利用pandas对csv文件的读取、保存以及简单的操作
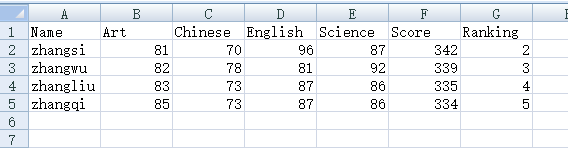
1、原始文件格式如下
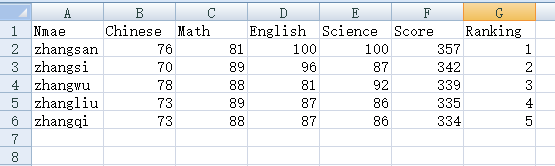
import pandas as pd
2、文件的读取
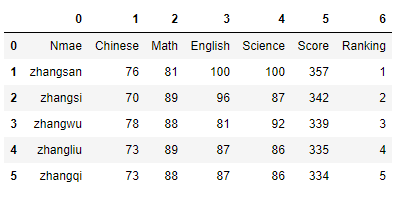
data = pd.read_csv('学生月考成绩表.csv',header = None) #header注明data是否包含有标题行
data
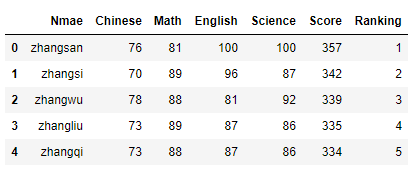
data = pd.read_csv('学生月考成绩表.csv') #header注明data是否包含有标题行
data
3、表格中数据的读取和更改
1)数据的读取以loc为例说明
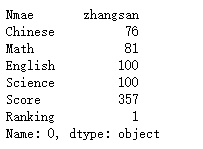
data.loc[0] #选取第0行元素
data.loc[0,'Math'] #选取第0行/第Math列元素

1)loc,基于列label,可选取特定行(根据行index);
2)iloc,基于行/列的position;
3)at,根据指定行index及列label,快速定位DataFrame的元素;
4)iat,与at类似,不同的是根据position来定位的;
5)ix,为loc与iloc的混合体,既支持label也支持position。参考自[1]
2)具体数值的修改
data.shape #获取数据DataFreme格式的大小

data.iat[0,6] = 100 #将数据的第0行第6列修改为100
data
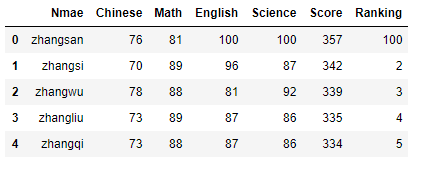
data.rename(columns={
'Nmae':'Name'},inplace=True) #修改列名称
data

4、 行和列的插入、删除
1)在最后一行新增
newrow = pd.DataFrame({
'Name':'lisi','Chinese':30,'Math':40,'English':50,'Science':60,'Score':70,'Ranking':6},index=[0]) #设置行标index=[0]
data = data.append(newrow,ignore_index=True)#忽略行标设置
data
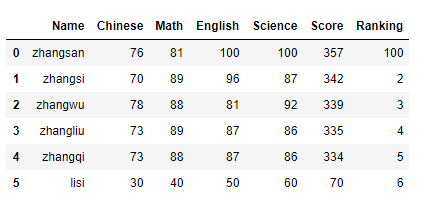
2)在指定位置修改行
data.loc[2] = ['wangwu',30,40,50,60,70,6] #修改第2行的值
3)在指定位置增加列
data.insert(1,'Art',[80,81,82,83,85]) #插入一列
data
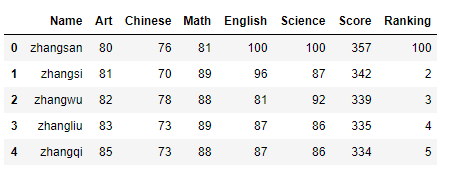
3)删除行或列
data.drop('Math', axis=1, inplace=True) #删除Math列,axis为1表示删除列,0表示删除行。inplace为True表示直接对原表修改。
data.drop(0, axis=0, inplace=True)#删除第0行,axis为1表示删除列,0表示删除行。inplace为True表示直接对原表修改。
data
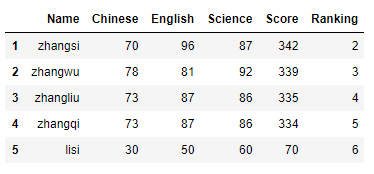
5、 表格中元素位置的索引
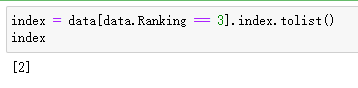
index = data[data.Ranking == 3].index.tolist()
index
6、 文件的保存
data.to_csv('student_score.csv',index=False) #index = False取消行名称,header = None则取消列名称
参考
【1】https://blog.csdn.net/grllery/article/details/81292085
【2】https://blog.csdn.net/huang_susan/article/details/80626698
【3】https://blog.csdn.net/u010801439/article/details/80033341