文章目录
修改事务隔离级别和调用存储过程
1、事务隔离级别
1.1、回顾事务的隔离级别
对于同时运行的多个事务,当这些事务访问数据库中相同的数据时,如果没有采取必要的隔离机制,就会导致各种并发问题:
-
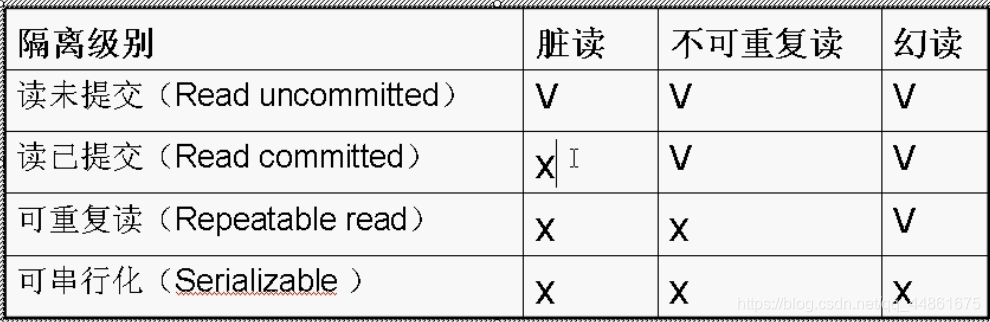
脏读: 对于两个事物T1, T2, T1读取了已经被T2更新但还没有被提交的字段。之后, 若T2回滚,T1读取的内容就是临时且无效的。
-
不可重复读: 对于两个事物 T1, T2, T1 读取了一个字段, 然后T2更新了该字段.之后, T1再次读取同一个字段,值就不同了。
-
幻读: 对于两个事物T1, T2, T1 从一个表中读取了一个字段,然后 T2在该表中插入了一些新的行。之后, 如果T1再次读取同一个表,就会多出几行.
因此才需要数据库事务拥有隔离性: 数据库系统必须具有隔离并发运行各个事务的能力,使它们不会相互影响, 避免各种并发问题。
一个事务与其他事务隔离的程度称为隔离级别.数据库规定了多种事务隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高, 数据一致性就越好, 但并发性越弱。不同数据库支持的隔离级别不一定相同。
关于隔离级别可能导致的问题如图所示:
具体事务的解析:MySQL学习日记(五)MySQL事务和字符集
1.2、修改事务隔离级别测试
环境:MySQL8.0.21+Java11.1+MySQL-JDBC驱动
package IsolationAndProcess;
import driver.JDBCUtils;
import java.sql.*;
public class Isolation_test {
public static void main(String[]args){
read();
}
private static void read(){
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try{
conn = JDBCUtils.getConnect();
//设置隔离级别
conn.setTransactionIsolation(Connection.TRANSACTION_READ_UNCOMMITTED);
//这里的事务级别类型是int类型,但并不是所有的都能调用,必须对应的数据库支持。
st = conn.createStatement();
System.out.println("连接上数据库!");
String sql = "select * from bank";//查看表所有的数据
rs = st.executeQuery(sql);
while(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
float money = rs.getFloat("money");
System.out.printf("%d\t%s\t%.4f",id,name,money);
System.out.println();
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtils.free(conn,st,rs);
}
}
}
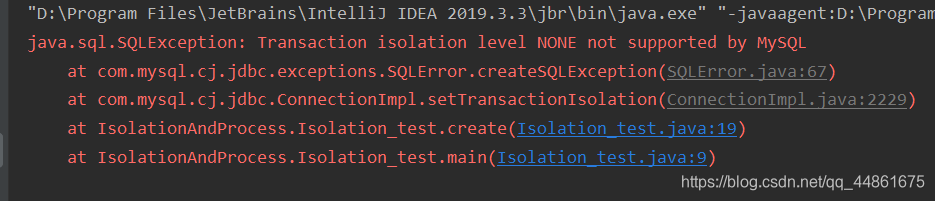
注意:MySQL支持4种隔离级别。JDBC里的隔离级别并非所有都能调用。如:

conn.setTransactionIsolation(Connection.TRANSACTION_NONE);//该隔离级别MySQL不支持
JDBC里面的定义的隔离级别:
2、存储过程
2.1、存储过程
存储过程我通常理解为编程里边的方法、函数。
MySQL 5.0 版本开始支持存储过程。
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
优点
- 存储过程可封装,并隐藏复杂的商业逻辑。
- 存储过程可以回传值,并可以接受参数。
- 存储过程无法使用 SELECT 指令来运行,因为它是子程序,与查看表,数据表或用户定义函数不同。
- 存储过程可以用在数据检验,强制实行商业逻辑等。
缺点
- 存储过程,往往定制化于特定的数据库上,因为支持的编程语言不同。当切换到其他厂商的数据库系统时,需要重写原有的存储过程。
- 存储过程的性能调校与撰写,受限于各种数据库系统。
早期的业务逻辑是两层架构,数据库上面业务实现就是存储过程的实现,用于处理业务逻辑。而后来的三层架构模式,使用了java等编程语言,配合一些驱动来实现业务逻辑。进而代替了存储过程的位置。所以存储过程就比较少用了。也因为存储过程实现依赖特定的数据库,不同的数据库存储过程存在差异,导致其无法实现灵活的业务逻辑。
