一、What
数据库模块可变更的能力叫做数据库扩展性。比如以下三个场景:
- 底层的表结构变更:比如新增两个字段。因为线上数据量一般都是比较大的,如果直接ALTER TABLE会锁表,线上服务会不可用。
- 水平分库的个数变化:比如两个水平分库变更为三个水平分库
- 底层存储介质变换:比如mongodb修改为mysql
二、Why
数据库扩展性是指随着产品的迭代,数据库可能也需要迭代变更。
三、How
方案一:离线迁移数据,数据库升级期间服务不可用。适用场景1、2、3。
- 发通告要升级服务
- 停止服务
- 数据变更
- 恢复服务
方案一劣势:
a. 只能支持可以支持长时间不可用的应用,比如游戏停服
b. 因为通告一般都会限定维护的时间段,对于开发,测试,运维有一定的压力,容易出错。如果万一出错,就需要回滚。
方案二:在线表结构变更,迁移期间最多有秒级的不可用。适用场景1。
pt-online-schema-change 或者叫online DDL,用于Mysql表结构变更;步骤如下:
- 新建一个新的临时表
- 旧表添加INSERT/UPDATE/DELETE触发器,数据修改同步到新表
- 把旧表数据迁移到新表
- 删除触发器,并把旧表迁移到别的地方
- 重命名新表为旧表名
Tips:
- 处理冲突,以触发器的最新数据为准,迁移数据一定要有主键
- 要新建触发器,所以要求原有表不要有很多触发器,否则影响性能,不过目前大部分互联网公司都不用触发器
- 要在低峰期迁移,因为触发器会影响性能
具体使用参考https://www.cnblogs.com/lkj371/p/11430265.html
方案三:追日志,适用场景2,3。
追日志方案,是一个高可用的平滑迁移方案。总共需要五大步骤:
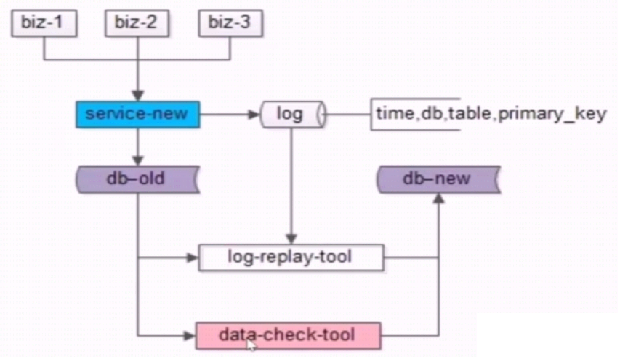
- 升级服务,添加日志写入:把所有修改数据的主键(增删改)记录下来,比如记录库+表+主键三个信息
- 数据迁移:旧库存量的数据同步到新库,比如旧库dump出来一个sql文件,然后在新库source
- 读取日志,插入到新的库:旧库一直对线上提供服务,数据是在变化的,一次静态的迁移肯定是不够的。需要开发一个data-replay-tool这样的小工具,来读取第一步的日志,从旧库读取最新的数据,同步到新库
- 检查一致性:需要开发data-check-tool,执行重放日志,我们还不能完全认为数据是一致的,需要做一致性检查。
- 流量迁移:完成上面四个步骤,我们便认为新库是可用的,可以用修改配置文件的方式,或者配置中心回调的方式来通知服务层有新的下游节点可以消费了
方案四:双写模式
双写模式,是另外一种高可用的平滑迁移方案。总共需要四个步骤:
-
升级服务,让服务同事操作新旧两库:
这里并不是把流量迁移到新库,新库执行数据库操作,affect rows是多少没有关系,不会影响服务,真正服务的还是旧库。 -
数据迁移:
