文章目录
一、cat命令
(一)概述
cat 命令可以用来显示文本文件的内容,也可以把几个文件内容附加到另一个文件中,即连接合并文件,也可以创建文件或向文件中追加内容
#cat 是 concatenate(连接、连续)的简写
用法: cat [选项]… [文件]…
选项:
-n: 对输出的内容每行进行编号(包括所有空白行)并输出
说明:空白行不是指看不到的字符,而是指本行直接进行回车换行。例如该行只是使用【Tab】键,那么虽然显示看不到,但是不属于空白行
-b: 对输出的内容每行进行编号(空白行不编号)并输出
说明:仅使用【Tab】键造成的行不属于空白行,所以会对该行进行编号
-s: 若输出的内容中有连续的多个空白行,那么只显示出一个空白行
-v: 使用^ 和M- 引用,除了LFD和 TAB 之外
说明:对于系统无法识别和打印出来的内容将以特殊字符进行显示,如果是回车换行键【Enter】和【Tab】键则除外不以特殊字符进行显示
-E:在每行结束处显示"$" (也可以理解为将每行最后的换行符显示为 $ 符号)
-T:将跳格字符显示为^I (即将文件内容中的【Tab】显示为 ^I)
-A:等价于-vET
-e:等价于-vE
-t :等价于-vT
注意:在用cat 命令查看文件内容时,不论文件内容的多少,都会一次性显示。如果文件非常大,那么文件开头的内容就看不到。如果是使用远程连接工具进行查看的或许会好点可以向上滚动,但是这种向上翻看是有极限的,如果文件足够长,那么还是无法看全文件的内容
因此,cat 命令适合查看不太大的文件。当然,在 Linux 中是可以使用其他的命令或方法来查看大文件的,比如less、more等等
(二)实例
【例 1】
cat 命令本身比较简单,可以直接用来查看文件的内容
[root@admin ~]# cat anaconda-ks.cfg
#version=DEVEL
# System authorization information
……省略部分内容……
@^minimal
@core
kexec-tools
……省略部分内容……
【例 2】
打印时显示行号
-n选项也会对所有的空白行进行编号并输出
-b选项对非空白行进行编号并输出
-s选项对每行不进行编号但是对于连续的多个空白行只会输出一个空白行
[root@admin ~]# cat -n anaconda-ks.cfg
1 #version=DEVEL
2 # System authorization information
……省略部分内容……
39 @^minimal
40 @core
41 kexec-tools
……省略部分内容……
【例 3】
如果对于一些对命令或语法格式要求比较严的配置文件和脚本等:
- 若想要查看一些特殊字符:则可以使用-v选项
[dxk@admin ~]$ cat -v file
- 若想要识别每行结尾处有没有空格键,则可以使用-E选项(可以理解为将每一行末尾的换行键以“$”符号来显示)
[dxk@admin ~]$ cat -E mycsdn
welcom to my csdn$
$
welcome to my csdn $
$
$
welcome to my csdn $
$
$
$
- 如果仅想要识别内容中的【Tab】键,则可以使用-T选项
[dxk@admin ~]$ cat -T mycsdn1
welcome to my csdn #单词中间的空白是空格键的效果
welcome^Ito^Imy^Icsdn #显示为^I是【Tab】键的效果
welcome to^Imy csdn
^I
【例 4】
如果想要同时识别特殊符号、换行键、跳格键【Tab】,那么可以使用 -A 选项
(系统无法识别的字符显示为一些特殊符号,换行键显示为“$”,跳格键显示为^I)
其实: -A选项等价于-vET 的联合使用
-e选项等价于 -vE 的联合使用
-t选项等价于 -vT 的联合使用
#识别特殊符号、换行键、跳格键
[dxk@admin ~]$ cat -A mycsdn #等价于cat -vET mycsdn
#识别特殊符号、换行键
[dxk@admin ~]$ cat -e mycsdn #等价于cat -vE mycsdn
#识别特殊符号、跳格键
[dxk@admin ~]$ cat -t mycsdn #等价于cat -vT mycsdn
【例 5】
文件合并的用法
将文件 file1.txt 和 file2.txt 的内容合并后输出到文件 file3.txt 中
[dxk@admin ~]$ ls
file1 file2
[dxk@admin ~]$ cat file1
baseurl=http://www.baidu.com
[dxk@admin ~]$ cat file2
baseyrl=file:///data
[dxk@admin ~]$ cat file1 file2 > file3
[dxk@admin ~]$ ls
file1 file2 file3
[dxk@admin ~]$ cat file3
baseurl=http://www.baidu.com
baseyrl=file:///data
如果想要把把文件file2,file3,file4的文件内容写入到file1中,如果file1文件以前有内容,则先会清除它们然后再写入合并后的内容
[dxk@admin ~]$ cat file2 file3 file4 > file1
如果不想清除文件内容,则可以把单边号 > 变成了双边号 >>
[dxk@admin ~]$ cat file2 file3 file4 >> file1
【例 6】
创建文件以及写入文件内容的用法
[dxk@admin ~]$ cat > file << EOF
> Hello everyone !
> Nice to meet you .
> How are you ?
> EOF
[dxk@admin ~]$ cat file
Hello everyone !
Nice to meet you .
How are you ?
创建文件的时候要设置文件结束标志,这里是<<EOF,可以把EOF换成别的字符,注意区分大小写。当文件内容写完之后要输入结束标志EOF,这时命令会正确结束,表示成功创建文件并且写进内容。
#这里自己定义结束符标志
[dxk@admin ~]$ cat > file1 << end
> hello world
> hello linux
> end
[dxk@admin ~]$ cat file1
hello world
hello linux
二、diff命令
比较文件的差异的命令 diff
(一)概述
diff命令在最简单的情况下,比较给定的两个文件的不同。如果使用“-”代替“文件”参数,则要比较的内容将来自标准输入。
diff命令是以逐行的方式,比较文本文件的异同处。如果该命令指定进行目录的比较,则将会比较该目录中具有相同文件名的文件,而不会对其子目录文件进行任何比较操作
用法: diff[参数][文件1或目录1][文件2或目录2]
选项:
- -B:不检查空白行
- -i:比较时忽略大小写
- -q:仅显示有无差异,不显示详细信息
- -r:比较子目录中的文件
- -u:以合并的方式来显示文件内容的不同
- -y:以并列的方式显示文件的差异
- -W:在使用-y参数时,指定栏宽
(二)实例
首先我们先创建在内容上有一些不同的file1和file2两个文件
[dxk@admin ~]$ cat file1
Hi,
Hello,
How are you?
I am ok,
Thank you.
[dxk@admin ~]$ cat file2
Hello,
Hi,
How are you?
I am fine.
