震惊 原来5.5k月薪的你也能 优化千万级大表分页
前言
书接上文 震惊 原来5.5k月薪的你也能优化千万级mysql
本文纠正、确认下来前文的几点问题,并详解分页机制的优化操作
■ 任务
慢sql优化改造,大表数据分页机制性能改造 ,提升大数据查询速度
解疑前文
下文皆为innodb的btree索引
■ 1.查询优化器什么时候选择不走范围索引?
前文表述:
不走索引更快时,查询优化器选择不走索引。时间范围就是一个例子,有说选择性小于17%时就不走了,具体未验证,我是有试过时间范围大到一定时不走索引,但我强制让它走索引时,速度还会快挺多,所以我这个表述也不是很准确。
纠正、解答:
mysql查询优化器会根据查询成本模型估算它认为的最优执行计划。这部分比较复杂,会有很多神操作,但可以确定的是——查询优化器选择的是估算成本方案中最优的执行计划(它不一定会比较完所有方案,所以有时候不会是最优解),而不是选择查询速度最快的方案,更不是单纯多大范围不走。
看下面的一个例子:
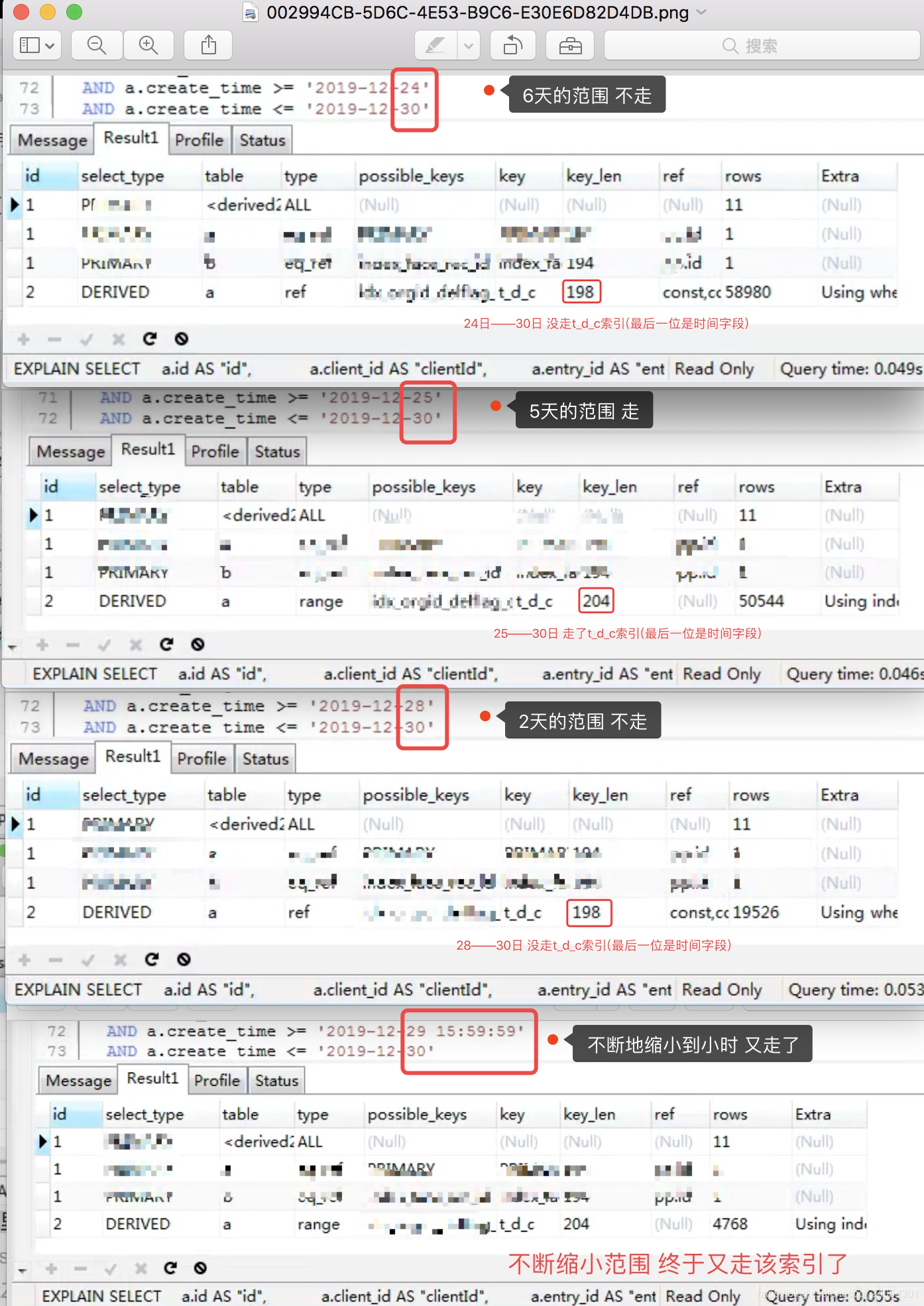
上图中的t_d_c索引有区别的,我称之为索引串味,后面会讲。可以通过key_len来区分,204的那个才是真正的t_d_c索引,它的最后一位是时间范围索引。在sql不干扰索引使用的情况下,通过调整时间范围,由广不断缩小范围可以发现,范围索引不生效->生效->不生效->生效。
所以很多广为流传的说法都是不对的。
选择性小于17%不走 ,错。这个是某个人由特定sql得出的结论,帖子被爬虫不断复制,然后看得人多了,再不断传播,从而有了一定影响,错错错。
范围大到一定范围它不会走范围索引 ,错。这个说法就谨慎很多,他不讲出特定值,不过还是错。
在抖音上有看到一个直播面试,面的是高级Java开发,问:范围索引都会生效吗?面试者反应也很快,回答:这个不一定会生效,范围索引大到一定范围就就不走索引了,这个值有可能是40%这样,超过了就不走了。 然后面试官也很满意。呃~。。。现在我可以告诉你这个说法是错误的,当然范围的大小肯定是有和这个优化器的选择挂钩的,但绝不是唯一因素,
所以,mysql查询优化器是根据查询成本模型估算它认为的最优执行计划,判断范围索引走不走是一个复杂的操作。如果你操作得当,就是100年的时间范围,它都会走索引。
■ 2.explain测出来的key有可能不是真实走的索引
前文我说到这种情况:explain测出来的key有可能不是真实走的索引,那它走的是嘛玩意呢?我之前称之为多个索引互相串味。多个索引相互串味,嗯?这是不是和索引合并有点类似。
索引合并:
1、索引合并是把几个索引的范围扫描合并成一个索引。
2、索引合并的时候,会对索引进行并集,交集或者先交集再并集操作,以便合并成一个索引。
