文章目录
元数据和参数元数据以及利用反射
1.元数据
元数据(MetaData),即定义数据的数据。打个比方,就好像我们要想搜索一首歌(歌本身是数据),而我们可以通过歌名,作者,专辑等信息来搜索,那么这些歌名,作者,专辑等等就是这首歌的元数据。因此数据库的元数据就是一些注明数据库信息的数据。元数据的分类有如下几种:
- ① 由Connection对象的getMetaData()方法获取的是
DatabaseMetaData对象。 - ② 由PreparedStatement对象的getParameterMetaData ()方法获取的是
ParameterMetaData对象。 - ③由ResultSet对象的getMetaData()方法获取的是
ResultSetMetaData对象。
1.1、数据库的元数据信息DatabaseMetaData
DatabaseMetaData是由Connection对象通过getMetaData方法获取而来,主要封装了是对数据库本身的一些整体综合信息,例如数据库的产品名称,数据库的版本号,数据库的URL,是否支持事务等等,能获取的信息比较多,具体可以参考DatabaseMetaData的API文档。
以下有一些关于DatabaseMetaData的常用方法:
- getDatabaseProductName:获取数据库的产品名称
- getDatabaseProductName:获取数据库的版本号
- getUserName:获取数据库的用户名
- getURL:获取数据库连接的URL
- getDriverName:获取数据库的驱动名称
- driverVersion:获取数据库的驱动版本号
- isReadOnly:查看数据库是否只允许读操作
- supportsTransactions:查看数据库是否支持事务
测试代码:
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnect();
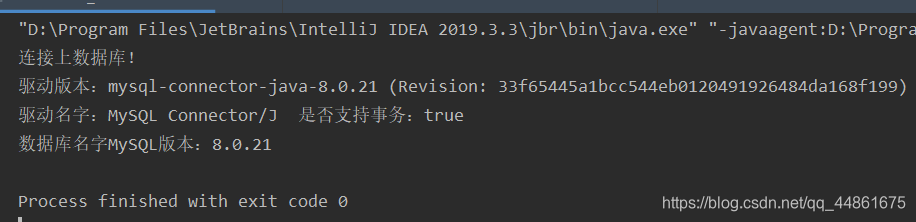
System.out.println("连接上数据库!");
DatabaseMetaData metaData = conn.getMetaData();//获取数据库的元数据信息,即基本的配置
System.out.println("驱动版本:"+metaData.getDriverVersion()+"\n驱动名字:"+metaData.getDriverName()+
"\t是否支持事务:"+metaData.supportsTransactions()+"\n数据库名字"+metaData.getDatabaseProductName()+
"版本:"+
metaData.getDatabaseProductVersion());
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.free(conn, ps, rs);
}
}
1.2、ParameterMetaData
ParameterMetaData是由PreparedStatement对象通过getParameterMetaData方法获取而来,主要是针对PreparedStatement对象和其预编译的SQL命令语句提供一些信息,比如像”insert into account(id,name,money) values(?,?,?)”这样的预编译SQL语句,ParameterMetaData能提供占位符参数的个数,获取指定位置占位符的SQL类型等等,功能也比较多,这里不列举完,详细请看有关ParameterMetaData的API文档。
在写JDBC的URL的时候,如果没有加上:
generateSimpleParameterMetadata=true
则使用ParameterMetaData的一些方法会报错:如getParameterClassName();
private static void params_Test(){
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnect();
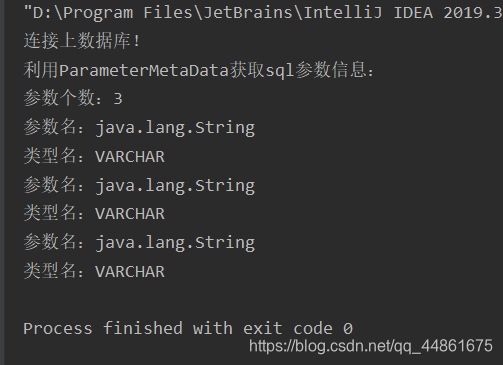
System.out.println("连接上数据库!");
System.out.println("利用ParameterMetaData获取sql参数信息:");
String sql = "select name,money from bank where name>? and id<? and money<?";
ps = conn.prepareStatement(sql);
ParameterMetaData pmds = ps.getParameterMetaData();
int count = pmds.getParameterCount();//获取参数的个数
System.out.println("参数个数:"+count);
for(int i=1;i<=count;i++){
System.out.println("参数名:"+pmds.getParameterClassName(i));
System.out.println("类型名:"+pmds.getParameterTypeName(i));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.free(conn, ps, rs);
}
}
Parameter metadata not available for the given statement

原因理解:
mysql驱动默认generateSimpleParameterMetadata=false,在传入null参数的时候,生成不了有效的元数据,因此才会报错。而我们这里使用占位符合没有将其设置值,所以默认为空,故产生错误。
但当我们赋值的时候,而generateSimpleParameterMetadata=false,还是会报错:
String sql = "select name,money from bank where name>? and id<? and money<?";
ps = conn.prepareStatement(sql);
ps.setString(1,"大壮");
ps.setInt(2,2);