2.2、调用存储过程
下面我们定义一个存储过程,用于获取指定用户的银行账户财产。
创建的存储过程:
DELIMITER $$
create procedure getNameByMoney(Out Costumer_Money float,in Costumer_name varchar(20))
begin
select money into Costumer_Money from bank where name=Costumer_name;
end;
$$
DELIMITER ;
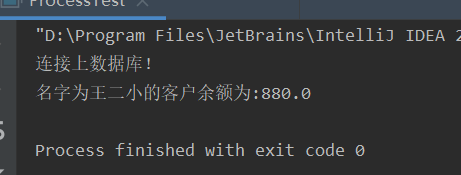
调用存储过程查询王二小的银行账号余额:
package IsolationAndProcess;
import driver.JDBCUtils;
import java.sql.*;
public class ProcessTest {
public static void main(String[] args) {
getMoneyByName("王二小");
}
/**
* 通过用户的名字获取其财产
*
* @param name
*/
private static void getMoneyByName(String name) {
Connection conn = null;
CallableStatement cs = null;//继承自PreparedStatement,故用法类似于PreparedStatement
ResultSet rs = null;
try {
conn = JDBCUtils.getConnect();
System.out.println("连接上数据库!");
String sql = "{call getNameByMoney(?,?)}";
cs = conn.prepareCall(sql);
//需要注册存储过程输出参数,注明其类型
cs.registerOutParameter(1, Types.FLOAT);
//设置占位符参数
cs.setString(2, name);
float money = 0f;
cs.executeQuery();//执行存储过程
money = cs.getFloat(1);//1表示占位符位置,必须对应参数类型
System.out.println("名字为" + name + "的客户余额为:" + money);
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.free(conn, cs, rs);
}
}
}
3、一些重要的API学习
3.1、获取主键,getGeneralKeys()
public ResultSet getGeneratedKeys() throws SQLException {
try {
if (this.wrappedStmt != null) {
return this.wrappedStmt.getGeneratedKeys();
} else {
throw SQLError.createSQLException(Messages.getString("Statement.AlreadyClosed"), "S1009", this.exceptionInterceptor);
}
} catch (SQLException var2) {
this.checkAndFireConnectionError(var2);
return null;
}
}
有时候我们需要动态获取插入数据的主键。故测试代码如下:
package SomeAPI;
import driver.JDBCUtils;
import java.sql.*;
public class GetKey {
public static void main(String[] args) {
getKeys();
}
private static void getKeys() {
Connection conn = null;
PreparedStatement ps = null;//继承自PreparedStatement,故用法类似于PreparedStatement
ResultSet rs = null;
try {
conn = JDBCUtils.getConnect();
System.out.println("连接上数据库!");
String sql = "insert into bank(name,money) values('大壮',1000)";