3、这些需要合并的索引只能是一个表的。不能对多表进行索引合并。
如果使用了索引合并,那么在输出内容的type列会显示 index_merge,key列会显示出所有使用的索引
呃。。我随便搜了个介绍,非常官方。说白了就是索引建的不合理,mysql对多个单列索引进行了合并使用,就叫索引合并,并且执行计划是可以看出index_merge。
索引合并是针对单列索引的,打破脑袋也是想不到mysql会对组合索引下手,并且执行计划不会告诉你它到底干了啥,丧心病狂啊。前一点的图片可以看到索引串味的情况,可以看到的是,它的key列都是同一个索引。
辨别的方法,看key_len列就可以进行区分,长度是不一样的。然后通过在sql 表名后面加 ignore index(索引a,索引b…)操作就可以找出究竟是哪个索引影响了你考清华。很快就能找到,再通过force index(索引)强制走那个索引,你有可能会发现索引串味时走的也并非是这个索引,所以我才称之为索引串味,而不是索引变味,变成某一个。
解决方案:
来自《高性能mysql第三版》的一段话,我并不认可

如果优化器走错了路导致我们的查询卡着不动肯定是不行的,也是必须解决的,不能因为未知的麻烦而害怕优化。
①删除掉无用的索引。
②又或者sql语句使用ignore index、force index、use index,再通过mybatis标签指定哪些索引可以供它选择,这个方法是相当灵活的,不影响旧索引,只针对具体sql,具体条件。
(force和use的区别 :force 是只要有索引字段能对应的上查询字段,它就肯定走。use 是查询优化器认为全表扫描更快,他就不会走)
■ 3.强调一遍索引最左前缀原则
这是一件很有意思的事件。博主认证为博客专家,写的是一篇mysql的索引介绍,博主通过面试官提问为引子,讲解了索引,广受好评,收藏量将近1000,而下图中的勇士是一个博客新人。

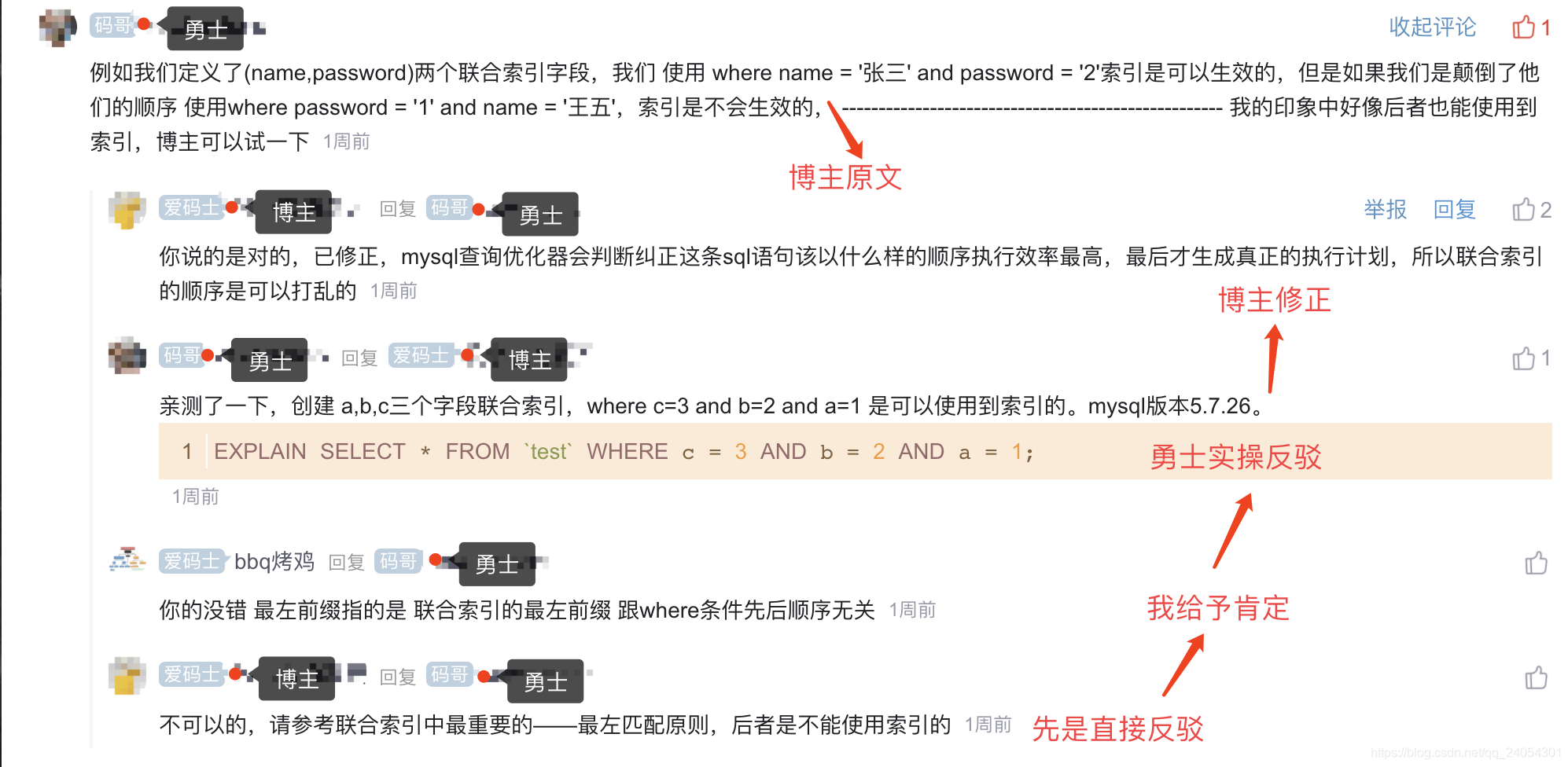
最左原则都不明白的话,几乎可以认定你没有真实的调优经验(复合索引),但是博主有博客专家认证加成,看些理论书,总结些套话,不明白索引的人就不会去怀疑他的说法,带来的影响力是非常可怕的。仅仅收藏量就将近1000,这种错误的观点流传开来不可想象。因为我以前对索引最左原则的认知就和博主一样,所以对这个错误观点比较上心,但是我不懂不会去传播,也没有能力去传播(这是重点),O(∩_∩)O哈哈~。
博客专家的反驳很有可能会让一个新人怀疑人生,放弃自己的观点,这里是幸运的,我肯定了勇士的说法,勇士也以实例再次反驳博主,博主也很快纠正了错误,避免误导更多的人。
计算机发展迅速,很多东西也才出现几年,谁都有可能是谁的老师,有时候更多是需要去肯定自己。
那么,什么是最左原则?
