爬虫小例子分享(豆瓣评分前250名)
首先,我们先要进行一些准备工作。
1.安装requests第三方库 和 BeautifulSoup第三方库
采用pip指令安装requests库
指令为:pip install requests
如果出现了pip不是内部指令的话,建议卸载一下IDLE,重新安装后,配置好环境变量。
采用pip指令安装beautifulsoup4
指令为:pip install beautifulsoup4
2.requests库是一个处理HTTP请求的第三方,最大的优点是程序编写过程中更接近正常的URL访问过程。

requests第三方库最常用的方法是get()方法,用来获取网页。get()的参数是url,链接必须采用HTTP或HTTPS的方式进行访问。
3.beautifulsoup4库是一个解析和处理HTML和XML的第三方库。
在一些网页中需要用正则表达式筛选标签内容,建议引入re库,re库用来引入正则表达式。
4.在爬虫的时候,有些网站是不会让我们爬虫的,就比如说这个豆瓣评分的网站,我们需要伪装一下,用header请求头来访问网站。
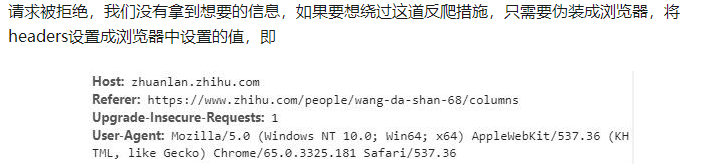
5.具体的反爬可以参考:
反爬虫,请求头设置
6.
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = code
return r.text
通过requests库,得到要访问的网站,将请求头伪装成上面已经写好的请求头,防止网页反爬虫。
raise_for_status():这个方法是专门与异常打交道的方法,该方法有这样一个有趣的功能,它能够判断返回的Response类型状态是不是200。如果是200,他将表示返回的内容是正确的,如果不是200,他就会产生一个HttpError的异常。
具体的Response方法请参考:
Response使用方法
7.
豆瓣评分一共分为10页,每页25部电影,电影网页的html网页的格式为:
https://movie.douban.com/top250?start=0&filter=
我们可以剖析一下这个网站的意思,问号后面,start=num 的意思就是从第几部电影开始,这里面的排序按照数组下标,所以第一部电影开始的话,网站是start=0。
8.
在网页右键点击查看源文件,我们可以看到我们的电影信息都是放在了ol标签中,真正的信息都是放在了li标签中。
for i in range(10):
homepage = ‘https://movie.douban.com/top250’ + min(1, i) * f’?start={i*25}&filter=’
soup = BeautifulSoup(get_html_text(homepage), ‘html.parser’)
movielist = soup(‘ol’)[0]
我们通过第一次遍历循环,遍历10张页面的所有
- 标签,找到所有的电影信息。
for movie in movielist(‘li’):
title = movie(‘span’, class_=‘title’)[0].string
然后找出所有在li标签中的span标签中的电影信息
span class="title"肖申克的救赎span只找span标签中的title属性,这样,我们就获取了250个电影信息的title
9.源码:
import requests
from bs4 import BeautifulSoup
def get_html_text(url, code=‘utf-8’):
“”“get html source code”""
headers = {‘User-Agent’: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ’
‘(KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36’}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = code
return r.text
except requests.exceptions.RequestException:
return ‘’
with open(‘douban.txt’,‘w’, encoding=‘utf-8’) as f:
for i in range(10):
homepage = ‘https://movie.douban.com/top250’ + min(1, i) * f’?start={i*25}&filter=’
soup = BeautifulSoup(get_html_text(homepage), ‘html.parser’)
movielist = soup(‘ol’)[0]
for movie in movielist(‘li’):
title = movie(‘span’, class_=‘title’)[0].string
try:
rating = movie(‘span’, class_=‘rating_num’)[0].string
except IndexError:
rating = ‘无评分’
try:
comments = movie(‘span’, class_=‘inq’)[0].string
except IndexError:
comments = ‘无评论’
f.write(f’{title:10}\t{rating:3}\t{comments}\n’)
10.