接下来看看diff命令执行后的结果
[dxk@admin ~]$ diff file1 file2
1d0
< Hi,
2a2
> Hi,
4,5c4
< I am ok,
< Thank you.
---
> I am fine.
此时的输出有些费解,下面来说明一下该输出结果的含义,要明白diff比较结果的含义,我们必须牢记:diff描述两个文件不同的方式是告诉我们怎么样改变第一个文件之后与第二个文件达到匹配
第一个输出信息:
1d0
< Hi,
1d0:意思是第一个文件的第一行相比较于第二个文件是多余的需要被删除
1:代表执行的diff命令的左边的参数(这里就是file1)的第1行
0:代表执行的diff命令的右边的参数(file2)的第0行
d:(delete)代表删除
< Hi :表示需要被删除的第一个文件的第一行的内容是 Hi
综合起来就是:file1文件的第1行删除(d)后与第二个文件的第0行相同
这样的话,经过改变此时file1和file2文件中的内容如下所示:
#file1中: file2中:
Hello, Hello,
How are you? Hi,
I am ok, How are you?
Thank you. I am fine.
第二个输出信息:
2a2
> Hi,
2a2:将第一个文件的第2行添加内容后便与第二个文件的第2行相同
第一个2:执行的diff命令左边参数文件中(即file1文件)中的第2行
a:(add)代表添加
第二个2:执行的diff命令右边参数文件中(file2文件)中的第2行
> Hi, :要添加的内容为Hi. (也就是file2文件的第2行的内容)
经过第二次改变后,此时file1和file2文件中的内容如下所示:
#file1中: file2中:
Hello, Hello,
Hi, Hi,
How are you? How are you?
I am ok, I am fine.
Thank you.
第三个输出信息:
4,5c4
< I am ok,
< Thank you.
---
> I am fine.
4,5c4:表示将第一个文件的第4,5行做出改动后才能与第二个文件的第4行相同
该信息以下的输出信息是说明怎样进行改动。就是将第一个文件的第4,5行删掉,将第2个文件的第4行添加到第一个文件刚删除位置
4,5:执行的diff命令左边参数文件中(file1文件)的第4行和第5行
c:改变
4:执行的diff命令右边参数文件中(file2文件)中的第4行
< I am fine, file1文件中需要删除的该行的内容
< Thank you. file1文件中需要删除的该行的内容
—:两个文件内容的分隔符号
> I am fine.:需要添加的内容
添加和删除的行分别用’>‘和’<'表示,后面所接为需要添加和删除的行的内容
其实这里 > 即可以代表添加也同时代表右边文件;< 即可以代表删除也同时代表左边文件
因为上面提到diff描述两个文件不同的方式是告诉我们怎么样改变第一个文件之后与第二个文件达到匹配。所以意思就是说第二个文件内容 不会变,只会去根据第二个文件来改变第一个文件,所以既然是添加内容的话,那就是在第二个内文件中有的内容而在第一个文件却没有,那么就要把在第二个文件中第一个文件中所没有的内容添加到第一个文件中去。删除同理,删除的是在第一个文件中第二个文件中所没有的内容。
经过第三次改变后,此时file1和file2文件中的内容如下所示:
#file1中: file2中:
Hello, Hello,
Hi, Hi,
How are you? How are you?
I am fine. I am fine.
这样两个文件就相同了
总结:
- 像1d0、2a2、4,5c4这种表达式可以理解为: [diff命令第一个参数的行号或者行的范围][行为或操作][diff命令第二个参数的行号或者行的范围] 。这里的’行为’可以是追加,删除或者改变替换。
- a=add,c=change,d=delete
- diff描述两个文件不同的方式是告诉我们怎么样改变第一个文件之后与第二个文件达到匹配
如果是這樣的:
2,4c2,4
含义是:第一个文件中的第[2,4]行(注意这是一个闭合区间,包括第2行和第4行)需要做出修改才能与第二个文件中的[2,4]行相匹配
那么肯定会在接下来的内容则告诉我们需要修改的地方,前面带 < 的部分表示左边文件的第[2,4]行的内容,而带> 的部分表示右边文件的第[2,4]行的内容,中间的 — 则是两个文件内容的分隔符号
其实对于以上对比我们可以使用-w和-y选项将会更为直观:
[dxk@admin ~]$ diff -y -W 40 file1 file2
Hi, < #将第一个文件的这一行删除
Hello, Hello,
> Hi, #将第二个文件的这一行的内容添加到第一个文件之后
How are you? How are you?
I am ok, | I am fine. #将第一个文件的第这一行用第二个文件的这一行进行替换
Thank you. < #删除第一个文件的这一行
如果是比较小文件的内容且内容差异不大,diff命令比较合适,否则就会比较麻烦,不适合用diff命令
可以使用vimdiff命令,没有难以解读的输出差异的信息,利用显示颜色、高亮等方式直观的看到两个文件的差异
[dxk@admin ~]$ vimdiff file1 file2
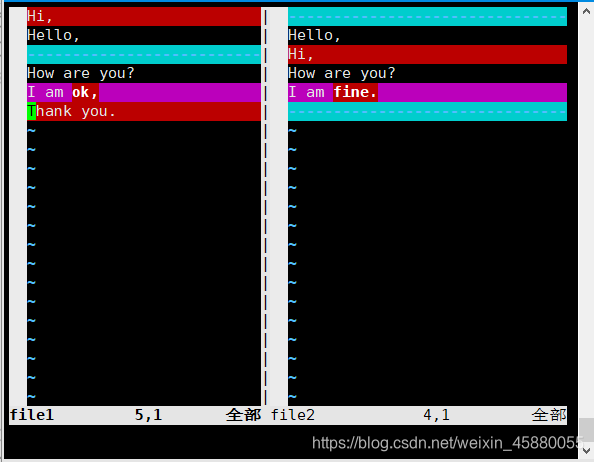
其实就是利用vim编辑器的一些功能显示出文件的差异之处,而且还可以直接进行文本编辑
三、grep命令
过滤文本的命令 grep
(一)概述
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户
很多时候,我们并不需要列出文件的全部内容,而是从文件中找到包含指定信息的那些行,要实现这个目的,可以使用 grep 命令
这里只对过滤查找文件中的匹配内容这一功能进行简要介绍,关于正则表达式在讲到文本三剑客时再进行详细讲解
用法: grep [选项]… 参数 [FILE]…
选项:
- -n:输出的同时打印行号
- -w: 仅完全匹配字词
- -i:不区分大小写
- -o:只显示匹配到的内容
- -v:显示没有匹配到的内容(和-o选项正好相反)
- -A NUM:显示匹配到的内容同时显示之后的NUM行
- -B NUM:显示匹配到的内容同时显示之前的NUM行
- -C NUM:显示匹配到的内容同时显示之前和之后的NUM行
- -c:统计匹配到某字段的总行数并打印出来
- -q:静默
注意,如果是搜索多个文件,grep 命令的搜索结果只显示文件中发现匹配模式的文件名;而如果搜索单个文件,grep 命令的结果将显示每一个包含匹配模式的行
(二)实例
【例 1】
查找/etc/passwd文件中存在“root”字段的行,并显示行号
#并且要匹配的字段会在输出信息中红底标识
[dxk@admin ~]$ grep -n root /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin
#打印出/etc/passwd文件中存在“root”字段的总行数
[root@admin ~]# grep -c root /etc/passwd
2
【例 2】