引用前文
索引最左原则指的是组合索引定义(sex,age,time)按从左到右顺序走,而不是sql语句where条件的先后顺序。网上经常说到怎么怎么样,索引不生效,走全表扫描,例如上例:并不是说time不生效就完全不走索引了,它还是走(sex,age)的,这是一句很有歧义的表达,应该表达为走全表扫描或全索引扫描。
那什么是最左原则,见下一点——
■ 4.我对索引的认知
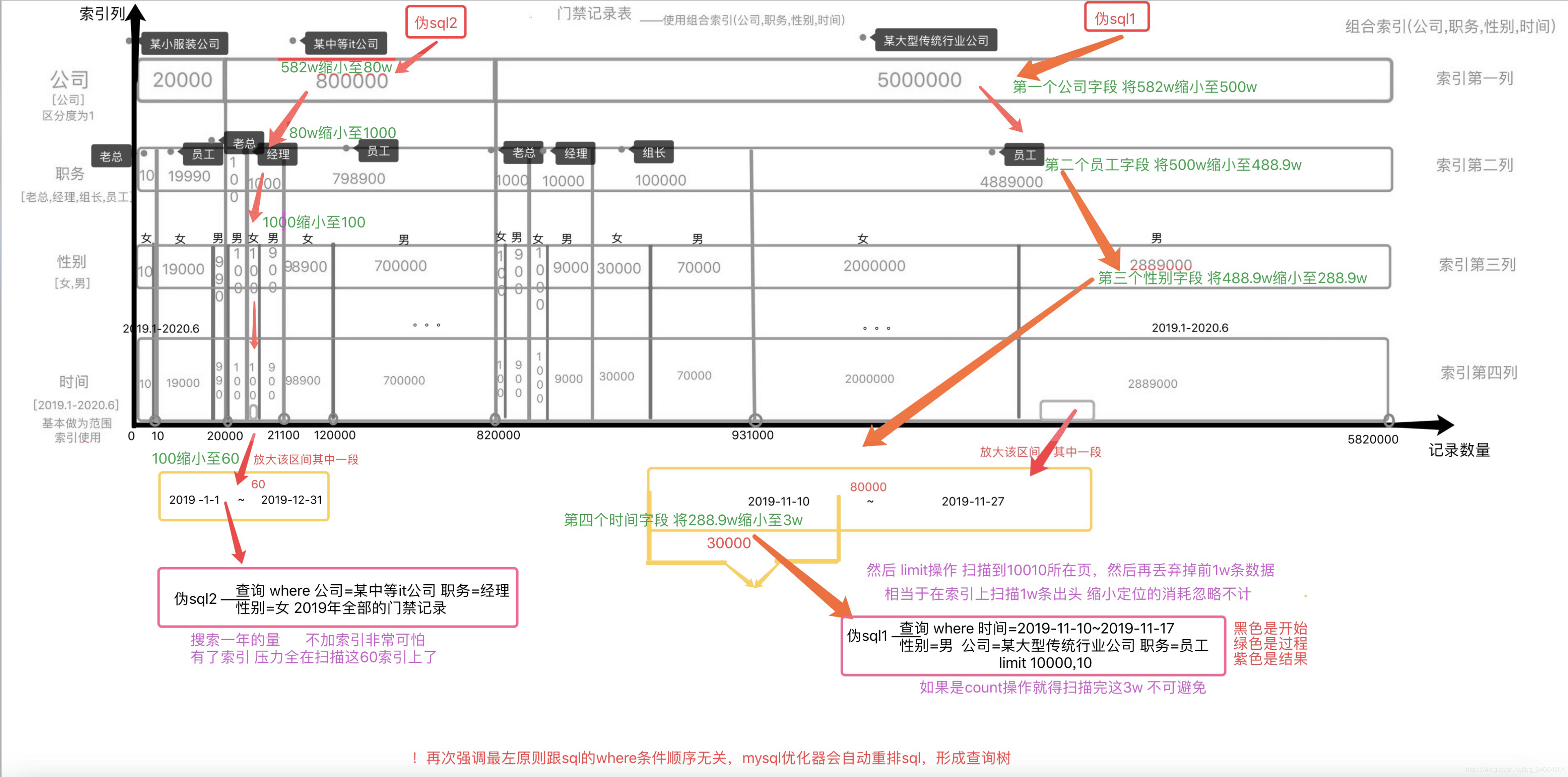
网上谈innodb索引都是给出一张B+树图,对于很多人来说并不是很好理解,我去掉索引树这个结构,将索引如何缩小范围查询更加地形象化,看下面这张我给出的图,基本就能理解了索引走不走的问题。
例图为我自创的582w条记录的门禁记录表的复合索引(公司,职务,性别,时间)的形象化结构图。索引顺序在图中从上到下就相当于最左原则的从左到右。每一块被切割的长方体的数字表示那一块索引数量大小,不断地一层一层进行分类、排序。
