学习python爬虫一段时间了,想做个实例巩固一下所学的知识。
爬取对象:腾讯招聘网站
不知道是不是被爬的多了,这个网页变动挺大的。
(网上搜到的那些爬虫代码已经不好使了,๑乛◡乛๑)
代码如下:
import urllib
from urllib import request
import re
import json
# 构造请求头信息
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; '
'x64; rv:77.0) Gecko/20100101 Firefox/77.0'}
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?pageSize=10&language=zh-cn&area=cn&'
pat1 = re.compile('"PostId":"(.*?)"')
x = 0
# 爬取1--3页的招聘信息
for i in range(1, 4):
kw = {'pageIndex': i}
kwd = urllib.parse.urlencode(kw)
url_use = url + kwd
req = urllib.request.Request(url_use, headers=header)
data = urllib.request.urlopen(req).read().decode()
# 使用正则表达式获取职位ID号
postId = re.findall(pat1, str(data))
for j in postId:
# 访问职位信息详情页面
url_new = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?postId=%s' % j
req_new = urllib.request.Request(url_new, headers=header)
data_new = urllib.request.urlopen(req_new).read().decode() # 返回的data_new是字符串类型str
# 将字符串转换成字典
data_json = json.loads(data_new)
# 获取职位信息
x += 1
print('------------第%s个职位信息------------' % x)
print('职位名称:'+data_json['Data']['RecruitPostName'])
print('工作职责:\n'+data_json['Data']['Responsibility'])
print('工作要求:\n'+data_json['Data']['Requirement'])
执行结果太长,附上部分执行结果
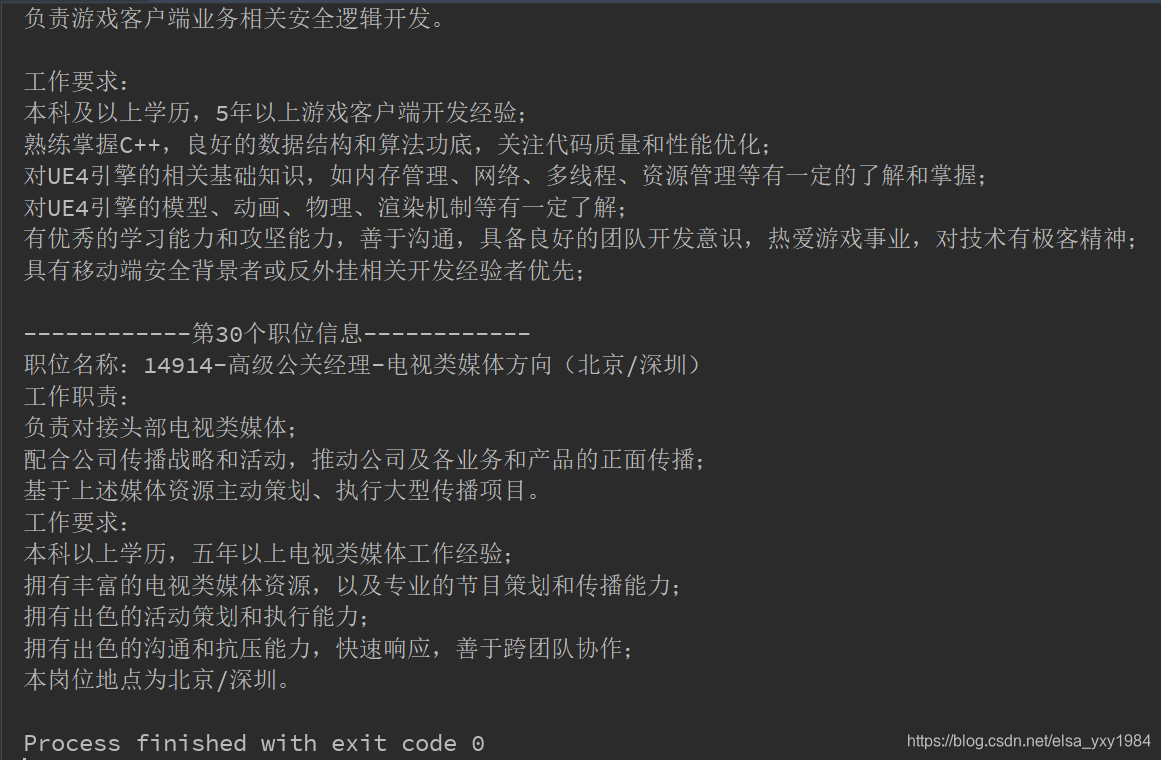
注:文章内容主要是记录学习过程中遇到的一些问题,以及解决方法。留个记录,同时分享给有需要的人。如有不足之处,欢迎指正,谢谢!