What
大学里面学习数据库的时候,要求都是要按照三范式设计。但是在互联网高并发大数据量的场景下,往往要反范式设计。
Why
因为反范式的好处是可以通过冗余存储来减少计算。
How
引入一个例子:订单业务举例
- 订单业务
Order(oid, info_detail)//订单主表
T(buyer_id, seller_id, oid)//买家,卖家关系表 - 数据量大怎么办?
水平切分 - 如何水平切分?如何满足查询?
Order -> oid
T -> buyer_id, seller_id?
订单主表很容易切分(对oid进行取模即可),可是关系表T怎么办,如果按照买家的话,买家的读问题(只需要读一个库)是解决了,可是卖家读问题(需要读取多个库)解决不了。 - 解决方案:冗余表
解决什么问题?
a. 数据量大
b. 需要水平切分
c. 一个schema上有多个字段的查询需求
怎么解决?-
数据库层面:
a. Order(oid, info_detail)
b. T1(buyer_id, seller_id, oid)//买家读取数据的时候读这个表
c. T2(seller_id, buyer_id, oid)//卖家读取数据的时候读这个表 -
服务层面:
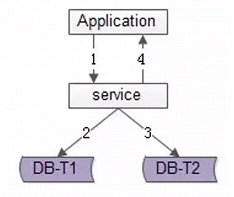
方案一:服务同步冗余
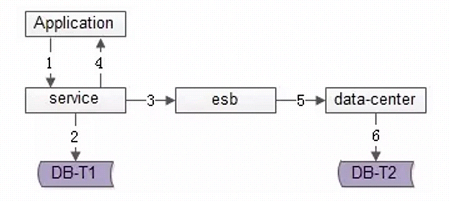
方案二:服务异步冗余
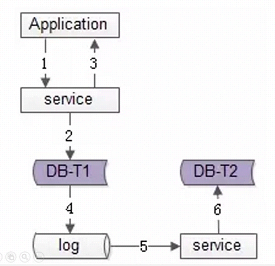
方案三:线下异步冗余:通过监控binlog日志(比如阿里的canal)
-
正表,反向标,如何确定操时序?比如新增一个订单是先insert T1表还是insert T2表
此问题延伸为:对于一个不能保证事务性的操作,“哪个任务先做,哪个任务后做”?
方法论:如果原子性被破坏,不一致出现,谁先做对业务的影响较小,就谁先执行。比如对T1和T2来说,如果先操作T1,那么买家是可以立即看到自己的订单,但是可能存在风险操作T2的时候没有成功,即卖家看不到这笔订单,影响程度较小;如果先操作T2,卖家可以立即看到自己的订单,但是可能存在风险操作T1的时候没有成功,即买家看不到这笔订单,影响程度较大(作为一个To C的应用,怎么能忍受C端的不良体验呢?)。所以最终的方案就是先执行T1,然后再操作T2。
-
如何保证一致性?
方法论:最终一致性
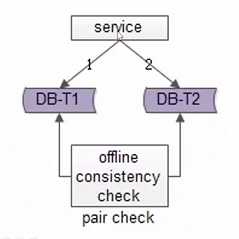
方案一:全量数据扫描:这个方案比较稳,可以作为兜底的方案,缺点是比较慢,难以做到实时性,一般一天做一次。
方案二:增量日志扫描:速度快,大部分场景用这个方案即可,可以一个小时做一次。
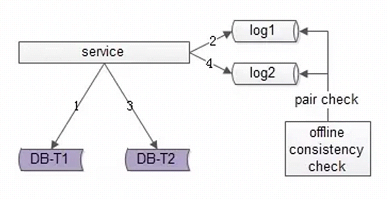
方案三:实时消息对检测:实时性最好,可以做到秒级别,除非是一些支付等对实时性要求高的,可以考虑这个方案。
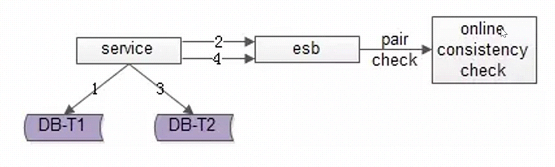
-