引言
琐碎的清理操作删除了每个数据发布中的所有准标识符或所有敏感属性,从而为那些对特定个人的知识仅限于其准标识符的对手提供了最大的隐私保护(该对手非常薄弱,但是在微数据中是标准的清理文献[10,22,34]。)
在本文中,我们提出一个基本问题:这些算法比普通的清理方法有什么好处?将广义的准标识符和敏感属性一起发布的唯一原因是支持考虑了清理后数据库中这两种属性的数据挖掘任务。我们本文的目标是评估数据挖掘效用的这种增量收益与发布准标识符和敏感属性所导致的隐私降低之间的权衡。
贡献
- 首先,我们给出敏感属性公开的语义定义。由于他观察了经过清理的数据集,因此可以捕获对手的知识。该定义适用于泛化和抑制框架。
- 其次,我们提供了一种方法,用于衡量隐私权损失与效用收益之间的权衡。隐私损失是指对手学习与给定身份相对应的敏感属性的能力的提高。效用增益是在经过清理的数据集上评估的机器学习任务的准确性的提高。
两者的基准都是经过简单处理的数据集,该数据集仅省略了所有准标识符或所有敏感属性,从而提供了最大的私密性和最小的实用性。
我们表明,非平凡的归纳和压制或者会导致较大的隐私泄露,或者与平凡的已清理数据集相比,提供的增量效用很小。因此,即使对手的知识仅限于准标识符,也必须销毁数据挖掘效用以仅获得边际隐私。为了防止具有辅助知识的对手,效用的损失必须更大。
相关工作
k匿名性的局限性是:
- (1)它不会隐藏给定个人是否在数据库中[26,30],
- (2)它揭示了个人的敏感属性[21,22],
- (3)它没有保护对抗基于背景知识的攻击[22,23],
- (4)仅使用k匿名化算法的知识会侵犯隐私[43],
- (5)如果不完全丧失实用性,就无法将其应用于高维数据[3] ,以及
- (6)如果数据集被匿名化并多次发布[7,37,40],则需要特殊方法。在[28]中提出与每个准标识符相关的敏感属性是“多样的”。这类似于p敏感度[36],L-多样性[22]和其他[39,42]。但是,敏感属性的多样性既不是必需的,也不是防止敏感属性泄露的充分方法(参见[21]和第4节)。
更强的定义出现在[24]中,但是尚不清楚是否可以在泛化和抑制框架中考虑的数据访问模型中实现。在k-匿名文献中,对手的知识仅限于年龄和邮政编码等准标识符。 [9,23]中考虑了具有背景知识的强大对手。我们的结果表明,即使对于只知道准标识符的弱势对手,泛化和抑制也不能保护隐私。隐私显然也不利于强大的对手。
本文是关于敏感属性公开的。成员资格披露,即了解给定的个人是否存在于经过清理的数据库中,是另一种不可比拟的隐私权属性。
我们假设只要为对手提供经过清理的表T ',记录行就会以随机顺序出现,以防止“未排序的匹配攻击” [34]。
敏感属性披露
当对手了解有关个人敏感属性的信息时,就会发生敏感属性泄露。这种侵犯隐私的形式是不同的,并且与了解个人是否包含在数据库中是无可比拟的,这是差分隐私的重点[12]。为了获得有意义的数据隐私定义,有必要量化对手从观察到的清理后的数据集中获得的敏感属性的知识。

我们将定义称为语义,因为它们捕获了对手知识的这种转变。随机扰动数据库已经很好地理解了隐私的语义定义需求(例如[13])。相比之下,对微数据隐私的研究集中在纯粹的语法隐私定义上,例如k-匿名和L-多样性(如下所述),它们仅考虑经过清理的数据库中的属性值的分布,而没有直接衡量对手可能学到的东西。
攻击模型
攻击模型我们使用文献[10,22]中的标准模型。向对手提供从原始表T生成的经过清理的表T ',以及已知已知在表T中的某些目标个人t的准标识符t [Q](即,我们不考虑成员资格披露)。我们再次强调,给对手更多的背景知识将导致比我们展示的还要糟糕的披露。
为了使清理过的数据库“真实” [31,34],泛化和抑制仅应用于具有敏感属性的准标识符。因此,使用此方法可能最“私密”的清理表是琐碎的清理,其中所有Q均被抑制。同样有效的是琐碎的清理,其中所有S都被抑制(并在单独的未链接表中释放)。
对手的基本知识Abase是他在进行任何清理后可以学习的有关敏感属性的最少信息,包括琐碎的处理,分别释放了准标识符和敏感属性。 Abase是原始表中敏感属性的分布,这可以通过任何归纳和抑制算法来揭示,因为不影响敏感属性以保持它们“真实”。我们担心超出此基础知识的隐私泄漏;例如,如果T中90%的个体患有癌症,那么如果对手得出t患有癌症的概率为90%,则不应将其视为属性披露,因为该基线分布始终向对手透露。我们正式将Abase定义为表示整个表T中敏感属性值分布的概率向量:
Abase = <p(T, s1), p(T, s2), . . . , p(T, sl)>.