查找/etc/passwd文件中存在单词为bin的行
[dxk@admin ~]$ grep -w bin /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
dxk:x:1000:1000::/home/dxk:/bin/bash
Bob:x:1002:1002::/home/Bob:/bin/bash
eddydel:x:1003:1003::/home/eddydel:/bin/bash
test01:x:1004:1004::/home/test01:/bin/bash
如果不加-w选项,看看效果:
[dxk@admin ~]$ grep bin /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
……省略部分输出信息……
可以看到不使用-w选项所查到的关于“bin”字段的行和使用-w选项所查到的不一样
使用-w就是仅匹配存在“bin”这个单词的行,它是一个完整的单词,而-w选项匹配出来的的不仅有“bin”字段,还有“sbin”字段
【例 3】
匹配某个字段不区分大小写
[dxk@admin ~]$ grep -i hello file1
HELLO WORLD
HeLlo linux
hello oracle
hELlO java
[dxk@admin ~]$ grep -i HeLlO file1
HELLO WORLD
HeLlo linux
hello oracle
hELlO java
【例 4】
只显示匹配到的内容,而不显示所在行的其他内容
[dxk@admin ~]$ grep -o hello file1
hello
hello
hello
hello
hello
[dxk@admin ~]$ grep hello file1
hello oracle
hello mysql
hello php
hello c#
hello c++
【例 5】
显示没有匹配到的内容
在file1文件中查找没有“mysql”字段的行的内容
[dxk@admin ~]$ cat file1
hello oracle
hELlO java
hello mysql
hello php
hello c#
hello c++
[dxk@admin ~]$ grep -v mysql file1
hello oracle
hELlO java
hello php
hello c#
hello c++
【例 6】
显示匹配到的内容的同时打印出其相邻的几行
[dxk@admin ~]$ grep mysql file1
hello mysql
#显示具有'mysql'字段的行并打印出该行以上的两行
[dxk@admin ~]$ grep -B 2 mysql file1 #可以理解为BEFORE
hello oracle
hELlO java
hello mysql
#显示具有'mysql'字段的行并打印出该行以下的两行
[dxk@admin ~]$ grep -A 2 mysql file1 #-A 可以理解为AFTER
hello mysql
hello php
hello c#
#显示具有'mysql'字段的行并打印出该行以下的两行和以上的两行
[dxk@admin ~]$ grep -C 2 mysql file1
hello oracle
hELlO java
hello mysql
hello php
hello c#
【例 7】
查看/etc/passwd文件中有没有“root”这个字段,不需要打印出来,只需要给出一个反馈
lll:[root@admin ~]# grep -q root /etc/passwd
[root@admin ~]# echo $?
0 #打印上次命令执行后的状态,返回状态为0表示存在这个字段
四、touch命令
创建文件及修改文件时间戳的命令 touch
(一)概述
一是用于把已存在文件的时间标签更新为系统当前的时间(默认方式),它们的数据将原封不动地保留下来;二是用来创建新的空文件
用法: touch [选项] 文件名
选项:
- -a:只修改文件的access(访问)时间.
- -c:或–no-create 不创建不存在的文件。
- -d:使用指定的日期时间,而非现在的时间
- -m:指修改Modify(修改)时间,而不修改access(访问)时间
- -r file:使用指定file文件的时间戳(access,modify)更新文件的时间戳(access,modify)
注:
access:表示最后一次访问(仅仅是访问,没有改动)文件的时间
modify:表示最后一次修改文件的时间
change:表示最后一次对文件属性改变的时间,包括权限,大小,属性等等 - -t:将时间修改为参数指定的日期。-t选项类似于-d选项,不过指定的时间格式有些差别
(二)实例
【例 1】
创建一个新文件file1
[dxk@localhost ~]$ date
Mon Jul 20 11:57:05 CST 2020
[dxk@localhost ~]$ touch file1
[dxk@localhost ~]$ stat file1 #查看file1文件的属性信息
File: `file1'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: 802h/2050d Inode: 534518 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 500/ dxk) Gid: ( 500/ dxk)
Access: 2020-07-20 11:57:13.186697029 +0800 #访问时间
Modify: 2020-07-20 11:57:13.186697029 +0800 #修改时间
Change: 2020-07-20 11:57:13.186697029 +0800 #改动时间
【例 2】
把刚才创建的file1已存在文件的时间标签更新为系统当前的时间
[dxk@localhost ~]$ ls
file1
[dxk@localhost ~]$ touch -a file1
[dxk@localhost ~]$ stat file1
File: `file1'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: 802h/2050d Inode: 534518 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 500/ dxk) Gid: ( 500/ dxk)
Access: 2020-07-20 11:59:59.117697457 +0800 #可以看到Access时间被刷新为当前的系统时间
Modify: 2020-07-20 11:57:13.186697029 +0800
Change: 2020-07-20 11:59:59.117697457 +0800 ##可以看到Change时间被刷新为当前的系统时间
【例 3】
不创建不存在的文件
[dxk@localhost ~]$ ls
file1
[dxk@localhost ~]$ touch -c file1
[dxk@localhost ~]$ touch -c file2
