分发profile文件,hadoop文件到slave1和slave2节点上
scp -r /etc/profile root@slave1:/etc/profile #将环境变量profile文件分发到slave1节点
scp -r /etc/profile root@slave2:/etc/profile #将环境变量profile文件分发到slave2节点
scp -r /usr/hadoop root@slave1:/usr/ #将hadoop文件分发到slave1节点
scp -r /usr/hadoop root@slave2:/usr/ #将hadoop文件分发到slave2节点
生效两个从节点的环境变量
source /etc/profile #slave1和slave2都要执行
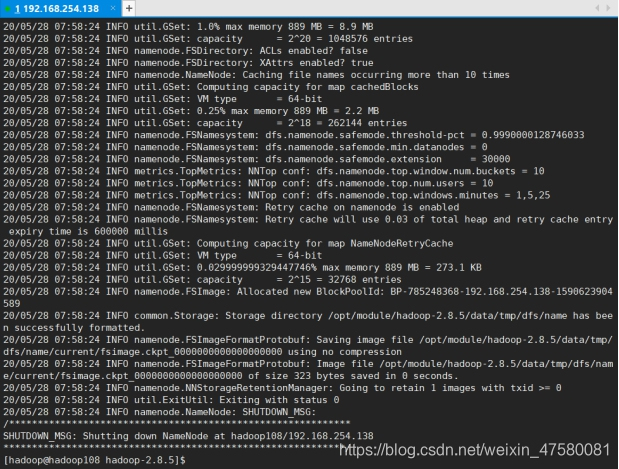
8 格式化hadoop (仅在master中进行操作)
首先查看jps是否启动hadoop,若无才可格式化
hadoop namenode -format
当出现“Exiting with status 0”的时候,表明格式化成功。
9 开启hadoop集群
仅在master主机上开启操作命令。它会带起从节点的启动。(仅在master中进行操作)
cd /usr/hadoop/hadoop-2.7.3 #回到hadoop目录
sbin/start-all.sh #主节点开启服务
master

slave1
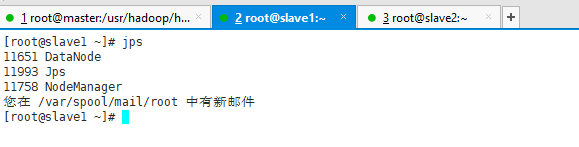
slave2
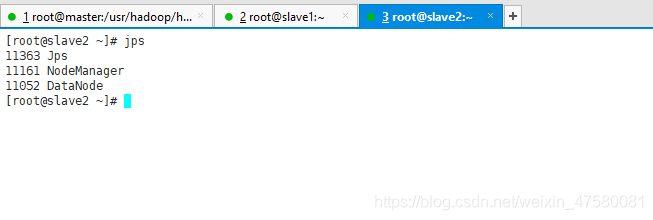
注意各个节点的进程区别!
如果各个节点的进程如上,那么你的hadoop完全分布式搭建完成!