ps = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);//规范写法,表明可以获取主键,有一些数据库你不写也能运行,有些则不行,会报错。
//ps = conn.prepareStatement(sql);
ps.executeUpdate();
rs = ps.getGeneratedKeys();//因为主键不一定只有一列构成,可以为都多列,故为结果集类型。
while (rs.next()) {
//我们这里知道它只有一列:id
int id = rs.getInt(1);
System.out.println("id:" + id);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.free(conn, ps, rs);
}
}
}
运行:
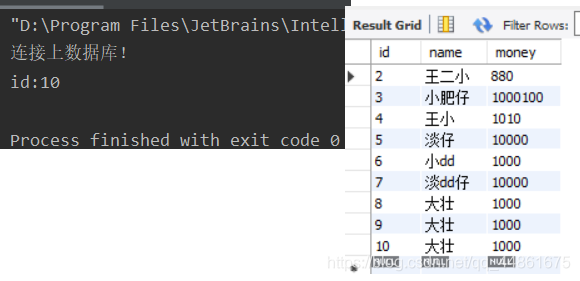
如果修改代码为:
ps = conn.prepareStatement(sql);
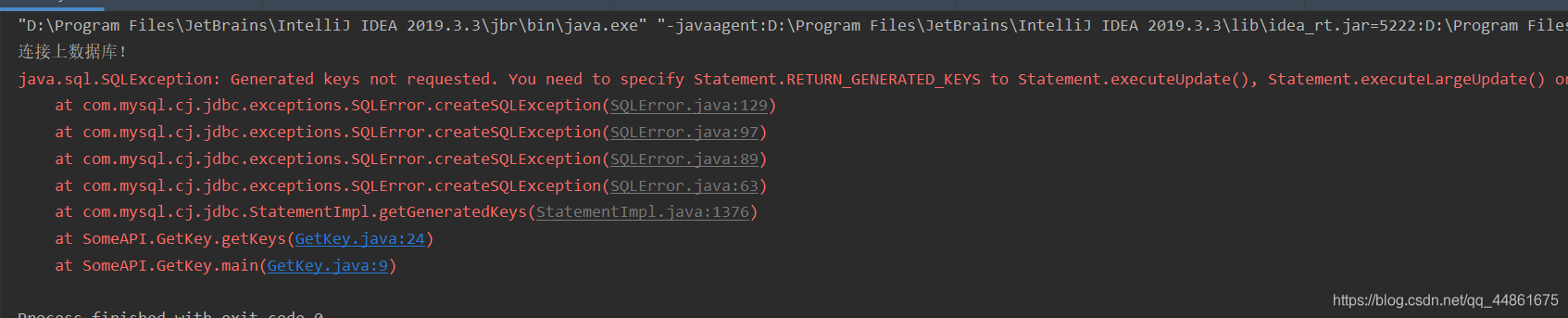
运行会报错,说明Mysql8.0.21要求Statement.RETURN_GENERATED_KEYS。
用途:
修改前面博客的DAO设计,addUser方法没有给user类的id赋值。
public void addUser(User user) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try{
conn = JDBCUtils.getConnect();
String sql = "insert into bank(name,money) Values(?,?)";
ps = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
ps.setString(1,user.getName());
ps.setFloat(2,user.getMoney());
ps.executeUpdate();
//添加代码,插入一个user,就自动生成一个主键id,将其赋值给user。
rs = ps.getGeneratedKeys();
while(rs.next()){
int id = rs.getInt(1);
user.setId(id);
}
} catch (SQLException e) {
throw new DaoException(e.getMessage());//千万不能随便打印堆栈跟踪或者抛出编译时异常
//不利于将来的换其他数据库或者要修改各个接口。不知道那里出了问题。
}finally {
JDBCUtils.free(conn,ps,rs);
}
}
测试代码:
public static void main(String[]args){
//System.out.println(DaoFactory.class.getClassLoader().getResource("/"));
User user = new User();
user.setName("黄天霸");
user.setMoney(10900.0f);
Dao daoImpl = DaoFactory.getInstance();
daoImpl.addUser(user);
System.out.println(user.toString());
}
运行结果:
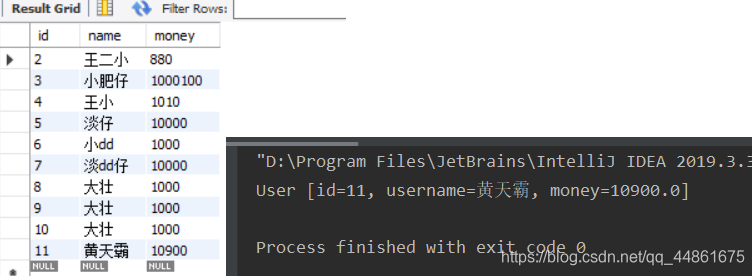
3.2、批处理命令
addBatch()和executeBatch()
package SomeAPI;
import driver.JDBCUtils1;
import java.sql.*;
/**
* 批处理命令
* 如一次插入40个数据
*/
public class AddBatch_Test {
public static void main(String[] args) {
insert_Batch();
}
private static void insert_Batch() {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
System.out.println("connect to database....");
conn = JDBCUtils1.getInstance().getConnect();
System.out.println("create statement...");