[dxk@localhost ~]$ ls
file1
【例 4】
按照指定时间创建文件
[dxk@localhost ~]$ date
Mon Jul 20 12:08:47 CST 2020
[dxk@localhost ~]$ touch -d "20000101 11:11:11" file2 #时间格式的使用一定要注意,如果是时间和日期都要被指定一定要加上双引号
[dxk@localhost ~]$ stat file2
File: `file2'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: 802h/2050d Inode: 534519 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 500/ dxk) Gid: ( 500/ dxk)
Access: 2000-01-01 11:11:11.000000000 +0800
Modify: 2000-01-01 11:11:11.000000000 +0800
Change: 2020-07-20 12:09:09.444698676 +0800 #ctime不会变为设定时间,但更新为当前服务器的时间
【例 5】
将刚才创建的file2文件的Modify时间修改为2020年2月2日12时12分12秒
[dxk@localhost ~]$ touch -m "20200202 12:12:12" file2
[dxk@localhost ~]$ stat file2
File: `file2'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: 802h/2050d Inode: 534519 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 500/ dxk) Gid: ( 500/ dxk)
Access: 2000-01-01 11:11:11.000000000 +0800
Modify: 2020-07-20 12:12:39.716698928 +0800
Change: 2020-07-20 12:12:39.716698928 +0800 #改动时间会随之也被修改
【例 6】
按照file2文件的时间戳创建file3文件
[dxk@localhost ~]$ date
Mon Jul 20 12:15:23 CST 2020
[dxk@localhost ~]$ ls
file1 file2
[dxk@localhost ~]$ touch -r file2 file3
[dxk@localhost ~]$ stat file2
……省略部分输出信息……
Access: 2000-01-01 11:11:11.000000000 +0800
Modify: 2020-07-20 12:12:39.716698928 +0800
Change: 2020-07-20 12:12:39.716698928 +0800
[dxk@localhost ~]$ stat file3
File: `file3'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: 802h/2050d Inode: 534520 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 500/ dxk) Gid: ( 500/ dxk)
Access: 2000-01-01 11:11:11.000000000 +0800 #可以看到file3文件的三个时间均和file2文件的时间一样
Modify: 2020-07-20 12:12:39.716698928 +0800
Change: 2020-07-20 12:15:39.051696663 +0800
总结:
touch 命令不光可以用来创建文件(当指定操作文件不存在时,该命令会在当前位置建立一个空文件),此命令更重要的功能是修改文件的时间参数(但当文件存在时,会修改此文件的时间参数)
Linux 系统中,每个文件主要拥有 3 个时间参数(通过 stat 命令进行查看),分别是文件的访问时间、数据修改时间以及状态修改时间:
- 访问时间(Access Time,简称 atime):只要文件的内容被读取,访问时间就会更新。例如,使用 cat 命令可以查看文件的内容,此时文件的访问时间就会发生改变
- 数据修改时间(Modify Time,简称 mtime):当文件的内容数据发生改变,此文件的数据修改时间就会跟着相应改变
- 状态修改时间(Change Time,简称 ctime):当文件的状态发生变化,就会相应改变这个时间。比如说,如果文件的权限或者属性发生改变,此时间就会相应改变
五、Linux文件系统之 inode、block、superblock
文件存储在硬盘上,硬盘的最小存储单位叫做扇区sector,每个扇区存储512个字节,操作系统在读取硬盘数据时,并不是一个一个扇区去读取,而是按照多个扇区,也就是一次性读取一块数据,这种由扇区组成的块(block)是文件存取最小单位,最常见的块大小为4KB,即8个连续的sector组成一个block。
文件的数据都存在块上,我们知道一个文件除了存储的数据以外还有一部分数据,我们称为元数据,如文件创建日期,大小等等,这种存放元数据的区域我们称为inode
Linux文件系统可以简单分为 inode table和data area,inode table中存有inode,每个inode中记录了文件的元数据、Linux文件系统的文件权限(rwx)、文件属性(拥有者、群组、时间参数等)以及文件的内容。 文件系统通常会将这两部份的数据分别存放在不同的区块,权限与属性放置到inode中,至于实际内容则放置到data block区块中。另外,还有一个超级区块(superblock)会记录整个文件系统的整体信息,包括inode与block的总量、使用量、剩余量等。
superblock:记录此filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及档案系统的格式与相关信息等;
inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的资料所在的block 号码
inode 的默认大小为 128 Byte,用来记录文件的权限(r、w、x)、文件的所有者和属组、文件的大小、文件的状态改变时间(ctime)、文件的最近一次读取时间(atime)、文件的最近一次修改时间(mtime)
block:实际记录文件的内容,若文件太大时,会占用多个block 。
block 的大小可以是 1KB、2KB、4KB,默认为 4KB。block 用于实际的数据存储,如果一个 block 放不下数据,则可以占用多个 block
例如,有一个 10KB 的文件需要存储,则会占用 3 个 block,虽然最后一个 block 不能占满,但也不能再放入其他文件的数据。这 3 个 block 有可能是连续的,也有可能是分散的
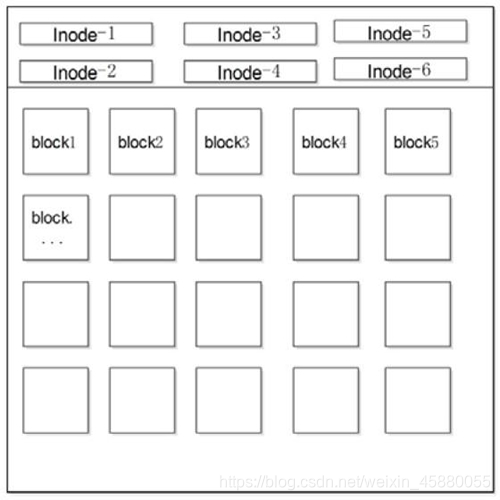