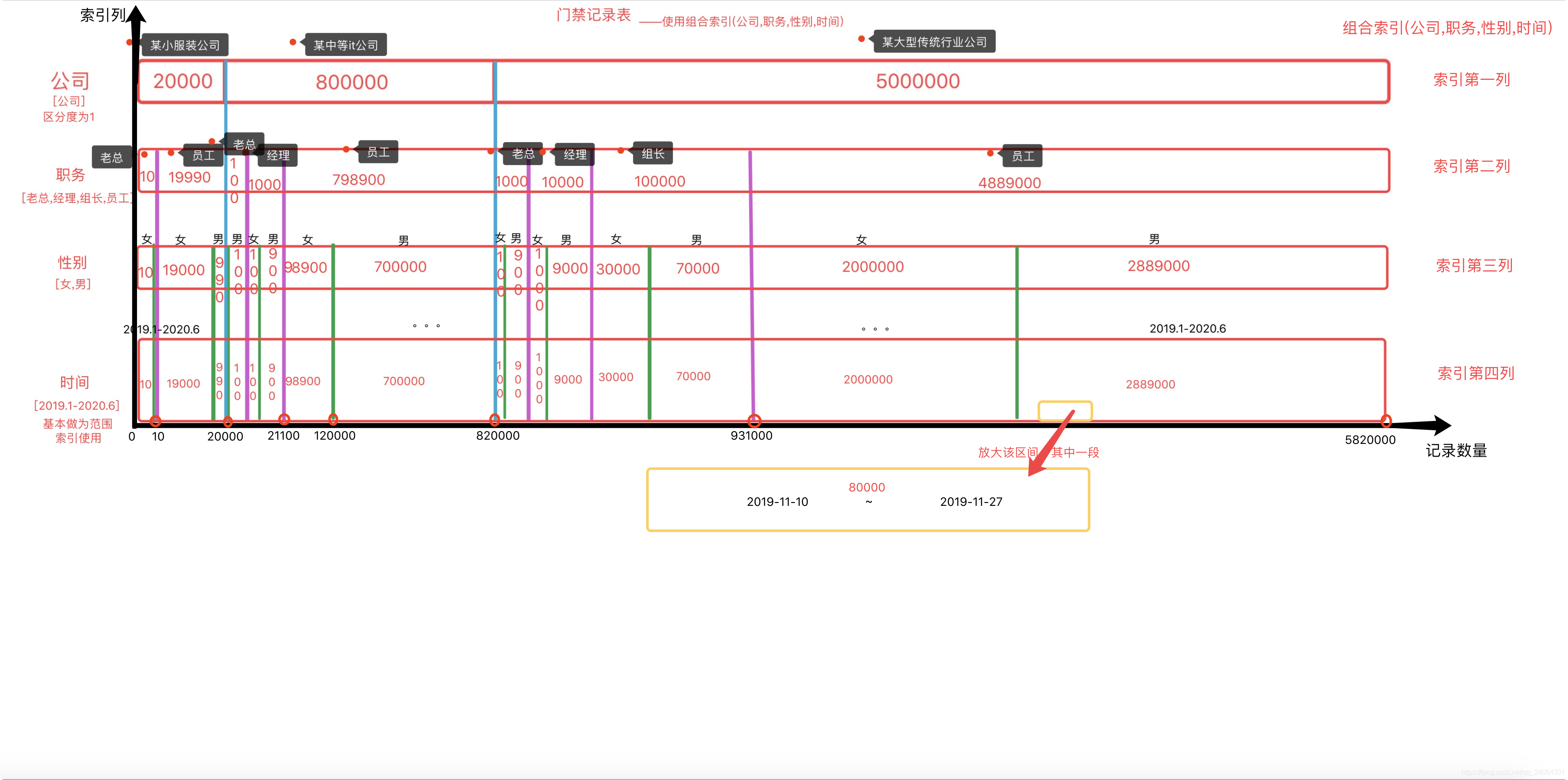
接着,我给出实例来——
两个sql 查询
sql2 查询 2019年某中等公司全部女经理的门禁记录
sql1 查询 2019-11-10~2019-11-17某大型公司男员工 limit 10000,10
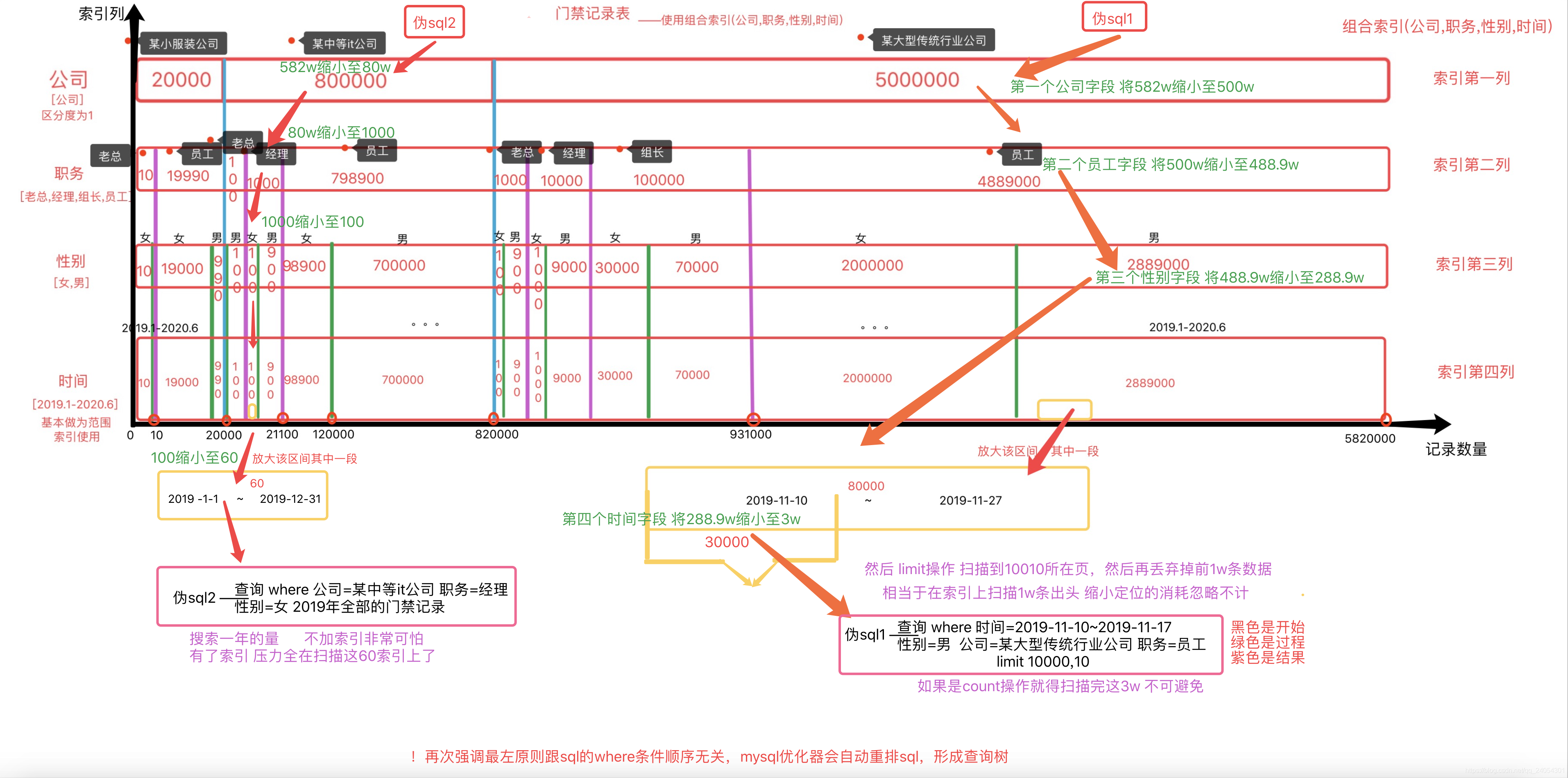
去杂色版 ——
■ 5.尽量避免in的使用
前文说过in是走索引的,in虽然explain为rang,但它不算是范围查询,所以组合索引前面字段用了in,后面的字段也是走索引的。也给出了一个例子,
回顾前文——
③ 用in可以巧妙的少建立索引。例如你有一个搜索条件性别 ,男为1,女为2,全部为不查,有的人可能会建立这么两个索引(…,sex,…)和(…,…)来应对有性别搜索条件,和无性别搜索条件。然后你非要给性别设索引的话,可以只建(…,sex,…)索引,然后修改sql语句,当不过滤男女的时候把男女全列出来也就是
