Python数据格式化和处理,CSV数据和JSON数据的应用
1.数据组织的维度(一维,二维,多维)
1.基于维度的数据分类
根据组织数据时与数据有联系的数量,数据可以分为一维数据,二维数据和多维数据(高维数据)。
常见的一维数据有:
- 一维列表
- 一维元组
- 集合
常见的二维数据有:
- 矩阵
- 二维数组
- 二维列表(列表里面嵌套列表)
- 二维元组(元组里面嵌套元组)
常见的多维数据有:
- 字典
2.CSV格式文件与二维数据存储
1.概述
CSV:Comma-Separated-Values(逗号分隔值)
- 国际通用的一二维数据存储格式,一般.csv扩展名
- 每行一个英文数据,采用逗号分隔(英文半角)
- Excel和一般的编辑软件都可以读入或另存为csv文件
如果你的
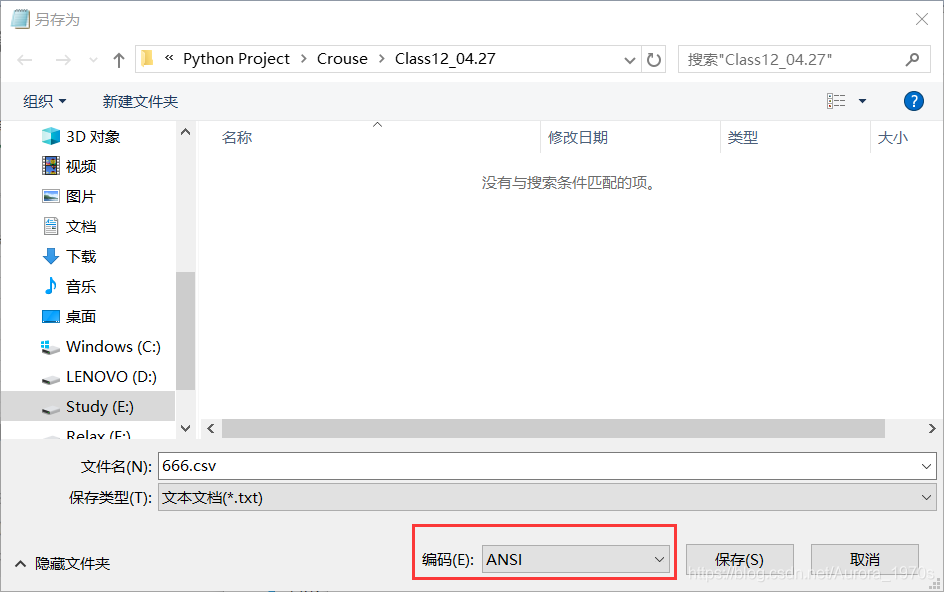
.csv文件用Excel打开之后是乱码,可能是因为编码格式的问题,Excel默认的是ANSI,你可以用记事本打开.csv文件然后另存为.csv文件,并把编码格式改成ANSI即可:
2.CSV文件的读写
现在有src.csv内容如下:
姓名,语文,数学,英语
张三,80,80,80
李四,90,90,90
王五,70,70,70
读取src.csv中的内容:
f=open('src.csv','r',encoding='utf-8')
ls=[]
for line in f.readlines():
#原来的csv文件中的每一行的最后都有换行符,这里把它去掉
line=line.replace('\n','')
#字符串转列表
ls.append(line.split(','))
print(ls)
f.close()
运行结果:
#其实这就是二维列表
[['姓名', '语文', '数学', '英语'], ['张三', '80', '80', '80'], ['李四', '90', '90', '90'], ['王五', '70', '70', '70']]
现在如果要在上面数据的基础上增加总分属性,并把几位同学的各科分数相加计算出总分。下面就是.csv文件的写操作,在上面代码的基础上新增加以下代码:
f2=open('src_1.csv','w',encoding='utf-8')
ls[0].append('总分')
for line in ls[1:]:
sum=0
for i in line[1:]:
sum+=eval(i)
line.append(str(sum))
for line in ls:
f2.write(','.join(line)+'\n')
f2.close()
最终得到一个新的文件src_1.csv,里面的内容是:
姓名,语文,数学,英语,总分
张三,80,80,80,240
李四,90,90,90,270
王五,70,70,70,210
3.JSON数据格式
JSON格式是网络上最常见的高维数据格式。
1.JSON数据语法规则
- 数据存储在**键值对(key:value)**中,例如“姓名”: “张华”。