inode中包含文件的元数据,可以通过stat命令查看文件的元数据
[root@admin ~]# stat anaconda-ks.cfg
文件:"anaconda-ks.cfg"
大小:1588 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:201326659 硬链接:1
权限:(0600/-rw-------) Uid:( 0/ root) Gid:( 0/ root)
环境:system_u:object_r:admin_home_t:s0
最近访问:2020-07-18 21:13:22.602931914 +0800
最近更改:2020-06-29 17:12:43.748423188 +0800
最近改动:2020-06-29 17:12:43.748423188 +0800
创建时间:-
inode也会消耗磁盘空间,在磁盘格式化时,操作系统会自动将磁盘分为两个区域,一个数据区,一个inode区,存放inode所包含的信息,整个磁盘的可以使用容量由inode和磁盘空间共同决定,当inode消耗完之后,磁盘空间还有剩余也无法存储数据。
读取文件流程,以要读取/etc/fstab文件内容为例:
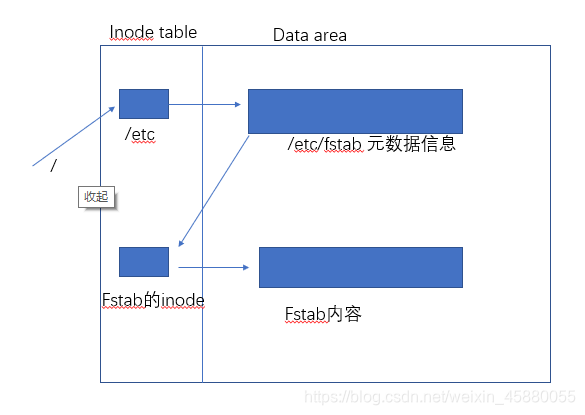
目录文件当然也有自己的inode和block(即数据域)。/etc目录文件的block中存储的就是许多文件的inode信息,找到fstab文件的inode,便可以找到fstab文件的block,就可以读取其中的数据信息
六、ln命令
在文件或目录之间创建链接的命令 ln
Linux 链接分两种,一种被称为硬链接(Hard Link),另一种被称为符号链接或软连接(Symbolic Link)。默认情况下,ln 命令产生硬链接。
(一)硬链接
硬连接指通过索引节点来进行连接。在 Linux 的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。
在 Linux 中,多个文件名指向同一索引节点是存在的。比如:A 是 B 的硬链接(A 和 B 都是文件名),则 A 的目录项中的 inode 节点号与 B 的目录项中的inode 节点号相同,即一个 inode 节点对应两个不同的文件名,两个文件名指向同一个文件,A 和 B 对文件系统来说是完全平等的。删除其中任何一个都不会影响另外一个的访问。 硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能
其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除
注意:硬链接的源文件不能是目录
(二)软链接
另外一种连接称之为符号连接(Symbolic Link),也叫软连接。软链接文件有类似于 Windows 的快捷方式。它实际上是一个特殊的文件
在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。比如:A 是 B 的软链接(A 和 B 都是文件名),A 的目录项中的 inode 节点号与 B 的目录项中的 inode 节点号不相同,A 和 B 指向的是两个不同的 inode,继而指向两块不同的数据块。但是 A 的数据块中存放的只是 B 的路径名(可以根据这个找到 B 的目录项)。A 和 B 之间是“主从”关系,如果 B 被删除了,A 仍然存在(因为两个是不同的文件),但指向的是一个无效的链接
用法: ln [选项] 源文件 目标文件
选项:
- -s:建立软链接文件。如果不加 “-s” 选项,则建立硬链接文件
- -f:强制。如果目标文件已经存在,则删除目标文件后再建立链接文件
- 不加选项是创建硬链接
(三)实例
【例 1】
创建硬链接
[root@admin ~]# touch demo #创建一个demo文件,并写入内容
[root@admin ~]# vim demo
[root@admin ~]# cat demo
I am a test .
[root@admin ~]# stat demo
文件:"demo"
大小:14 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:201344904 硬链接:1 #这时可以看到此文件的硬链接数是1
……省略部分输出……
[root@admin ~]# ln /root/demo /demo.link #给刚创建的demo文件建立一个名为demo.link的硬链接
[root@admin ~]# stat demo
文件:"demo"
大小:14 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:201344904 硬链接:2 #这时硬链接数为2
……省略部分输出……
[root@admin ~]# ll /demo.link
-rw-r--r--. 2 root root 14 7月 20 15:20 /demo.link
[root@admin ~]# cat /demo.link #可以看到查看demo.link中的内容和demo中的内容是一样的 因为两个文件的inode是一样的,所以指向同一个block那么信息肯定是一样的
I am a test .
【例 2】
如果任意一个修改其中的内容,那么另外一个的内容会改变吗?
#对源文件进行写入操作,链接文件会改变吗?
[root@admin ~]# vim demo #这时我们给源文件添加第二行的内容
[root@admin ~]# cat demo
I am a test .
have a try
[root@admin ~]# cat /demo.link #此时可以看到链接文件也同时可以看到相同的信息
I am a test .
have a try
#对链接文件进行操写入作,源文件会随之改变吗?
[root@admin ~]# vim /demo.link
[root@admin ~]# cat /demo.link
I am a test .
have a try
have a try ,too
[root@admin ~]# cat /root/demo #可以看到也会随之改变
I am a test .
have a try
have a try ,too
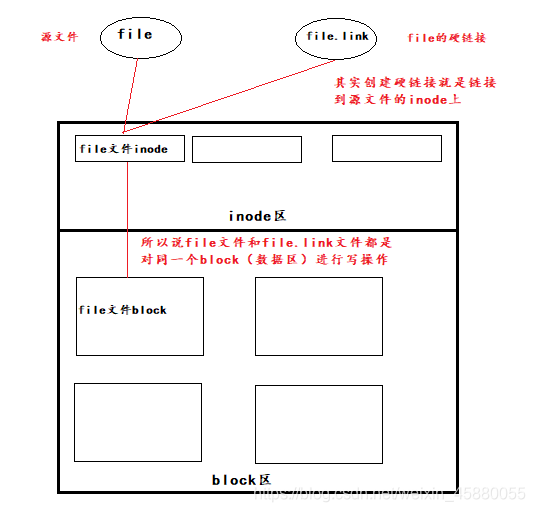
#其实归根结底,对任何一个文件的操作都是在同一个block上进行的,所以其中任何一个对文件的写入操作,另一个也是同样可以看到的
以下图示更便于理解:
【例 3】
如果,删除其中任何一个文件,另一个会受影响吗?
#删除源文件,看看链接文件的情况
[root@admin ~]# rm -rf /root/demo
[root@admin ~]# cat /demo.link #可以看到另一个没有受到影响
I am a test .
have a try
have a try ,too
#恢复原样后,我们看看删除链接文件后,源文件的情况
[root@admin ~]# rm -rf /demo.link
[root@admin ~]# cat /root/demo #同样,也未受影响
I am a test .