select … from a where … and sex in(1,2)and…
这样就可以巧妙的少建立索引。
这也是《高性能mysql第三版》给出的方案,距如今已经7、8年有余。
现在我要告诉你,这个方案是使用场景有局限性。如果组合索引in字段后面的字段在sql中进行了排序,那么查询连接估摸着会直接无响应。
例子:sql3 查询 某中等和大公司的男经理和男员工
如图——
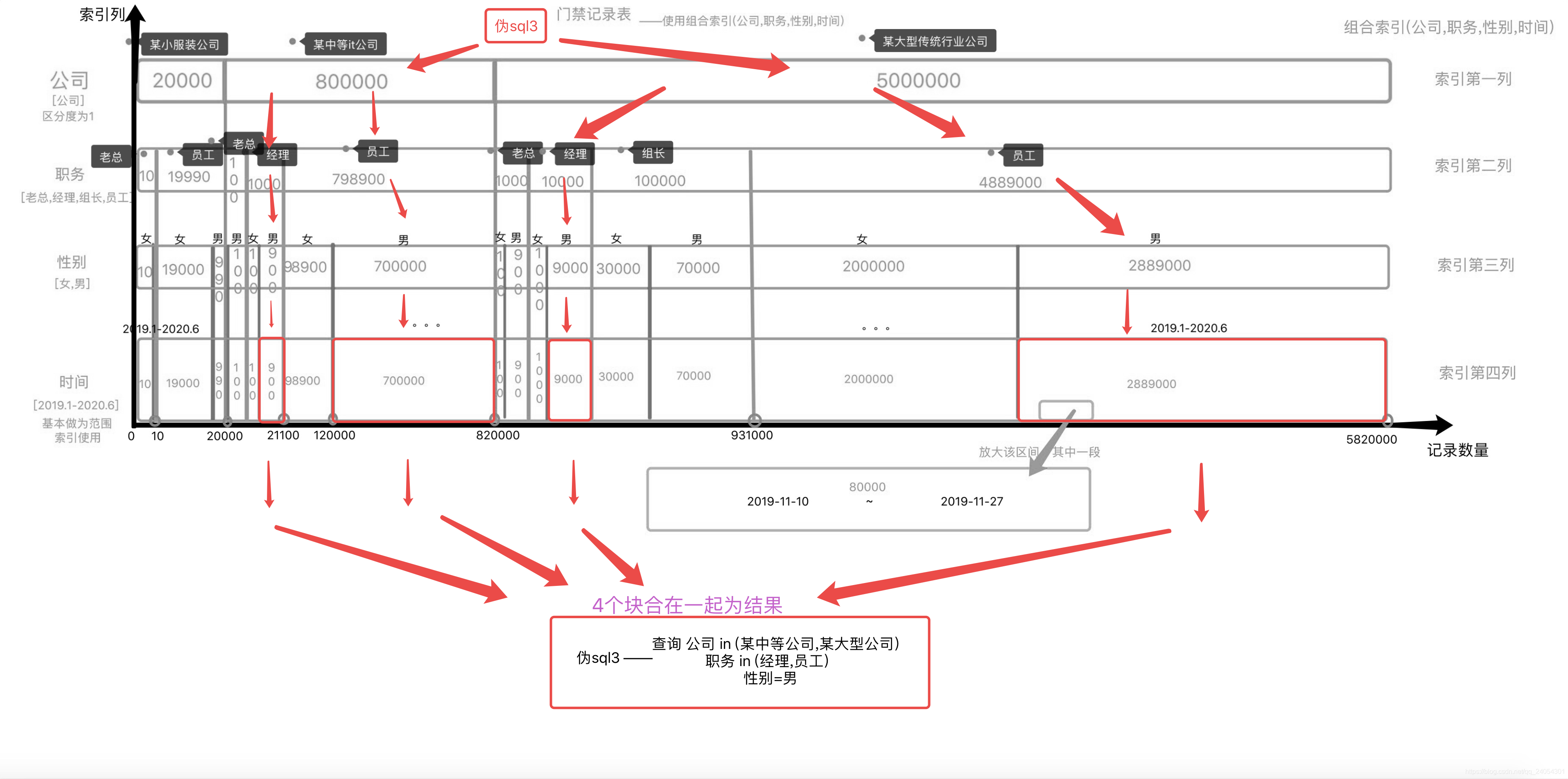
看下此图便清楚了in是怎么走的索引,在不需要排序的情况的这个索引是不错的,而你会发现limit前900条的记录都是中等公司的男经理的记录。
也就是说如果查询全部,最后查出来的结果是4个独立的连续时间的区间块再合并在一起,每一个块自身是有序的,一旦你排序了,它就会对这4块进行filesort操作重组排序。(每个块自身有序,多块组合自然要重排)in用的越多,笛卡尔乘积的组合排序也就越多,性能自然也就急剧下降。
