位置服务中基于贝叶斯的隐私泄露分析
背景知识反映了敌手收集背景知识的能力。敌手可以从真实世界中收集背景知识。
Worst-Case Background Knowledge for Privacy-Preserving Data Publishing
在数据发布中推理隐私时,有必要考虑攻击者的背景知识。然而,在实践中,数据发布者不知道攻击者拥有什么背景知识。因此,考虑最坏的情况是很重要的。本文发起了一个最坏情况背景知识的正式研究。
我们提出一种语言,可以表达关于数据的任何背景知识。我们提供了一个多项式时间算法来衡量在最坏情况下敏感信息的泄露量,假设攻击者在这种语言中最多有k条信息。我们还提供了一种有效清理数据的方法,以便在最坏的情况下披露的数据量小于指定的阈值。
本文中的目标是量化攻击者拥有的背景知识对披露量的精确影响,并提供算法来检查和确保披露量小于指定的阈值。
一般,像l-diversity和k-匿名对应相应的攻击者掌握的背景知识类型进行保护,但是,可能再有别的类型的背景知识,保护就失效,所以,需要一个更通用的框架,能够捕获攻击者可能知道的底层表的任何属性的知识。
可以量化具有K个这样的信息单元的攻击者所造成的最坏情况的泄露风险,k可以被认为是攻击者力量的束缚。
我们将展示
- 如何通过确保任何k条信息的最坏情况(即最大值)披露小于指定阈值来有效保护隐私。
- 还展示了如何将我们的技术集成到现有的框架中,以找到一个最大公开值小于指定阈值的“最小净化”表。
框架
- P是一组(有限的)人。对于每个p ∈ P
- S来表示敏感属性及其域
- 表T,它是一组对应于P子集的元组。
发布者希望以一种保护任何个人的敏感信息免受攻击者攻击的形式发布T。 - 攻击者拥有可以用语言L表达的背景知识。
两种净化方法
- 桶化:将T中的元组划分成桶,然后将敏感属性与非敏感属性分开。通过随机置换每个桶中的敏感属性值。净化后的数据由具有置换敏感值的桶组成。
- 全域泛化:将非敏感属性域粗化。经过清理的数据由粗化的表和使用的泛化组成。与bucketization不同,非敏感属性的确切值不会被释放;仅释放粗化的值。
如果攻击者知道表中的人员集合及其非敏感值,那么全域一般化和桶化是等价的。在本文中,我们使用桶化作为从原始表T构造发布数据的方法。
具体的桶化概念
给定表T,我们将元组划分成桶(即,根据一些方案水平划分表T),并且在每个桶内,我们对包含S值的列应用独立的随机排列。结果得到的一组桶,用B表示,然后发布。
如,如果底层表T如图1所示,那么发布者可能会发布如图3所示的B。


当然,为了增加隐私,发布者可以完全屏蔽识别属性(姓名),也可以部分屏蔽一些其他非敏感属性(年龄、性别、邮政编码)。
背景知识
我们悲观地假设攻击者有足够的时间来获得关于哪些个人在表中有记录。也就是说,我们假设攻击者知道每个b ∈ B的桶B中的人的集合Pb.
然后,考虑攻击者可能拥有的识别信息之外的知识。我们认为,这种进一步的知识是底层表满足表上给定谓词的知识。们认为,这种进一步的知识是底层表满足表上给定谓词的知识。这是一个相当普遍的假设。例如,“表中心脏病患者的平均年龄是48岁”可能就是这样一个前提。为了量化这种知识的力量,我们使用了知识的基本单位的概念,我们提出了一种由这种基本单位的有限连词组成的语言。给定完整的标识信息,我们希望表上的任何谓词都可以用我们提出的基本单元的连词来表示。我们使用非常简单的命题语法。
定义1(原子):
形式为tp[S] = s的公式。如:tJack[疾病] = flu,表示杰克的元组对于敏感属性疾病具有值flu。
语言中的基本知识单元是基本含义.
定义2(基本含义)
基本含义是形式的公式:

对于一些m ≥ 1,n ≥ 1和原子Ai,Bj,(注意我们用标准符号[n]来表示集合{0,.。。,n1 })。
基本含义是知识的一个充分表达的“基本单位”,这个事实通过下面的定理变得精确.
定理3(完备性)
给定完全识别信息和表上的任何谓词,人们可以用基本含义的有限连接来表示基本表满足识别信息和给定谓词的知识。
因此,我们可以模拟任意强大的攻击者。但同时,需要假设攻击者的力量是有限的。我们通过限制攻击者知道的基本含义的数量,用有限的能力对攻击者建模。也就是说,攻击者从下面定义的语言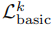 中知道一个公式。
中知道一个公式。
定义4
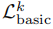
是由k个基本含义的连词组成的语言。也就是说,

因此,k可以被视为攻击者权力的界限,可以增加k以提供更保守的隐私保障。
请注意,我们对语言“基本单位”的基本含义的选择,对我们关于攻击者力量的假设有着重要的影响。尤其是,底层表的一些属性可能需要大量的基本含义来表达。由于基本含意本质上是至少有一个负原子的CNF分句,我们的语言在表达任意DNF公式所需的基本单位数上遭受了指数膨胀。尽管如此,许多自然类型的背景知识都有使用基本含义的简洁表达。
例如,爱丽丝的知识“如果汉娜有流感,那么查理也有流感”仅仅是基本含义.
Hannah[疾病] =流感→Charlie[疾病] =流感
“Ed没有流感”的知识是
TEd[疾病] =流感→TEd[疾病] =卵巢癌
一般来说,我们可以用(t[S] = s )→( t[S]= s′来表示t[S]= s的否定,对于s≠s′。
本文的贡献之一是我们提供了一个多项式时间算法来计算最大泄露,即使攻击者知道这种依赖关系。
披露
1.披露风险是最高度预测的敏感属性的可能性
2.最大限度的披露:相对于表达背景知识的语言,桶化的最大限度的披露

计算Pr(tp[S] = s|B∧ϕ),方法是考虑与桶化b和背景知识ϕ一致的所有表的集合,然后取满足tp[S] = s的那些表的分数。使用这一点,图3中关于桶的最大披露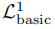 结果是10/19
结果是10/19
目标
我们的目标是开发通用技术,以便:
1.有效计算任何给定时段的最大披露,以及
2.有效地找到最大公开低于指定阈值(如果存在)的“最低限度净化”桶化(或所有最低限度净化的桶化的集合)。
检查和实施隐私
在第3.4节中明确“最低限度消毒”的概念;为了保持数据的实用性,我们需要“最小化的清理”。
我们现在展示如何有效地计算和限制对攻击者的最大泄露,该攻击者具有完整的身份信息和多达k个附加的背景知识(即,多达k个基本隐含)。
定义7(简单含意)简单含意是一些原子A,B的形式为A → B的公式。
请注意,k个简单的含义可以用2-CNF(合取范式)来写,对于它,可满足性很容易检查。


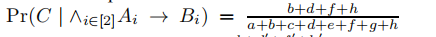
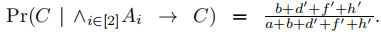
如何找阈值
有了计算最大披露的方法,我们现在展示如何有效地找到最大披露低于给定阈值的“最小化”桶化。直觉上,我们希望有一个最小的清理,以保持公布数据的效用。