开源软件迭代较慢
DAG:有向无环图
Hadoop计算中间结果落到磁盘,内存占用小
Spark惰性计算,遇到Action算子才执行,内存占用较大,资源利用率较低
RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task
Application:用户编写的Spark应用程序
Task:运行在Executor上的工作单元
Job:一个Job包含多个RDD及作用于相应RDD上的各种操作
Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集
开启虚拟机,打开hadoop集群 用start-all.sh命令
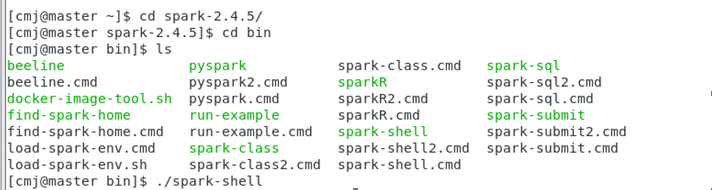
然后先全路径打开spark
- 从文件系统中加载数据创建RDD
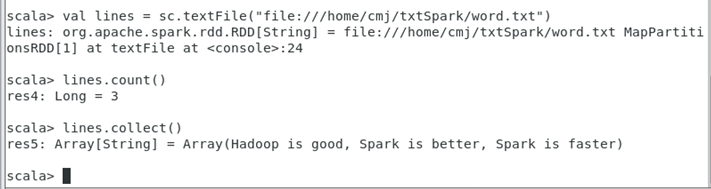
(1)从本地文件系统中加载数据创建RDD
先新建目录 & word.txt文档

(2)从分布式文件系统HDFS中加载数据
创建删除文件夹(需要加-r,删除文件不需要加-r)

输入 “hadoop fs -ls /”命令查看hadoop分布式文件系统HDFS中的文件夹
或者进入http://master:50070/explorer.html#/ 网址直接查看文件夹

输入val hdfsfile = sc.textFile(“hdfs://master:9000/testSpark1/hdfsword.txt”) 命令
因为惰性计算,所以还要输入 hdfsfile.count() 开始执行,截图如下:

2. 通过并行集合(数组)创建RDD
可以调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。

或者,也可以从列表中创建:

3. 常用的RDD转换操作API

(1) filter(func)

(2) map(func)
map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集


(3) flatMap(func)

(4) groupByKey()
groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
(5) reduceByKey(func)
reduceByKey(func)应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果