have a try
have a try ,too
这里有必要要解释的是,rm命令删除的是一个文件的inode,而非block
而正是因为file文件的inode同时被file文件和file.link文件所同时指向,所以删除其中任意一个,另一个也不会受到影响。一个inode可以被许多文件所指向,只要有一个指向inode,那么该文件就不会被彻底覆盖(通俗地讲是删除,其实删除一个文件不是真正意义上的清空该文件的数据,而是空间被释放出来,其实数据还是在的,只不过后面会被其他数据所覆盖,类似于堆栈)
【例 4】
建立硬链接文件,目标文件没有写文件名,会和原名一致
[root@admin /]# touch demo1 #在/下创建文件demo1
[root@admin /]# cd
[root@admin ~]# ln /demo1 #在家目录下给/demo1文件创建硬链接,未指定目标文件名
[root@admin ~]# ls
anaconda-ks.cfg demo demo1 file test #可以看到创建后的硬链接文件名和源文件名是一致的
硬链接的源文件名可以是绝对路径,也可以是相对路径;硬链接的源文件不能是目录
【例 5】
创建软连接
[root@admin ~]# ln -s /root/demo1 /demo11
[root@admin ~]# ll /demo11
lrwxrwxrwx. 1 root root 5 7月 20 16:20 /demo11 -> demo1 #软连接这里会有符号
【例 6】
同样的对源文件和软连接文件的写操作都会对双方均生效
创建的软连接文件有自己的inode和block,但是连接文件的block中存放的是源文件的路径名(可以根据这个找到源文件的inode)继而找到源文件的block
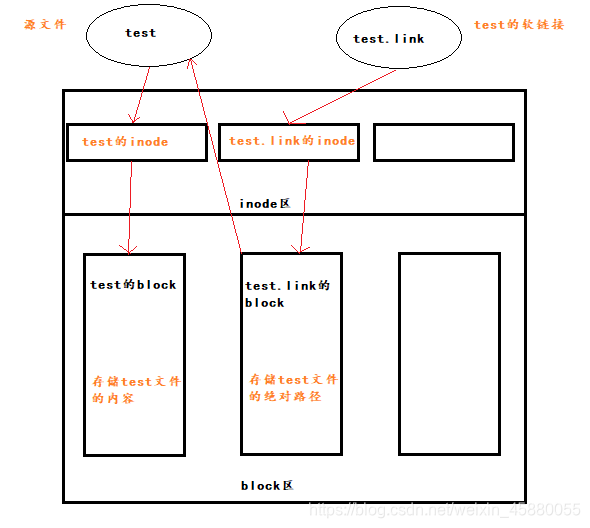
删除软链接文件,源文件不受影响。但如果删除源文件,那么软连接文件还会存在,不过无法去找到源文件,那么便会是一个失效的路径
切记:软链接文件的源文件必须写成绝对路径(即使源文件和你当前工作目录是在同一路径下),而不能写成相对路径(硬链接没有这样的要求);否则软链接文件会报错
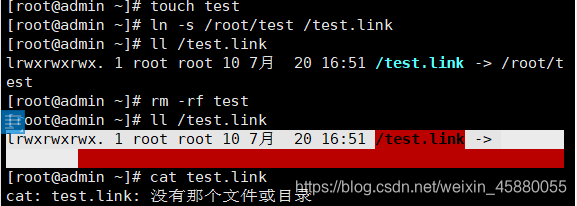
[root@admin ~]# touch test
[root@admin ~]# ln -s /root/test /test.link #软链接文件的源文件必须写成绝对路径,即使源文件是在当前目录下
[root@admin ~]# ll /test.link #如果是用绝对路径创建的软连接,那么查看的时候,链接文件会是浅蓝色的,如果是用相对路径创建的软连接,那么在查看该软链接文件的时候会是红色的
lrwxrwxrwx. 1 root root 10 7月 20 16:51 /test.link -> /root/test #这里的指向就是源文件的所在路径
[root@admin ~]# rm -rf test
[root@admin ~]# ll /test.link #删除源文件后,在查看连接文件的时候会显示红色,同时所指向的源文件的路径会闪烁
lrwxrwxrwx. 1 root root 10 7月 20 16:51 /test.link -> /root/test
[root@admin /]# cat test.link #可以看到软链接文件还是存在的,但是去查看的时候,系统会提示没有那个文件或目录,因为源文件的inode已经不存在
cat: test.link: 没有那个文件或目录
具体效果:
软连接是可以链接目录的。但是如果一个软连接文件链接的是目录,如果想删除该软连接,那么切记一定不要在删除的该软连接文件名后加路径分割符/,否则会删除所链接目录下的所有文件,切记切记!!!
七、Linux文件删除原理
(一)原理
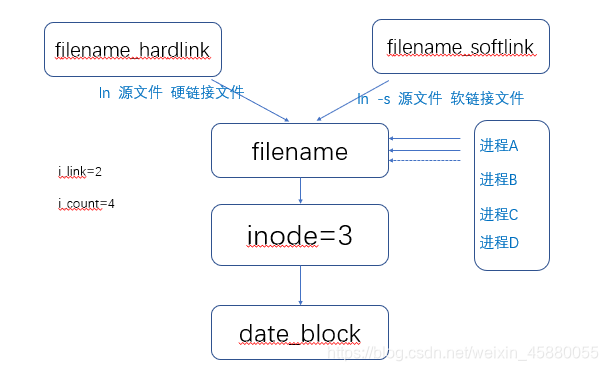
Linux是通过link的数量来控制文件删除的,只有当一个文件不存在任何link的时候,这个文件才会被删除。一般来说,每个文件都有2个link计数器:i_count 和 i_nlink。
i_count的意义是当前文件使用者(或被调用)的数量,i_nlink 的意义是介质连接的数量(硬链接的数量);可以理解为i_count是内存引用计数器,i_nlink是磁盘的引用计数器。
当一个文件被某一个进程引用时,对应i_count数就会增加;当创建文件的硬链接的时候,对应i_nlink数就会增加。
对于删除命令rm而言,实际就是减少磁盘引用计数i_nlink。这里就会有一个问题,如果一个文件正在被某个进程调用,而用户却执行rm操作把文件删除了,那么会出现什么结果呢?当用户执行rm操作删除文件后,再执行ls或者其他文件管理命令,无法再找到这个文件了,但是调用这个删除的文件的进程却在继续正常执行,依然能够从文件中正确的读取及写入内容。这又是为什么呢?