String sql = "insert into test_user(name) value(?)";
ps = conn.prepareStatement(sql);
for (int i = 0; i < 40; i++) {
ps.setString(1, "name" + i);
ps.addBatch();//打包,处理
}
ps.executeBatch();//运行批处理命令
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils1.getInstance().free(conn, ps, rs);
}
}
}

效率上,我们不用批处理命令和用批处理命令插入相同条数的数据,比较快慢如下:
//批处理
for (int i = 0; i < 40; i++) {
ps.setString(1, "name_batch" + i);
ps.addBatch();//打包,处理
}
ps.executeBatch();//运行批处理命令
//不用批处理
for (int i = 0; i < 40; i++) {
ps.setString(1, "name" + i);
ps.executeUpdate();
}
批处理快了35%
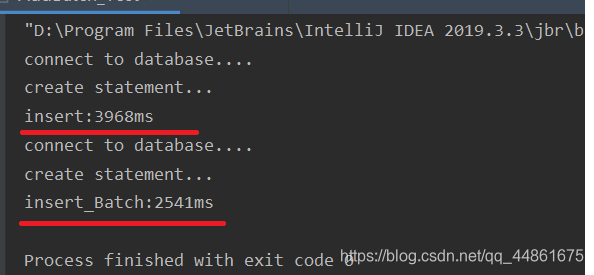
解释:Update大量的数据时, 先Prepare一个INSERT语句再多次的执行, 会导致很多次的网络连接.编译多次的SQL语句。而 要减少JDBC的调用次数改善性能, 你可以使用PreparedStatement的AddBatch()方法一次性发送多个查询给数据库. 这个Batch分批处理,超级多命令条数则分成几批。加快效率。
关于jdbc批量操作(addBatch, executeBatch)的测试
3.3、可滚动的结果集和分页技术
当我们需要对结果集中数据,进行定位查询。可以使用可滚动的结果集。

测试代码:
package SomeAPI;
import driver.JDBCUtils1;
import java.sql.*;
/**
* 可滚动的结果集:
*/
public class Result_Scroll {
public static void main(String[]args){
result_scroll();
}
private static void result_scroll(){
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
System.out.println("connect to database....");
conn = JDBCUtils1.getInstance().getConnect();
System.out.println("create statement...");
String sql = "select * from bank where id<10";
//设置可滚动的结果集,SCROLL,SENSITIVE表示:对数据库的数据修改敏感,可以感知。
st = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_READ_ONLY);
rs = st.executeQuery(sql);
while(rs.next()){
System.out.println("id:"+rs.getInt("id")+" name:"+rs.getString("name")
+" money"+rs.getFloat("money"));
}
System.out.println("--------");
if(rs.previous())//往前面滚动
{
System.out.println("id:"+rs.getInt("id")+" name:"+rs.getString("name")
+" money"+rs.getFloat("money"));
}
rs.first();//直接回到第一条数据
System.out.println("id:"+rs.getInt("id")+" name:"+rs.getString("name")
+" money"+rs.getFloat("money"));
/* rs.last();//最后一条
rs.beforeFirst();//第一条的前面,结果集的初始态
rs.afterLast();//最后一条数据后面
rs.isAfterLast();//boolean,判断是否位于末尾*/
rs.absolute(5);//直接回到第五行数据,绝对定位行号