对手的后验知识Asan是他从清理后的表T’中学习到的目标个体t的敏感属性。不像Abase,Asan考虑准标识符,对手可以识别目标所在等价类。Asan它是等价类t中的敏感属性值的分布。
Asan(< t >) =<p(< t >, s1), p(< t >, s2), . . . , p(< t >, sl)>
敏感属性公开是对手的后验知识Asan和他的基础知识Abase之间的区别。它可以相加或相乘地进行测量。
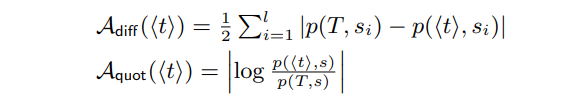
非正式地,它通过观察经过清理的准标识符来捕获对手所学到的知识,比他从“最大私有”数据库中学到的知识要多得多,在“最大私有”数据库中,敏感属性与准标识符是分开的。
语义隐私
为了获取由经过清理的表格T’导致的对手知识的增量增长,我们首先考虑如上所述的他的基准知识Abase。回想一下,它由表T中敏感属性的分布组成,其中所有准标识符都已被抑制(任何不涉及敏感属性的清理操作都必须显示T)。此外,对手知道所有t∈T的t [Q],即数据库中所有个人的准标识符属性值。对手可以轻松地从外部数据库和其他资源中学习这些值。
定义1(δ-披露隐私):对于一个等价类t,δ-披露隐私是指对于所有s∈S:
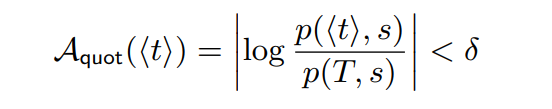
如果一个表是满足δ-披露隐私的,仅当表中所有等价类均满足δ-披露隐私。
直观地,如果每个准标识符类中敏感属性值的分布与它们在整个表中的分布大致相同,则该表是δ-disclosure私有的。与[21]相反,我们使用乘法定义。当敏感属性的某些值出现在某些准标识符类中而不出现在其他类中时,它可以正确地对披露进行建模。通过将δ参数与决策树分类器(如ID3和C4.5)使用的信息增益相关联,它也使我们能够得出对抗知识增益的界限。增益Gain(S,Q)定义为S的熵和条件熵H(S | Q)之间的差:
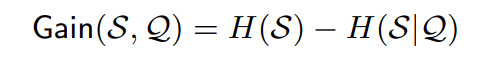
引理1.如果T满足δ披露隐私,则Gain(S,Q)<δ。

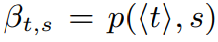
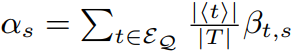
引理1表明,当数据库满足δ披露隐私时,基于准标识符Q建立敏感属性S的预测变量的能力受δ约束。请注意,定义1比引理1给出的边界更强,因为它要求分布Abase和Asan相似,而不是仅仅具有相似的熵。
句法隐私(Syntactic privacy)
- k-匿名:要求等价类的长度大于等于k。
- L-多样性:抵御同质性攻击。不必要,不足以抵御属性披露。仍会揭示许多概率信息。
确切地讲,它仍然可以显示很多概率信息。例如,考虑一个数据库,其中1%的人患有罕见的癌症,而准标识符等价类别< ti >,其中30%的人患有这种癌症(或多样性标准所要求的任何高百分比) 。如果对手的目标个人t∈< ti>,那么对手可以立即推断出他的目标比数据库中的随机个人更有可能患上这种癌症.