ps.setFloat(3,100f);

下面我们不设置值,但是修改了generateSimpleParameterMetadata=true
jdbc:mysql://localhost:3306/test?serverTimezone=UTC&generateSimpleParameterMetadata=true
运行结果:
返回类型都是String,VARCHAR,原因是我们根本查数据库,源码里边直接返回的
public String getParameterClassName(int arg0) throws SQLException {
try {
if (this.returnSimpleMetadata) {
//简单的元数据以及设置为true了
this.checkBounds(arg0);
return "java.lang.String";//返回String
} else {
this.checkAvailable();
return this.metadata.getColumnClassName(arg0);
}
} catch (CJException var3) {
throw SQLExceptionsMapping.translateException(var3, this.exceptionInterceptor);
}
}
默认:上面的generateSimpleParameterMetadata=true修改为了true
boolean returnSimpleMetadata = false;
generateSimpleParameterMetadata=false时,下面的源代码说明了在传入null参数的时候,生成不了有效的元数据,因此才会报错。
private void checkAvailable() throws SQLException {
if (this.metadata == null || this.metadata.getFields() == null) {
throw SQLError.createSQLException(Messages.getString("MysqlParameterMetadata.0"), "S1C00", this.exceptionInterceptor);
}
}
getParameterTypeName源代码类似。
也就是说ParameterMetaData里面的方法,也就一个有用:
int count = pmds.getParameterCount();//获取参数的个数
1.3、ResultSetMetaData
ResultSetMetaData是由ResultSet对象通过getMetaData方法获取而来,主要是针对由数据库执行的SQL脚本命令获取的结果集对象ResultSet中提供的一些信息,比如结果集中的列数、指定列的名称、指定列的SQL类型等等,可以说这个是对于框架来说非常重要的一个对象。关于该结果集元数据对象的其他具体功能和方法请查阅有关ResultSetMetaData的API文档。
以下有一些关于ResultSetMetaData的常用方法:
- getColumnCount:获取结果集中列项目的个数
- getColumnType:获取指定列的SQL类型对应于Java中Types类的字段
- getColumnTypeName:获取指定列的SQL类型
- getClassName:获取指定列SQL类型对应于Java中的类型(包名加类名)
测试代码:
private static void read(String sql){
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnect();
System.out.println("连接上数据库!");
st = conn.createStatement();
rs = st.executeQuery(sql);
ResultSetMetaData rsMd = rs.getMetaData();//获取结果集的元数据
int count = rsMd.getColumnCount();//获取列的数量
System.out.println("列数:"+count);
Map<String,Float> data = new HashMap<>();
int j=0;
while (rs.next())
for(int i=0;i<count;i++){
data.put(rsMd.getColumnName(1)+j,rs.getFloat(rsMd.getColumnName(2)));
System.out.println(data);
j++;
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.free(conn, st, rs);
}
}
结果: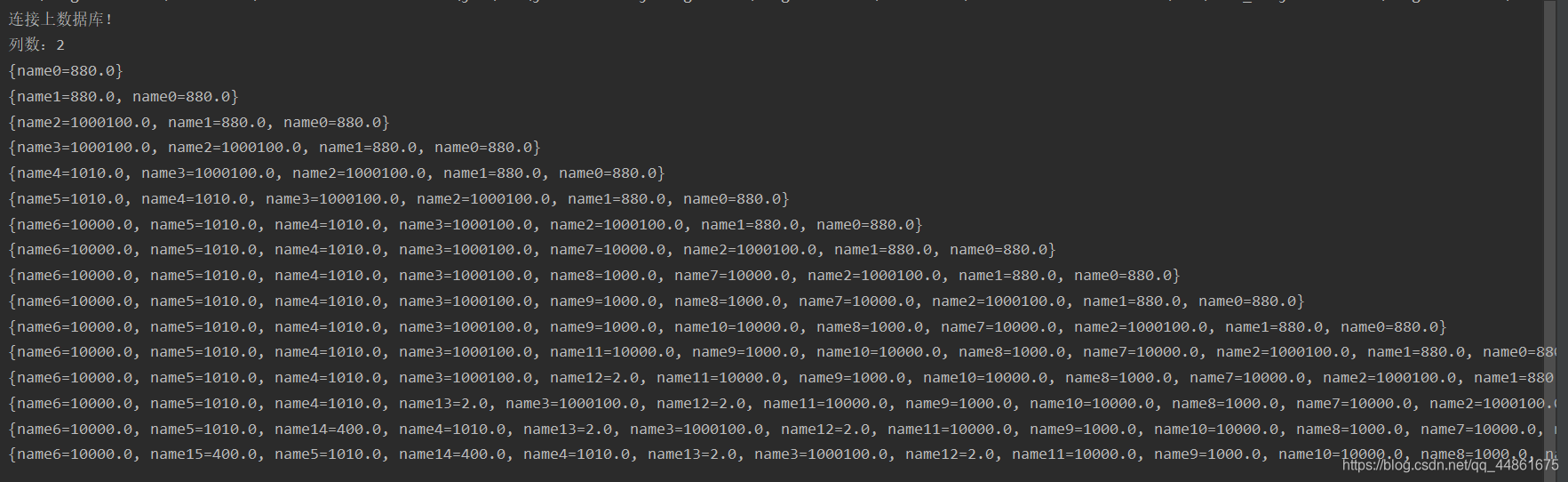
下面是其比较灵活的用法:
public class ResultParameter_MetaData {
public static void main(String[]args){
String sql="select name,money from bank where id<4";//不管查询的参数有多少个,都能运行
List< Map<String,Object>> listtMap = read(sql);
System.out.println(listtMap);
}
private static List< Map<String,Object>> read(String sql){
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnect();
System.out.println("连接上数据库!");
st = conn.createStatement();
rs = st.executeQuery(sql);
ResultSetMetaData rsMd = rs.getMetaData();//获取结果集的元数据
int count = rsMd.getColumnCount();//获取列的数量
System.out.println("列数:"+count);
String []columnNames = new String[count];//用于存放列名