所以,后续字段用到了排序,前面字段尽可能的避免使用in操作,只有不关心顺序的查询才能用这种方法。
优化进行中
以下为一个5.5k的码畜 对mysql(innodb引擎)近千万级大表的分页优化操作
■ 效果展示
我曾被百度贴吧震惊了,单单一个李毅吧1500w个主题,页数随便跳转都能保证秒查,不愧是大厂,后来才发现它只给定位到201页,后面的都是假分页。。。好吧,索性也不指望能找到一个好的现成解决方案,便自己研究起来。
以下是一个count为一百多w的分页效果展示——
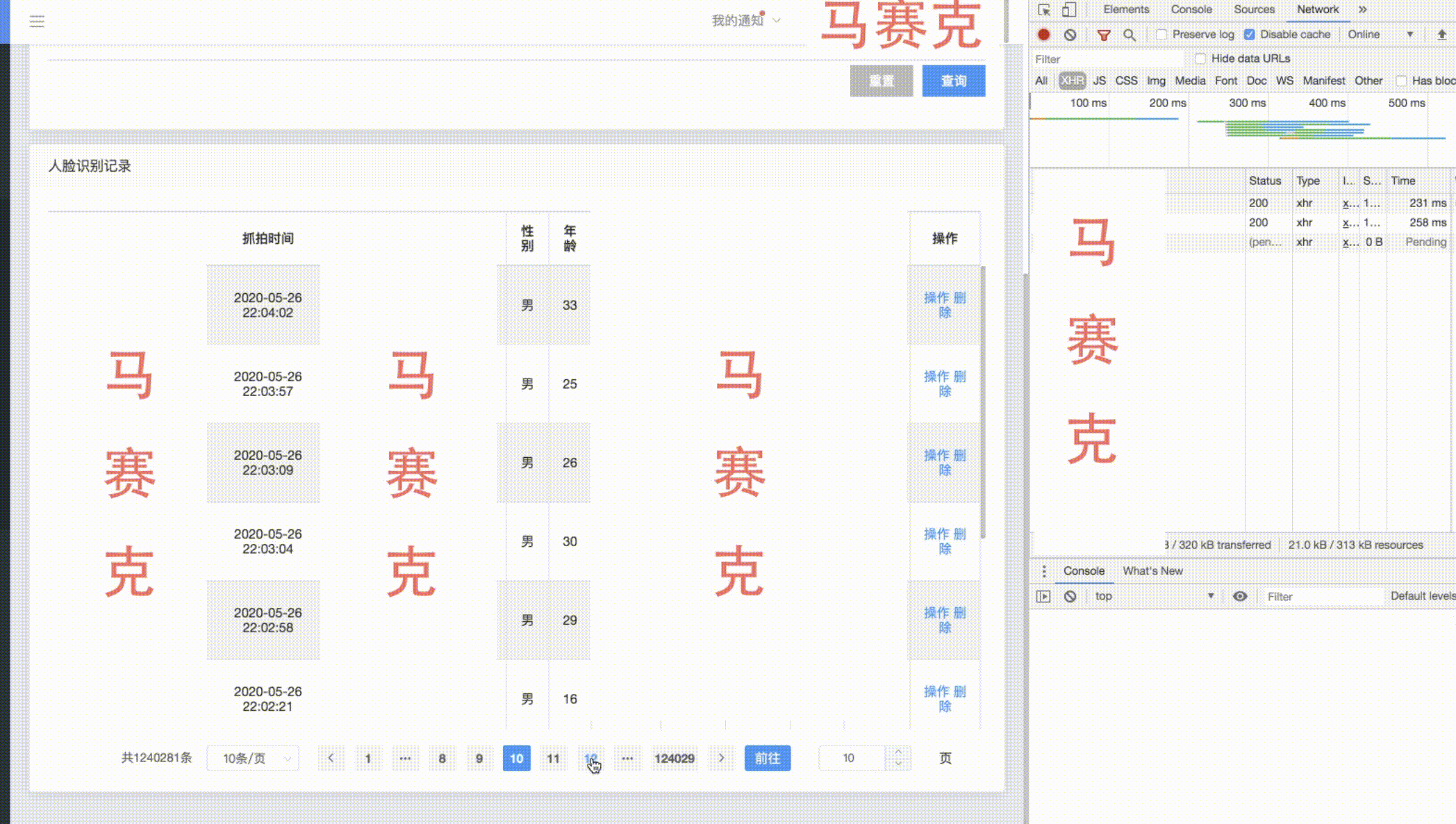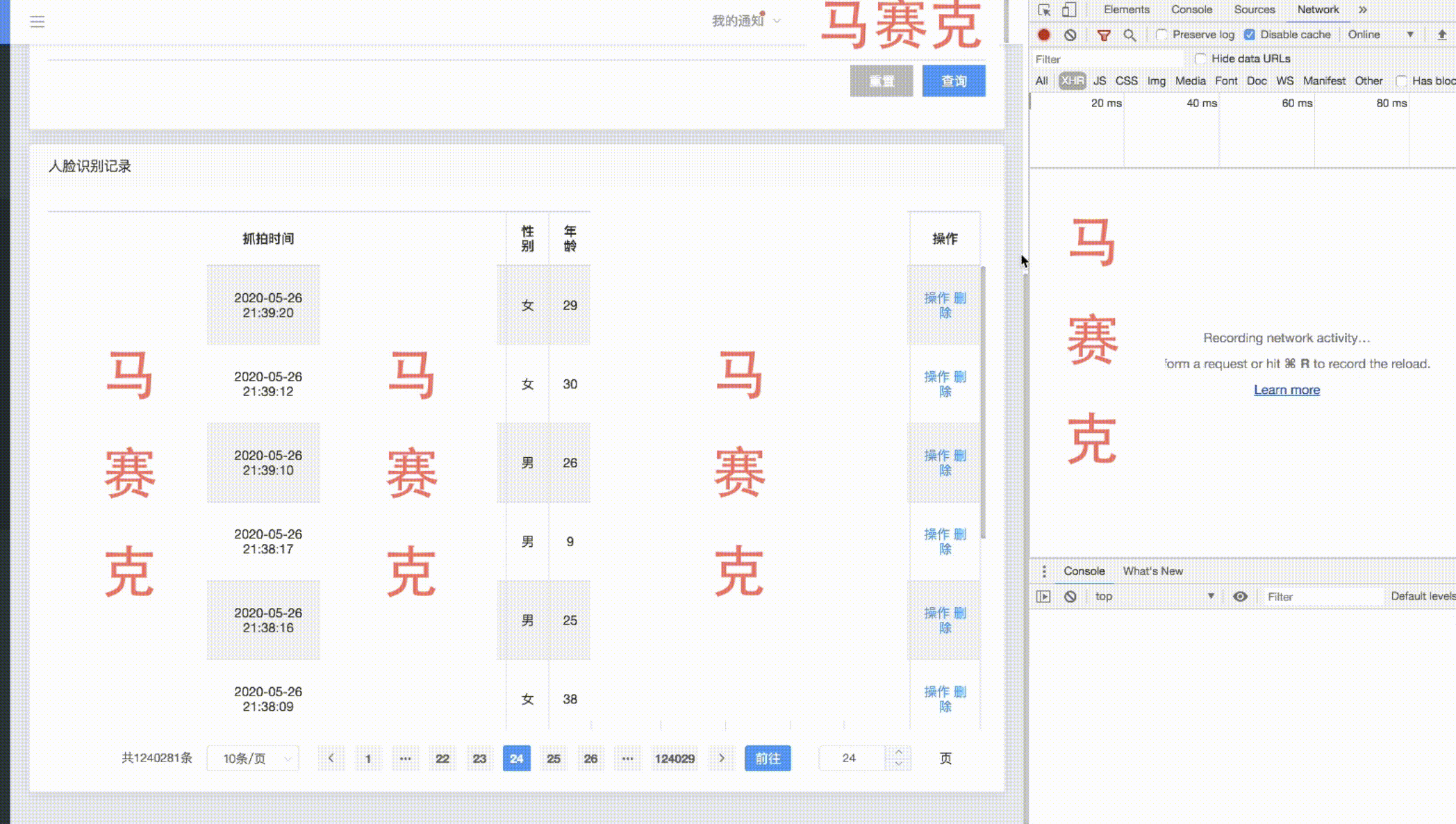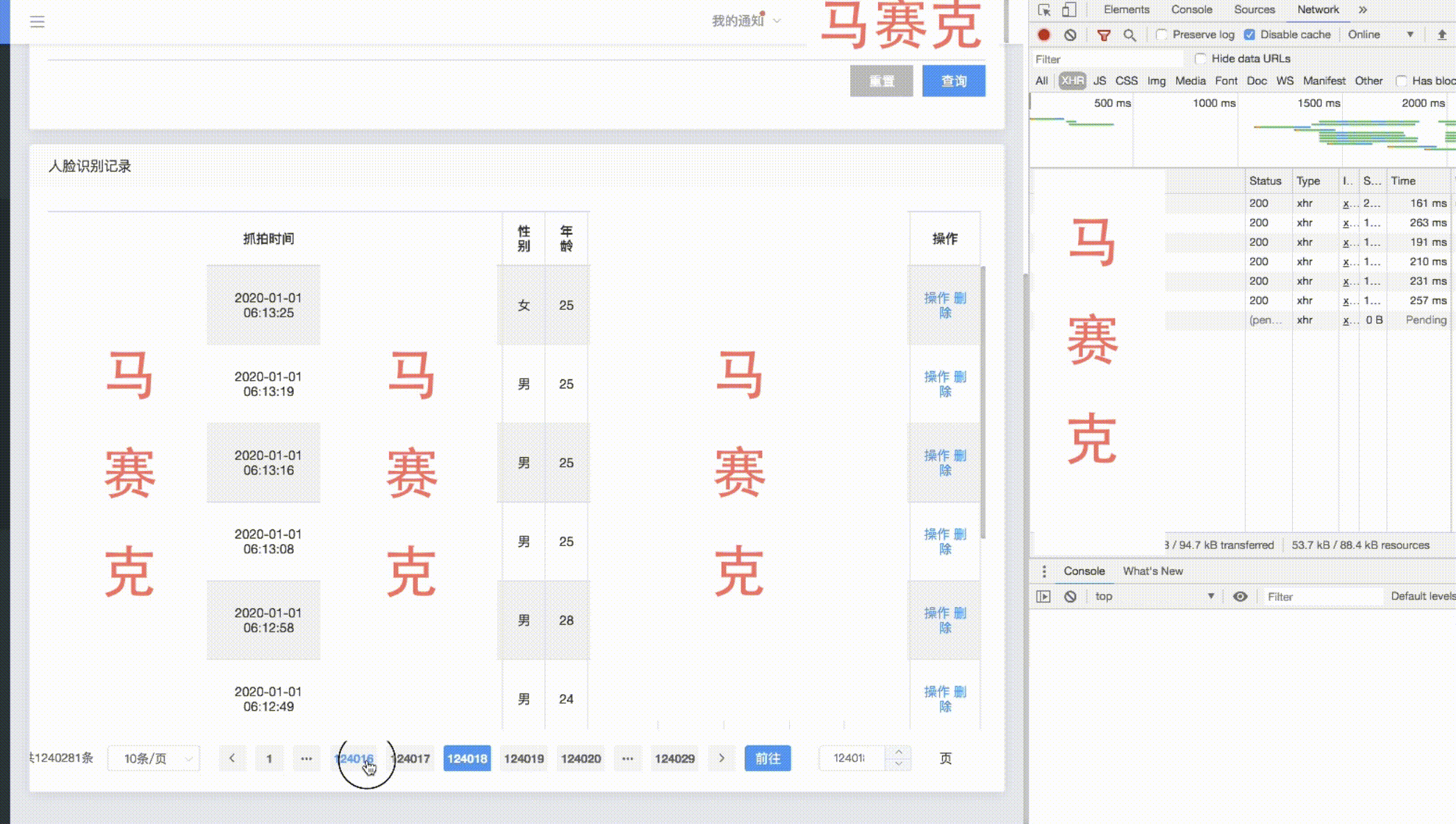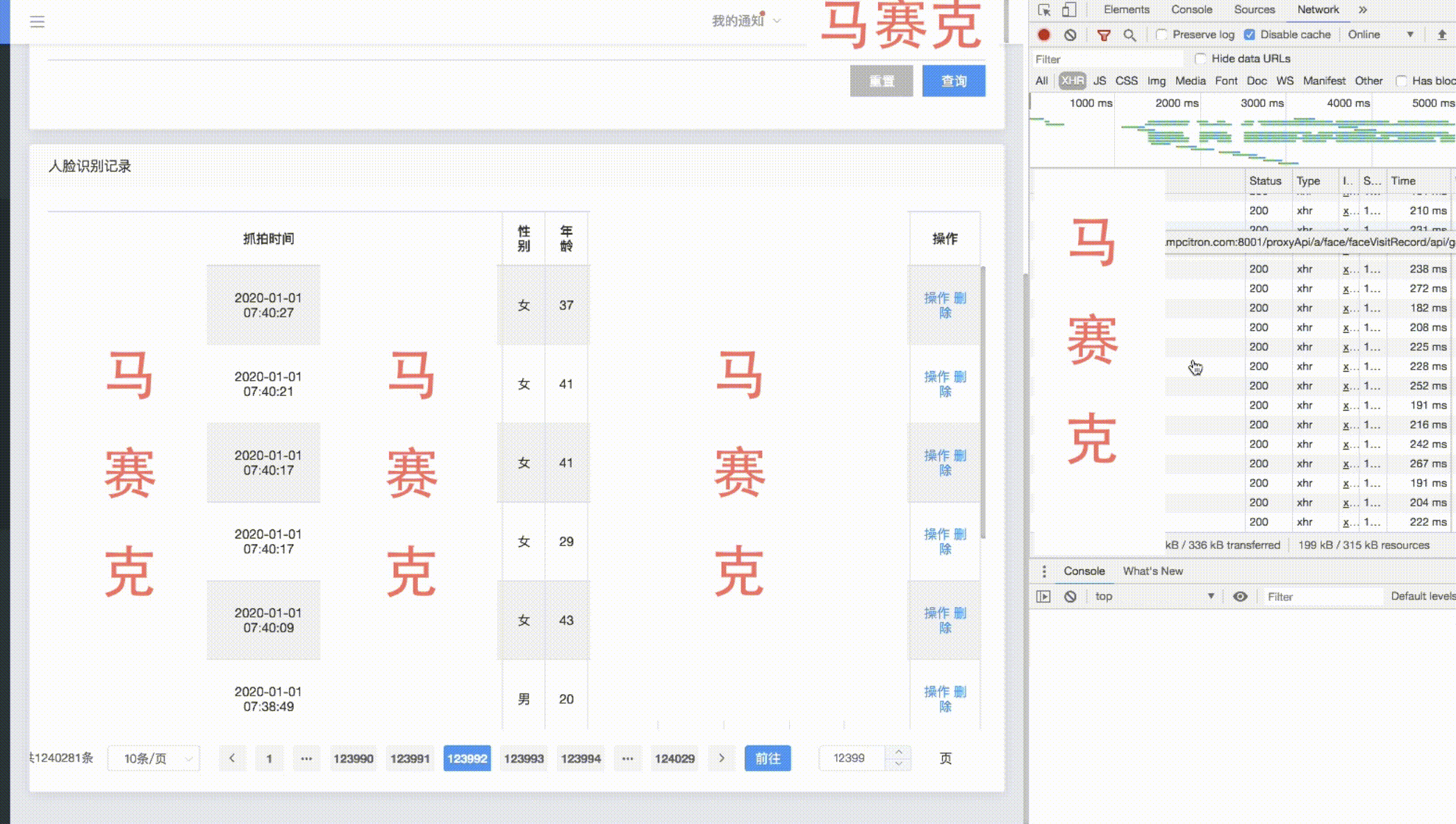