这是因为rm操作只是将文件的i_nlink减少了,如果没其它的链接i_nlink就为0了;但由于该文件依然被进程引用,因此,此时文件对应的i_count并不为0,所以即使执行rm操作,但系统并没有真正删除这个文件,当只有i_nlink及i_count都为0的时候,这个文件才会真正被删除。也就是说,还需要解除该进程的对该文件的调用才行。
(二)软、硬链接的删除
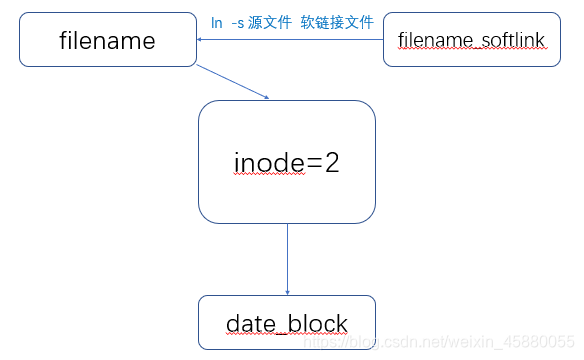
硬链接知识小结:
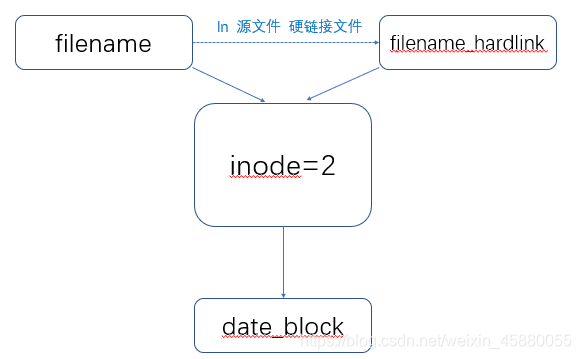
1、具有相同Inode节点号的多个文件是互为硬链接文件。
2、删除硬链接文件或者删除源文件任意之一,文件实体并未被删除。
3、只有删除了源文件及所有对应的硬链接文件,文件实体才会被删除。
4、当所有硬链接文件及源文件被删除后,再存放新的数据会占用这个文件的空间,或者磁盘fsck检查的时候,删除的数据也会被系统回收。
5、硬链接文件就是文件的另一个入口。
6、可以通过给文件设置硬链接文件,来防止重要文件被误删。
7、硬链接文件可以用rm命令删除。
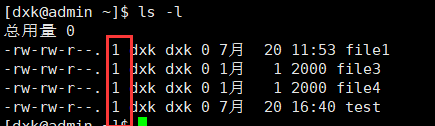
8、对于静态文件(没有进程正在调用的文件)来说,当对应硬链接数位0(i_link),文件就被删除。i_link的查看方法(ls -l结构的第三列就是)
软链接知识小结:
1、 软链接类似windows的快捷方式(可以通过readlink查看其指向)。
2、 软链接类似一个文本文件,里面存放的是源文件的路径,指向源文件实体。
3、 删除源文件,软链接文件依然存放,但是无法访问指向的源文件路径内容了。
4、 失效的时候一般是红字白底闪烁提示。
5、 软链接和源文件是不同类型的文件,也是不同的文件。inode号也不相同。
6、 删除软链接文件可以用rm命令。
目录链接:
1、 对于目录,不可以创建硬链接,但可以创建软链接
2、 目录的硬链接不能跨越文件系统
3、 每个目录下面都有一个硬链接“.”号,和对应上级目录的硬链接“…”。
4、 在父目录里面创建一个子目录,父目录的链接数增加1(子目录里都有…来指向父目录)。但是在父目录里创建文件,父目录的链接数不会增加。
八、rm命令
删除某个目录及其所有文件及子目录的命令 rm
(一)概述
该命令用来删除Linux系统中的文件或目录。通常情况下rm不会删除目录,你必须通过指定参数-r或-R来删除目录
另外rm通常可以将该文件或目录恢复(注意,rm删除文件其实只是将指向数据块的索引点(information nodes)释放,只要不被覆盖,数据其实还在硬盘上。如果想要保证文件的内容无法复原,可以使用命令shred 。 另外一般还是要慎用rm -rf * 这样的命令
用法: rm [选项]… 文件…
选项:
- -f :强制删除,忽略不存在的文件,和 -i 选项相反,使用 -f,系统将不再询问,而是直接删除目标文件或目录从不给出提示
- -i : 交互式删除文件,删除时给出提示
- -r:递归删除目录下面文件以及子目录下的文件
- -R:同r
- -v:显示运行时详细信息
(二)实例
【例 1】
rm 命令如果任何选项都不加,则默认执行的是"rm -i 文件名",也就是在删除一个文件之前会先询问是否删除
[root@admin ~]# rm fil1
rm:是否删除普通空文件 "fil1"?n
[root@admin ~]# rm -i fil1
rm:是否删除普通空文件 "fil1"?
【例 2】
如果需要删除目录,则需要使用 -r 选项。例如:
[root@admin ~]# rm Diectory
rm: 无法删除"Diectory": 是一个目录
#如果不加"-r"选项,则会报错
[root@admin ~]# rm -r Diectory/
rm:是否进入目录"Diectory/"? ^C
[root@admin ~]# rm -r Diectory
rm:是否进入目录"Diectory"? y
rm:是否删除普通空文件 "Diectory/1"?y
rm:是否删除目录 "Diectory/tt"?y
rm:是否删除目录 "Diectory"?y
#会分别询问是否进入子目录、是否删除子目录
如果每级目录和每个文件都需要确认,效率就会太低
【例 3】
如果要删除的目录中有 1000个子目录或子文件,那么普通的 rm 删除最少需要确认 1000次。所以,在真正删除文件的时候,我们会选择强制删除
[root@admin ~]# mkdir Dictory
[root@admin ~]# rm -rf Dictory #强制删除,无需询问
虽然 “-rf” 选项是用来删除目录的,但是删除文件也不会报错。所以,为了使用方便,一般不论是删除文件还是删除目录,都会直接使用 “-rf” 选项
【例 3】
删除时显示删除情况
[root@admin ~]# rm -rfv Dictory
已删除"Dictory/file"
已删除"Dictory/file1"
已删除"Dictory/file2"
已删除目录:"Dictory/dir"
已删除目录:"Dictory"
【例 5】
另一种强制删除的方法,也就是在删除时不提供交互信息,不询问
[root@admin ~]# type rm
rm 是 `rm -i' 的别名
#因为执行rm命令实际是在执行rm -i,所以我们可以通过转义,还原回本来的用法
[root@admin ~]# mkdir Diectory
[root@admin ~]# rm -r Diectory
rm:是否删除目录 "Diectory"?n
[root@admin ~]# \rm -r Diectory #没有询问直接删除了,等价于执行rm -rf Diectory
九、cp命令
拷贝文件或目录的命令 cp
(一)概述
cp指令用于复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到此目录中。若同时指定多个文件或目录,而最后的目的地并非一个已存在的目录,则会出现错误信息
用法: cp [选项]… 源文件… 文件
选项:
- -a:相当于 -d、-p、-r 选项的集合,这几个选项我们一一介绍;
- -d:如果源文件为软链接(对硬链接无效),则复制出的目标文件也为软链接;
- -i:询问,如果目标文件已经存在,则会询问是否覆盖;
- -l:把目标文件建立为源文件的硬链接文件,而不是复制源文件;
- -s:把目标文件建立为源文件的软链接文件,而不是复制源文件;
- -p:复制后目标文件保留源文件的属性(包括所有者、所属组、权限和时间);
- -r:递归复制,用于复制目录;
- -u:若目标文件比源文件有差异,则使用该选项可以更新目标文件,此选项可用于对文件的升级和备用
需要注意的是,源文件可以有多个,但这种情况下,目标文件必须是目录才可以。
(二)实例
【例 1】
cp 命令既可以复制文件,也可以复制目录。我们先来看看如何复制文件
[root@admin ~]# touch test
[root@admin ~]# cp test /tmp/test.bak
#将test文件拷贝到/tmp下并命名拷贝后的文件为test.bak
如果是 cp test /tmp/ 也可以,系统会默认用源文件的名字来命名
如果复制的目标位置已经存在同名的文件,则会提示是否覆盖,因为 cp 命令默认执行的是“cp -i”的别名
[root@admin ~]# cp test /tmp/test.bak
cp:是否覆盖"/tmp/test.bak"?