- 数据的字段由逗号分隔,例如“姓名”: “张华”, “语文”: “116”。
- 花括号保存一个JSON对象,例如{“姓名”: “张华”, “语文”: “116”}。
- 方括号保存JSON数组,例如[{“姓名”: “张华”, “语文”: “116”},{…}]。
2.JSON对象和Python对象相互转换
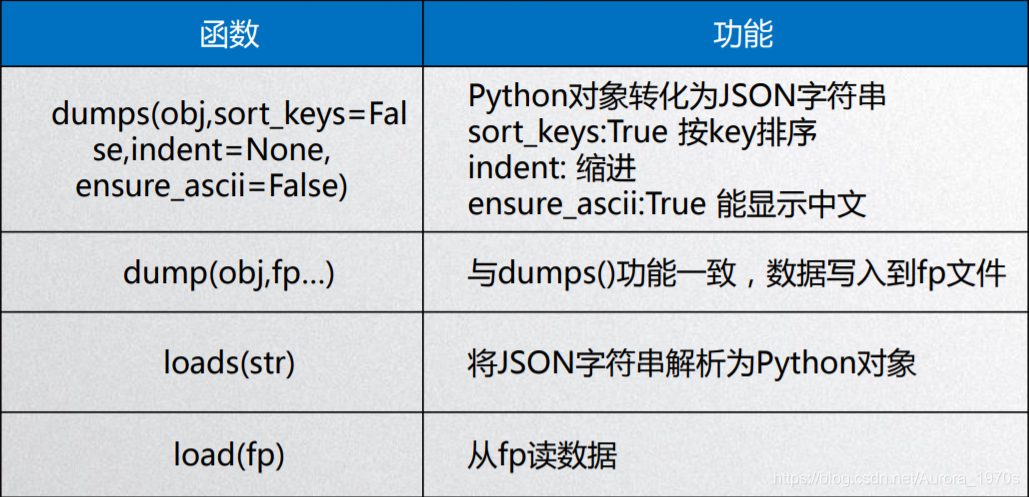
转换函数:
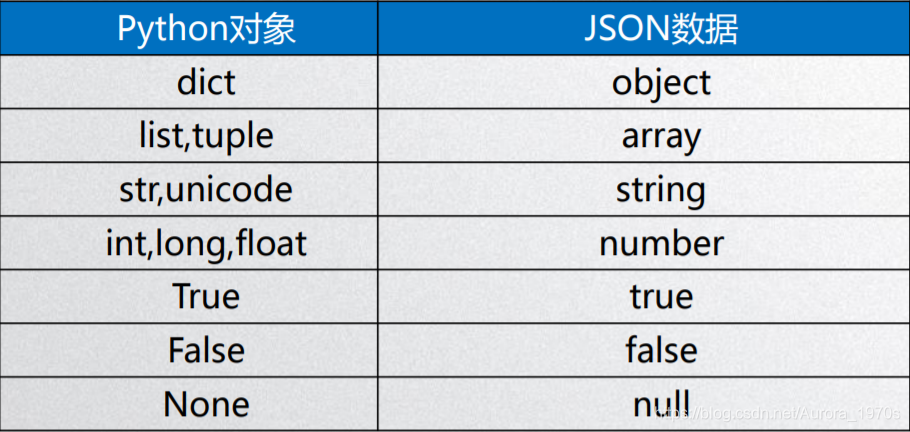
Python对象与JSON数据转换时的类型对照表:
4.CSV数据与JSON数据转换
1.CSV数据—>JSON数据
#把csv文件内容取出来
f=open('src_1.csv','r',encoding='utf-8')
ls=[]
for line in f.readlines():
line=line.replace('\n','')
ls.append(line.split(','))
print(ls)
f.close()
#开始转换
f2=open('src_1111.json','w',encoding='utf-8')
new_ls=[]
for l in ls[1:]:
#zip函数的功能就是将两组元素分别对应组合在一起,返回一个可迭代的对象
t=dict(zip(ls[0],l))
new_ls.append(t)
print(new_ls)
lsj=json.dumps(new_ls,ensure_ascii=False,indent=4)
json.dump(new_ls,f2,ensure_ascii=False,indent=4) #输出为json文件
print(lsj)
f2.close()
运行之后生成的JSON文件:
[
{
"姓名": "张三",
"语文": "80",
"数学": "80",
"英语": "80",
"总分": "240"
},
{
"姓名": "李四",
"语文": "90",
"数学": "90",
"英语": "90",
"总分": "270"
},
{
"姓名": "王五",
"语文": "70",
"数学": "70",
"英语": "70",
"总分": "210"
}
]
2.JSON数据—>CSV数据
import json
f=open('src_1111.json','r',encoding='utf-8')
ls=json.load(f)
print(ls)
f.close()
#取出表格标题
t=[list(ls[0].keys())]
print(t)
for line in ls:
t.append(list(line.values()))
print(t)
f2=open('src_7777.csv','w',encoding='utf-8')
for line in t:
f2.write(','.join(line)+'\n')
f2.close()
运行之后生成的CSV文件:
姓名,语文,数学,英语,总分
张三,80,80,80,240
李四,90,90,90,270
王五,70,70,70,210