System.out.println("id:"+rs.getInt("id")+" name:"+rs.getString("name")
+" money"+rs.getFloat("money"));
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils1.getInstance().free(conn, st, rs);
}
}
}
运行不会报错。
但是如果修改部分代码如下:
st = conn.createStatement();//不显式说明可滚动的结果集
报错:结果集类型为只能向前读。不允许previous等操作。也就是说不同的数据库提供的驱动实现默认的结果集类型可能不同。

利用可滚动的结果集,我们可以做到对数据进行分页读取。但是MySQL内部支持了分页技术。而且直接使用可滚动的结果集来进行数据分页,当数据量多时,效率低下。
MySQL的分页技术
利用SQL关键字 LIMIT ,如Limit 10,5;从第五条记录开始,查询10条。
方法1: 直接使用数据库提供的SQL语句
- 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N。
- 适应场景: 适用于数据量较少的情况(元组百/千级)。
原因/缺点: 全表扫描,速度会很慢 且 有的数据库结果集返回不稳定(如某次返回1,2,3,另外的一次返回2,1,3)。Limit限制的是从结果集的M位置处取出N条输出,其余抛弃。
方法2: 建立主键或唯一索引, 利用索引(假设每页10条)
- 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) LIMIT M。
- 适应场景: 适用于数据量多的情况(元组数上万)。
原因: 索引扫描,速度会很快。有朋友提出因为数据查询出来并不是按照pk_id排序的,所以会有漏掉数据的情况,只能方法3。
方法3: 基于索引再排序
- 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M。
- 适应场景: 适用于数据量多的情况(元组数上万). 最好ORDER BY后的列对象是主键或唯一所以,使得ORDERBY操作能利用索引被消除但结果集是稳定的(稳定的含义,参见方法1)。
详情请参考博客:MySQL的分页技术总结
3.4、可更新的结果集和敏感结果集
可更新的结果集:是指我们在查询得到的数据ResultSet后,可以按照需求对里面的数据进行修改,进而修改数据库的数据。
//设置可滚动更新的结果集
st = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_UPDATABLE);
rs = st.executeQuery(sql);
while(rs.next()){
String name = rs.getString("name");
if("大壮".equals(name)){
rs.updateFloat("money",400);//把大壮的钱修改为400块
}
rs.updateRow();//更新数据
System.out.println("id:"+rs.getInt("id")+" name:"+name
+" money"+rs.getFloat("money"));
}
敏感结果集:当我们修改数据库的时候,之前获取的数据集能够感知到修改的数据,并将其读取出来。(不好。)
- ResultSet.TYPE_SCROLL_SENSITIVE,int类型,值为1005
- ResultSet.TYPE_SCROLL_INSENSITIVE,int类型,值为1004
测试代码:设置为数据集,然后,在数据库服务端修改id为8的数据。
st = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_UPDATABLE);
rs = st.executeQuery(sql);
int i=0;
while(rs.next()){
Thread.sleep(10000);//睡眠10秒
System.out.println("show:。。。。"+i);
i++;
String name = rs.getString("name");
System.out.println("id:"+rs.getInt("id")+" name:"+name
+" money"+rs.getFloat("money"));
}
//
如图,左边是读取的数据,当读到id=5时,如右图,将id=8的大壮的数据money改为2,但是并没有读出2,还是原来的1块钱。说明MySQL该JDBC驱动不支持敏感数据集。怕破坏业务逻辑性。