【例 2】
如何复制目录,其实复制目录只需使用“-r”选项即可
[root@admin ~]# mkdir dir
[root@admin ~]# cp -r dir /tmp/dir.bak
#将dir目录拷贝到/tmp下并命名拷贝后的目录为dir.bak
如果是 cp dir /tmp/ 也可以,系统会默认用源文件的名字来命名
【例 3】
复制软链接文件
[root@admin ~]# ln -s /root/file /tmp/dir/file.link1 #这里创建一个源文件为/root/file的软连接的文件/tmp/dir/file.link1
[root@admin ~]# ll //tmp/dir/file.link1
lrwxrwxrwx. 1 root root 10 7月 20 21:26 //tmp/dir/file.link1 -> /root/file
#然后,我们对该软链接文件进行拷贝,不加-d选项,复制后的文件名为file.link1.bak1
[root@admin ~]# cp /tmp/dir/file.link1 /root/file.link1.bak1
#用-d选项再一次复制该软连接文件,复制后的文件名为file.link1.bak2
[root@admin ~]# cp -d /tmp/dir/file.link1 /root/file.link1.bak2
#查看不加-d选项复制后的情况
[root@admin ~]# ll file.link1.bak1
-rw-r--r--. 1 root root 0 7月 20 21:31 file.link1.bak1 #我们发现不加-d选项实际上复制的是软连接的源文件而不是软连接文件
#查看加了-d选项复制后的情况
[root@admin ~]# ll file.link1.bak2 #而如果加入了"-d"选项,则会复制软链接文件
lrwxrwxrwx. 1 root root 10 7月 20 21:34 file.link1.bak2 -> /root/file
所以:这个例子说明,如果在复制软链接文件时不使用 “-d” 选项,则 cp 命令复制的是源文件,而不是软链接文件;只有加入了 “-d” 选项,才会复制软链接文件。注意,"-d" 选项对硬链接是无效的
【例 3】
保留源文件属性复制
我们发现,在执行复制命令后,目标文件的时间会变成复制命令的执行时间,而不是源文件的时间
[root@admin ~]# ll /tmp/file
-rw-rw-r--. 1 dxk dxk 0 7月 20 20:36 /tmp/file
[root@admin ~]# cp /tmp/file /root/file.bak
[root@admin ~]# ll file.bak
-rw-r--r--. 1 root root 0 7月 20 21:42 file.bak
#注意对比源文件的时间、所有者及属组和复制后的差异
#很明显可以看到,时间和所有者及属组均发生了变化,由于复制命令由root用户执行,所以目标文件的所有者及属组成为了root,而且时间也变成了复制命令的执行时间
而当我们执行备份、曰志备份的时候,这些文件的时间可能是一个重要的参数,这就需执行 “-p” 选项了。这个选项会保留源文件的属性,包括所有者、所属组和时间
[root@admin ~]# ll /tmp/file
-rw-rw-r--. 1 dxk dxk 0 7月 20 20:36 /tmp/file
[root@admin ~]# cp -p /tmp/file /root/file1
[root@admin ~]# ll /root/file1
-rw-rw-r--. 1 dxk dxk 0 7月 20 20:36 /root/file1
#这样源文件和目标文件的所有属性都一致,包括时间
说明:如果是root用户使用cp -p 拷贝普通用户的文件那么拷贝后的文件的所有属性不会变(包括所有者、属组、时间戳),但是如果是普通用户使用cp -p 拷贝其他用户的文件那么拷贝后的文件的所有者和属组会改变成该用户的,但是时间属性不会变
【例 4】
"-l" 和 “-s” 选项
我们如果使用 “-l” 选项,则目标文件会被建立为源文件的硬链接;而如果使用 “-s” 选项,则目标文件会被建立为源文件的软链接
注意:这两个选项和 “-d” 选项是不同的,“d” 选项要求源文件必须是软链接,目标文件才会复制为软链接;而 “-l” 和 “-s” 选项的源文件只需是普通文件,目标文件就可以直接复制为硬链接和软链接
[root@admin ~]# ll /tmp/dir/file #源文件只是一个普通的文件,而不是软链接文件
-rw-r--r--. 2 root root 0 7月 20 21:58 /tmp/dir/file
[root@admin ~]# cp -l /tmp/dir/file /root/file1 #使用 "-l" 选项,则目标文件会被建立为源文件的硬链接
[root@admin ~]# cp -s /tmp/dir/file /root/file2 #使用了 "-s" 选项,则目标文件会被建立为源文件的软链接
[root@admin ~]# ll /root/file1
-rw-r--r--. 2 root root 0 7月 20 21:58 /root/file1 #拷贝后的/root/file1为源文件的硬链接文件
[root@admin ~]# ll /root/file2
lrwxrwxrwx. 1 root root 13 7月 20 21:59 /root/file2 -> /tmp/dir/file #拷贝后的文件 /root/file2为源文件的软链接文件
十、file命令
显示文件类型的命令 file
(一)概述
file命令用来识别文件类型,也可用来辨别一些文件的编码格式。
Windows通过扩展名来确定文件类型,而linux系统不是以文件后缀来识别文件。它是通过查看文件的头部信息来获取文件类型
用法:file [OPTION…] [FILE…]
选项:
- -i: 输出mime类型的字符串
- -L :查看对应软链接对应文件的文件类型
- -z :尝试去解读压缩文件的内容
如果你想知道某个文件的基本信息,例如是属于ASCII或是数据文件或是二进制文件,且其中有没有使用到动态链接库(share library)等信息,就可以利用file这个命令来查看
(二)实例
【例 1】
查看普通文本文件
[dxk@admin ~]$ file .bashrc
.bashrc: ASCII text #ASCII的纯文本文件
【例 2】
查看可执行文件
[dxk@admin ~]$ file /usr/bin/passwd
/usr/bin/passwd: setuid ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=dee1b9ab6618c6bfb84a14f85ba258c742cf4aec, stripped
可执行文的文件类型信息就比较多了,包括这个文件的SUID权限,兼容Intel x86-64等级的硬件平台性,使用的是Linux内核2.6.32的动态链接库等
【例 3】
查看软链接文件
[root@admin ~]# ll file2
lrwxrwxrwx. 1 root root 13 7月 20 21:59 file2 -> /tmp/dir/file
[root@admin ~]# file file2 #不加选项直接查看软链接文件,会显示源文件的路径
file2: symbolic link to `/tmp/dir/file'
[root@admin ~]# file -L file2 #使用-L选项可以查看源文件的文件类型
file2: ASCII text