在保证索引最优效果的前提下,进行大表分页改造。在count缓存好的情况下,大数据量分页前几万条和后几万条的查询效果良好,在1w条以内甚至只剩下网络传输所消耗的时间,越往中间查询性能越差,不过中间数据的查看价值不高,首尾的数据还是最有价值的,可以限制不让用户跳转太远,保障查询性能。
■ 查询流程大纲
这图画的我自己都懵逼了,后面会以文字表述来讲解。不过画图也能理清点思路,发现之前没发现的bug——异步查询缓存为Loading,查出数据后,再查次缓存有count了,被我删除了缓存。加个限制——这个缓存是你当前接口请求所更新的才去删除。
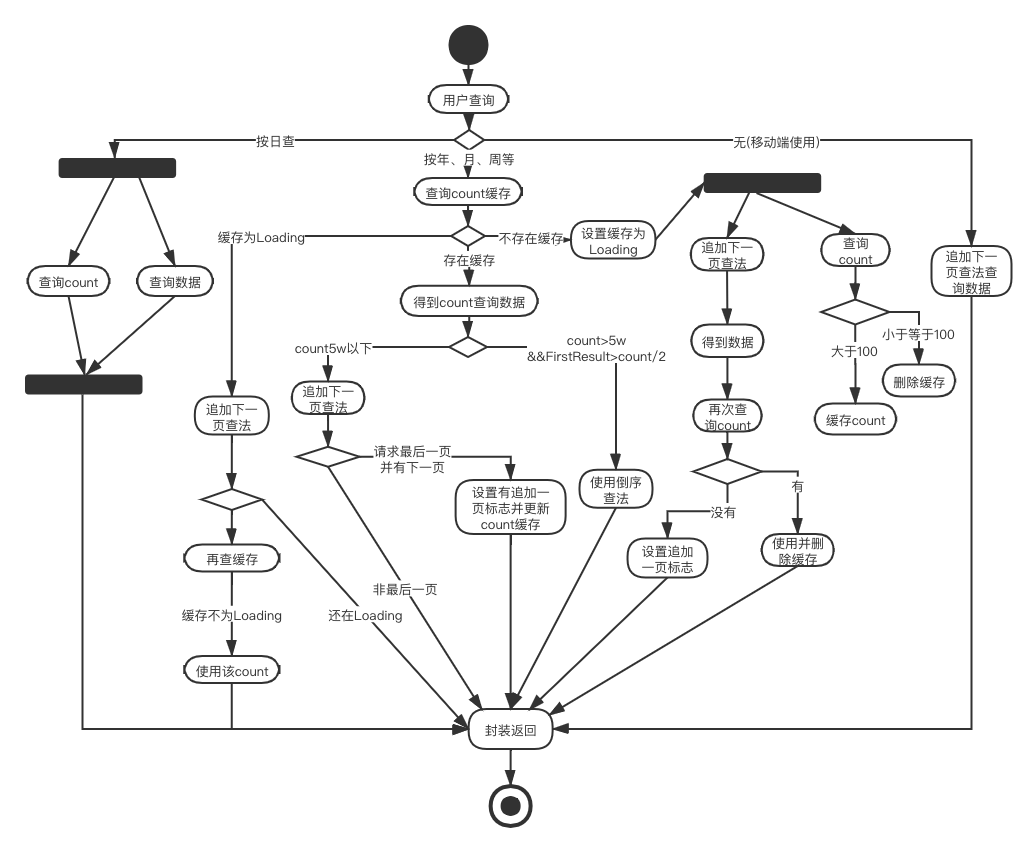
■ 详解查询流程
#准备阶段
① 回顾前文所说的动态追加下一页法
例子:移动端需要第3页,5条数据。传统我们是去除limit先查一遍count,有可能是100w,然后查询具体数据limit 10,5,查询count耗时好几秒,limit具体数据是秒查,这样如何优化呢?