data-migrate-tool,和追日志模式一样,同样需要进行数据迁移,但是不需要replay log。为什么不需要,因为提前进行了双写,所以数据是一致的,具体分析如下:
a. 在迁移中旧库中的数据依然在修改,这些修改新库和旧库会进行双写
b. insert操作,新旧都没有,那就是都insert成功
c. delete操作,如果是已经迁移过去的数据,那么大家都是delete,如果还没迁移,等到需要迁移的时候在旧库中它已经不存在了
d. update操作可以看做是delete和insert叠加扫描二维码关注公众号,回复: 11721875 查看本文章
极端情况:在数据迁移的过程中,正在迁移的段发生了删除或修改,那么就会出现数据不一致,所以还是需要数据一致性的检查。
-
一致性检查
以旧库为准,对新库进行检查,这一过程旧库依旧对线上提供服务,不影响。 -
流量迁移
完成上面三个步骤,我们便认为新库是可用的,可以用修改配置文件的方式,或者配置中心回调的方式来通知服务层有新的下游节点可以消费了。
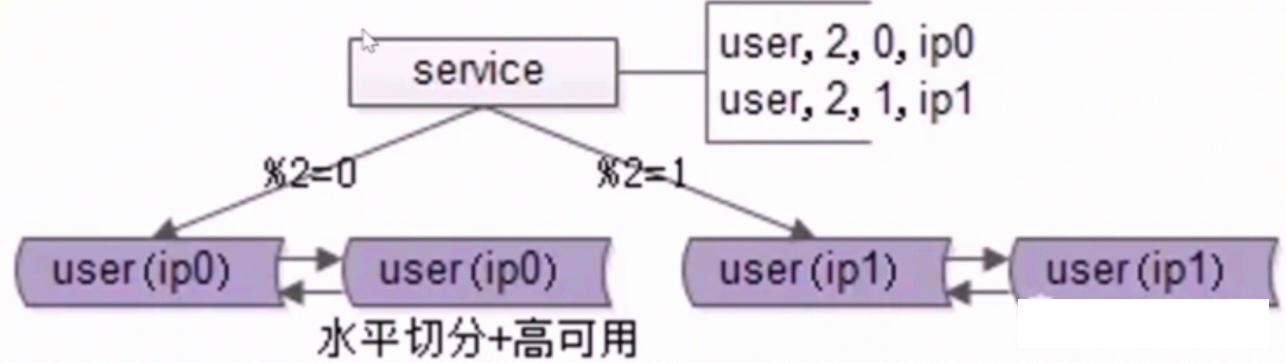
方案五:水平切分,数据库秒级扩容(比如从水平切分2个库,扩容为水平切分4个库)
典型的互联网微服务的数据库架构如下图所示,是一个高可用 + 水平切分的架构
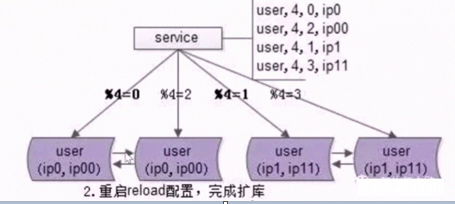
随着数据量的不断增大,我们需要持续的扩展,比如从原来的水平切分2个库,升级为水平切分4个库,怎么做到呢?答案就是秒级扩容的水平切分方案,此方案有两个限制,第一是切分是按照取模切分的;第二是扩容需要成倍的扩容。此方案总共需要三大步骤:
-
修改配置:主要是修改两个地方:
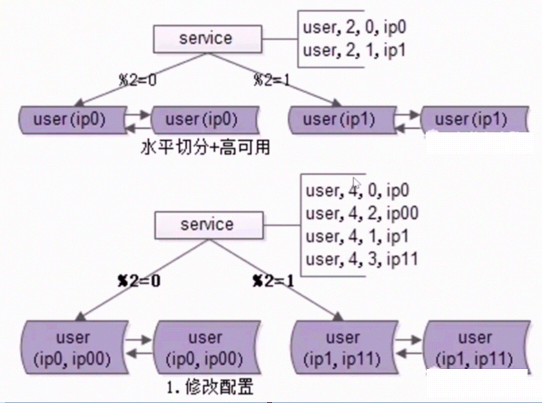
a. 单虚IP修改为双虚IP
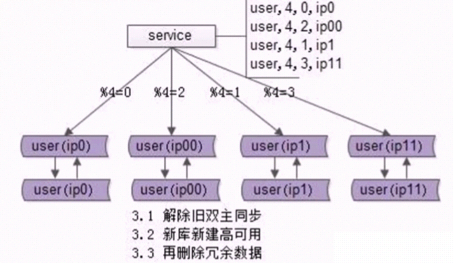
b. 修改service的配置,原来是模2,现在修改为模4。这个更新是无损的,因为原先走模2余0的还是到ip0,余1的还是到ip1,这不会变化 -
reload配置
微服务修改为配置还没有载入,不会生效,所以需要reload,理论上,reload之后我们的扩容就完成了。
reload前面提过,有两种方案:
a. 手动重启服务,让它载入新的配置,初始化连接池等
b. 配置中心通知服务让它自动重启载入配置
不管是哪种方案,reload这一过程都可以秒级完成,reload之后数据库实例从原来的两个对线上提供服务变为四个对线上提供服务。
- 数据收缩,收尾
完成reload之后,虽然提供服务的实例个数增加了,但是数据量并没有变化,这就需要收尾工作,进行数据收缩
数据收缩工作主要也是有两步:
a. 恢复高可用:
- 解除旧的双主同步,他们现在是平行结构了。
- 补充高可用,为4个新库分别建立四个备库,双主或者影子主
b. 删除不需要的数据
- 对四个库删除他们不需要的冗余数据,ip0的删除原先模4余2的数据,ip00删除原先模4为0的数据,ip1和ip1同理。