for(int i=0;i<count;i++){
//columnNames[i]=rsMd.getColumnName(i+1);判断是别名还是原列名
columnNames[i]=rsMd.getColumnLabel(i+1);//如果没有别名,则别名默认为列名
}
for(String s:columnNames){
System.out.print(s);
}
//下面将读出来的数据存起来。
Map<String,Object> map;
List< Map<String,Object>> listMap = new ArrayList<>();
while(rs.next()){
map = new HashMap<>();//创建一个map
for(int i=0;i<count;i++){
//循环添加记录进去,把所有的列都加进去。
System.out.println(columnNames[i]);
map.put(columnNames[i],rs.getObject(columnNames[i]));//存放name的值
//第一列是name,第二行是money
}
listMap.add(map);//完成一行数据的保存。
}
return listMap;
} catch (SQLException e) {
e.printStackTrace();
return null;
} finally {
JDBCUtils.free(conn, st, rs);
}
}
}
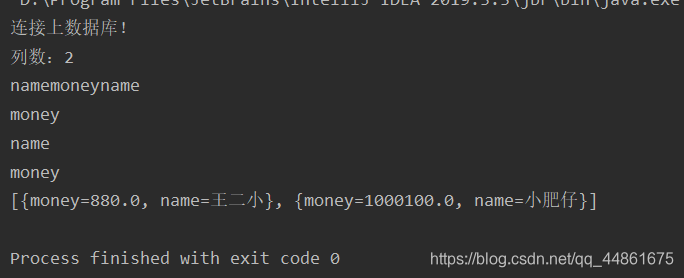
修改sql语句:
String sql="select name as A,money from bank where id<4";
结果:

因为A的哈希值<money的哈希值,所以其在前面。
public V put(K key, V value) {
return this.putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return key == null ? 0 : (h = key.hashCode()) ^ h >>> 16;
}
2、了解对象关系映射(ORM)
2.1、概念
对象关系映射(Object Relational Mapping,简称ORM)是通过使用描述对象和数据库之间映射的元数据,将面向对象语言程序中的对象自动持久化到关系数据库中。本质上就是将数据从一种形式转换到另外一种形式。 这也同时暗示着额外的执行开销;然而,如果ORM作为一种中间件实现,则会有很多机会做优化,而这些在手写的持久层并不存在。 更重要的是用于控制转换的元数据需要提供和管理;但是同样,这些花费要比维护手写的方案要少;而且就算是遵守ODMG规范的对象数据库依然需要类级别的元数据。
实际应用中即在关系型数据库和业务实体对象之间作一个映射,这样,我们在具体的操作业务对象的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了。ORM框架就是用于实现ORM技术的程序。常见的ORM框架有:
- Hibernate
- TopLink
- Castor JDO
- Apache OJB
- link to sql等
Java中ORM的原理:ORM的实现原理,其实,要实现JavaBean的属性到数据库表的字段的映射,任何ORM框架不外乎是读某个配置文件把JavaBean的属 性和数据库表的字段自动关联起来,当从数据库Query时,自动把字段的值塞进JavaBean的对应属性里,当做INSERT或UPDATE时,自动把 JavaBean的属性值绑定到SQL语句中。
一个简单的映射例子(hibernate),我们定义User对象和数据库中user表之间的关联,user表中只有两列:id和name:
<hibernate-mapping>
<class name="sample.orm.hibernate.User" table="user" catalog="test">
<id name="userID" type="java.lang.Integer">
<column name="id" />
<generator class="assigned" />
</id>
<property name="userName" type="java.lang.String">
<column name="name" />
</property>
</class>
</hibernate-mapping>
id建立映射到方法userID,类型Integer;属性name建立映射到userName,类型String
2.2、模拟ORM建立对象和数据库表的映射关系
建立User和数据库表bank的映射
bank表结构:

user对象类:
public class User {
private int id;
private String name;
private float money;
public User() {
}
public float getMoney() {
return money;
}
public void setMoney(float money) {
this.money = money;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@Override
public String toString() {
return "User [id=" + id + ", username=" + name + ", money=" + money + "]";
}
}
编写的实现ORM代码:
public static void main(String[] args) {
String sql = "select name,money from bank where id<4";
Object object = read(sql);
System.out.println(object);
}
private static Object read(String sql) {
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnect();
System.out.println("连接上数据库!");
st = conn.createStatement();