概率性属性披露与敏感属性的多样性无关。而是当敏感属性的整体分布与等价类中敏感属性的分布有差异时,就会发生概率敏感属性披露。假设对手知道整个表中敏感属性值的分布Abase,如果对手攻击的目标个体所在的等价类中敏感属性值分布不同于Abase,则会发生属性泄露。 - t-closeness:Asan分布与Abase分布的距离不超过阈值t。
如何度量分布距离
Earth Mover’s distance(EMD)等价于Adiff。这是相加(而不是相乘)的度量,并且不会直接转化为对手学习与给定准标识符相关的敏感属性的能力的界限。
即使t-closeness并不直接限制对手知识的获取,但其精神上与语义隐私相似。它也试图捕获对手的基准知识与他从已清理表格中的准标识符等价类中获得的知识之间的差异。当参数(分别为t和δ)接近0时,t-closeness和我们的定义1都收敛到经过清理的数据库中准标识符和敏感属性的统计独立性。
度量清理后的数据的隐私
语义隐私限制了一个隐私披露的界限。常规的隐私度量依赖于数据集的句法属性,像k-匿名,L-多样性。但是这两个指标是无法比拟的,例如,具有二进制敏感属性的1000条记录的数据库永远不能超过2个多样性,但它可以是最多1000个匿名数据库。
我们提出两种不同的指标来量化属性披露:
1.

Aknow代表“对抗性知识获取”。对手学习到的有关个体t的敏感属性的平均信息量,因为他能够根据t的准标识符识别出< t>类。
也可以考虑基于Aquot的度量,但是只有语义上私有的数据库才能获得有限的隐私评分。其他隐私定义允许某些准标识符类中不包含敏感属性值,从而使对手可以肯定地了解到相应的个人没有此值。
第二个指标量化了对手使用其最佳策略预测目标t的敏感属性的能力,即猜测< t>中最常见的敏感属性,对于等价类< t>,Smax(< t>)是其中最常见的敏感属性值
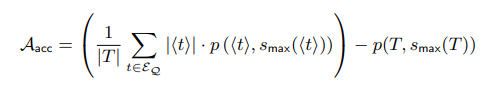
Aacc代表“对抗性准确度提高”,并在观察到经过清理的数据库T’与从T*中的基准准确度相比后测量对手的准确度的增长,这是可以通过泛化和抑制获得的最私有的数据库。
Aacc低估了经过清理的表T*泄漏的信息量,因为它不考虑非多数敏感属性的概率的变化。它仍然是一个有用的指标,因为它可以直接与我们的数据挖掘效用指标进行比较
效用度量
针对特定的上下文才有意义。
任何数据集的实用性(无论是否经过清理)都与人们可能对其执行的计算有着天生的联系。一种方法是最小化应用于准标识符属性的泛化和抑制量,以实现给定的隐私级别[10]。相对于绝对差,相对距离,最大分布或最小抑制来完成这种“最小化”。其他句法指标包括泛化步骤的数量,准标识符等价类的平均大小,类大小的平方和[22]和边际保留[16]。
使用相同的方法衡量隐私和实用性至关重要。否则,最大化效用可能会导致侵犯隐私权。
我们的目标是在一个框架中使用语义定义来衡量隐私和实用性之间的权衡:针对对抗性敏感属性披露而言的隐私性。