我称之为——动态追加下一页法:
limit 10,6 为 resultList ;返回count=(3-1)*5+resultList.size ;如果siz为6返回的resultList romove掉最后一条数据
如果resultList.size返回1~5,说明这个查询就是最后一页了,这么计算的count和传统count一致,如果resultList.size返回6,说明查询还可以有下一页,移动端也能判断是否有下一页
简单而言就是多查一条数据用以判断是否有下一页,然后再经过后期处理将数据整理成正常查一样的效果,从而起到可以判断是否有下一页的效果。
② 不可避免牺牲count实时性
CAP原则的背后道理是通用,很多时候想要一些东西就得牺牲一些东西。在这按日查一般需要即时性,而且数据量又小,count不作缓存性能也不错,而越大的count缓存的时间也越长,就需要牺牲count的实时性去提高查询性能。想要秒出mysql大表查询的实时count是不可能的,即便是MyIsam也不支持带条件查询的秒查count。
③ 倒序查法
例如limit 100000, 10; 之前讲过,mysql肯定是要扫描那前10w条的,然后再丢弃掉。这跟走不走索引毫无关系,不会因为你建了索引它就不扫描,这是必然的过程。那么我们可以这么做:如果你知道count为10w,现在要查最后10条,实际上是不是把顺序颠倒过来的前10条呢?
如下——
public void reverse() {
this.firstResultReverse = (int)count - this.firstResult - pageSize;
if(this.firstResultReverse < 0) {
this.pageSizeReverse = this.firstResultReverse + this.pageSize;
this.firstResultReverse = 0;
} else {
this.pageSizeReverse = this.pageSize;
}
}
例子:
总数为9995; order by DESC limit 9980, 10 ; 结果为倒数第2页,10条数据;
可得参数:count=9995; firstResult=9980; pageSize=10;
代入上面方法可得:
firstResultReverse=5;
=> 判断大于等于0
pageSizeReverse=10;
重组sql——order by ASC limit 5, 10 order by DESC;
总数为9995; order by desc limit 9990, 10 ; 结果为最后一页,5条数据;
可得参数:count=9995; firstResult=9990; pageSize=10;
代入上面方法可得:
firstResultReverse=-5;
=> 判断小于0
pageSizeReverse=5;
firstResultReverse=0
重组sql——order by desc limit 0, 5 order by DESC;
这样即可做到查最后的一些页数和最前面的一页页数一样的神速,当然往中间查会越来越慢。这个做法与追加一页法有点冲突,之前采用追加下一页法不断的查询最后一页,我会不断的进行更新count缓存,而用了倒序法,最后一页就是最后一页,它肯定最后面的数据,但是count就不会更新了,所以需要设定一个额外的机制去更新count缓存,保证count不会一直不变。
1.按日查询
按日查询被我归为低数据量查询,单用户单日数据量最多也就小几万,所以此处多线程同时查询count和具体数据,再整合返回。
2.无条件查询
无条件查询被我归为移动端查询,移动端查询是最轻松的,不需要查询count,使用动态追加下一页法轻松解决。又或者采用最后一条的时间戳为游标带到下一个查询的方式,这个方式比动态追加下一页要更好,只要索引生效,无论划到天涯海角都没有性能问题,唯一要解决的就是同一时间戳的数据的定位问题。
3.其它条件查询
其它条件查询——几乎卡到爆的查询,也就是我要讲的重点了,绝大多数的操作都用在此处。
①缓存count
大表分页查询最大的难题是什么呢?毫无疑问总count,又想要即时性又想要速度,可以说是不可能(在条件单一的情况下可以单独维护count,在这讲的是查询条件复杂的情况),当然你可以采用只给开放附近几条的分页方式,我这里讲解的是传统显示count的分页查询。
对查询参数整理(去除一些不参与排序的参数,将查询参数排序,生成条件唯一值)——
// 获取升序参数map
public static Map getSortParmMap(ServletRequest request) {
Enumeration<?> pNames = request.getParameterNames();
Map<String, String> params = new HashMap<>();
while (pNames.hasMoreElements()) {
String pName = (String) pNames.nextElement();
if ("pageSize".equals(pName) || "pageNo".equals(pName) || "token".equals(pName) || "sign".equals(pName) || "appSecret".equals(pName))) {
continue;
}
String pValue = request.getParameter(pName).replace(":","-");
if (StringUtils.isNotBlank(pValue)) {
params.put(pName, pValue);
}
}
return params;
}
生成redis的key值(小技巧:使用冒号: 在redis可视化管理工具里,会进行归档,方便管理)。不必担心key太长导致性能下降,这么点长度对于redis来说小菜一碟。
Map<String, Object> params = LargePage.getSortParmMap(request);
String paramStr = "face:" + rcd.getCurrentUser().getTenantId()+ ":" + params;
② 在主线程数据已经查询出来的情况下,count还未缓存完毕,数据永远比count重要,不等待,保证数据优先,直接使用动态追加下一页法。
举个例子我查询数据耗时200ms,数据结果已经出来,主线程再次查询缓存得知count还是Loading,那就不要等待了,直接返回这个结果,并且告知前端有下一页。

如图,并告知前端当前采用的动态追加下一页法,不要显示动态追加下一页法所返回的count,而是显示一个加载状态,表示count还在查询之中,返回的假count仅用于分页插件的显示页数计算。
③ 假如数据查询出来时,再次查询得到了count缓存,这时候得到count就可以拿来用了,如果这个count缓存是你当前查询所做的,你就可以把这个缓存清除掉,因为数据出来了,count也查出来了,说明这个count查询很快,缓存是没必要的,甚至可以设定该条件缓存为small一定的时间,表示后面查询这个条件不必做缓存,每次都去查询数据库,以做到小count的实时性。
#总结下效果
按日正常查
其它类型异步查count,count先查出来直接赋值,保证实时
count 1000(可设定)以下不缓存
count还在查询,前端count显示转圈圈 ,但是肯定知道知否有下一页
count小于5w(可设定) 后面的页数常规limit 会稍微慢点,不过会判断有没有下一页
count大于5w(可设定) 后面的页数实际上就是将顺序倒过来查前几页,头尾都很快,中间慢
我的count缓存机制是,越大的count缓存越久,然后做一个count的刷新机制,一个大表分页机制就完成了。
最后
路漫漫其修远兮,mysql优化和分页的优化还有很长的路要走,我还在路上。