rs = st.executeQuery(sql);
ResultSetMetaData rsMd = rs.getMetaData();//获取结果集的元数据
int count = rsMd.getColumnCount();//获取列的数量
System.out.println("列数:" + count);
String[] columnNames = new String[count];//用于存放列名
for (int i = 0; i < count; i++) {
//columnNames[i]=rsMd.getColumnName(i+1);判断是别名还是原列名
columnNames[i] = rsMd.getColumnLabel(i + 1);
}
//建立ORM
User user = null;
Method[] methods;
if (rs.next()) {
user = new User();//无参构造器
for (int i = 0; i < count; i++) {
//循环添加记录进去,把所有的列都加进去。
String name = columnNames[i];
//因为我们的方法是规范方法,我们需要将name的开头字母大写
String re_name = name.substring(0,1).toUpperCase()+name.substring(1);
// System.out.println("name:"+name+" re_name:"+re_name);
String methodName = "set" + re_name;
//利用反射
methods = user.getClass().getMethods();//获取公有方法
for (Method m : methods) {
if (m.getName().equals(methodName)) {
m.invoke(user, rs.getObject(name));//寻找对应的方法,并调用
}
}
}
}
return user;
} catch (SQLException | IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
return null;
} finally {
JDBCUtils.free(conn, st, rs);
}
}
运行结果:

下面提高灵活性和降低代码的耦合性:
private static <T>T read(String sql,Class<T> clazz) {
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnect();
System.out.println("连接上数据库!");
st = conn.createStatement();
rs = st.executeQuery(sql);
ResultSetMetaData rsMd = rs.getMetaData();//获取结果集的元数据
int count = rsMd.getColumnCount();//获取列的数量
System.out.println("列数:" + count);
String[] columnNames = new String[count];//用于存放列名
for (int i = 0; i < count; i++) {
//columnNames[i]=rsMd.getColumnName(i+1);判断是别名还是原列名
columnNames[i] = rsMd.getColumnLabel(i + 1);
}
//建立ORM
T object = null;
Method[] methods;
if (rs.next()) {
object = clazz.getDeclaredConstructor().newInstance();//默认有无参构造器,这是约定
for (int i = 0; i < count; i++) {
//循环添加记录进去,把所有的列都加进去。
String name = columnNames[i];
//因为我们的方法是规范方法,我们需要将name的开头字母大写
String re_name = name.substring(0,1).toUpperCase()+name.substring(1);
// System.out.println("name:"+name+" re_name:"+re_name);
String methodName = "set" + re_name;
//利用反射
methods = clazz.getMethods();//获取公有方法
for (Method m : methods) {
if (m.getName().equals(methodName)) {
m.invoke(object, rs.getObject(name));//寻找对应的方法,并调用
}
}
}
}
return object;
} catch (SQLException | IllegalAccessException | InvocationTargetException
| NoSuchMethodException | InstantiationException e) {
e.printStackTrace();
return null;
} finally {
JDBCUtils.free(conn, st, rs);
}
}
我们新建立一个Bean类:
public class Bean {
private String name;
public Bean() {
//无参构造
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Bean{" +
"name='" + name + '\'' +
'}';
}
}
测试代码:
public static void main(String[] args) {
String sql = "select name,money from bank where id<4";
Object object = read(sql,Bean.class);
System.out.println(object);
}
结果:
也就是说我们摆脱了需要指定某个类的这个约束。但是代码可读性降低。