title: Hadoop单机模式/伪分布式搭建
date: 2020-03-18 23:34:17
tags: Hadoop
Hadoop单机模式/伪分布式搭建
准备
Hadoop三种安装模式简介
Hadoop共有三种安装模式可以使用:单机模式、伪分布式、完全分布式
1.Hadoop单机模式
单机模式是Hadoop默认的安装模式,这种安装模式主要就是并不配置更多的配置文件,只是保守的去设置默认的几个配置文件中的初始化参数,他并不与其他节点进行交互,并且也不使用HDFS文件系统,它主要就是为了调试MapReduce程序而生。
2.Hadoop伪分布式安装模式
Hadoop伪分布式安装,需要配置5个常规的配置文件(XML),并且这里涉及到了NameNode和DataNode节点交互问题,而且NameNode和DataNode在同一个节点上,还需要配置互信。其实从严格意义上来讲,我们的伪分布式集群,就已经可以称之为真正意义上的集群了,而且这里也包含了hdfs和MapReduce所有组件,只不过就是所有组件在同一个节点上而已。
3.Hadoop完全分布式安装模式
Hadoop完全分布式集群主要分为:常规Hadoop完全分布式集群和Hadoop HA集群(这里我们主要针对的是NameNode个数和NameNode的高可用保障机制而言)。由此可知较伪分布式集群而言,我们的完全分布式集群,所有处理节点并不在同一个节点上,而是在多个节点上。
搭建环境准备
这里介绍本文所用的搭建环境
1、虚拟机:使用VMware15.5,XShell6&Xftp,CentOS7
2、Hadoop:Hadoop-2.7.7,jdk-8u231
需要提前下载并安装好虚拟机相关软件,并下载所需Hadoop与jdk的压缩包(.tar.gz)
使用前请确认虚拟机网络已经配置好且XShell可以连接到虚拟机
通用设置配置
下载/解压安装包
这里我们在root目录下创建一个download文件夹
mkdir download
再创建一个app文件夹用于存放解压的安装包
mkdir app
此时可以使用ls命令查看文件夹是否创建成功
ls

使用Xftp将下载好的压缩包传输到download文件夹下
接下来进入download目录
cd download
ls //检查是否传输成功
将压缩包解压到app文件夹下
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /root/app //注意你的jdk版本和Hadoop版本,如果不同及时修改
tar -zxvf hadoop-2.7.7.tar.gz -C /root/app
接下来我们进入app目录,检查是否解压成功
cd /root/app
ls
可以看到:
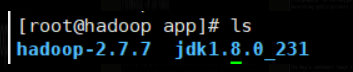
说明解压成功
修改主机名
vi /etc/hostname
将配置文件内原有内容删除并修改为你要修改的主机名,本文修改主机名为“Hadoop”,修改完后保存并退出。**注意:**修改完后需要重启虚拟机才会生效
可以通过以下命令查看当前主机名
hostname
配置hosts
打开hosts配置文件
vi /etc/hosts
修改hosts配置文件内容
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.48.105 hadoop //添加此项,内容为你的虚拟机主机IP+主机名
关闭防火墙
systemctl start firewalld //立即启动防火墙
systemctl stop firewalld //立即关闭防火墙
systemctl status firewalld //查看防火墙状态
systemctl disable firewalld //开机禁用防火墙
systemctl enable firewalld //开机启动防火墙
可以先通过命令查看防火墙状态,如果防火墙处于active状态需要先关闭防火墙
设置ssh免密登录
ssh-keygen
输入后一路回车即可,最后会如下图
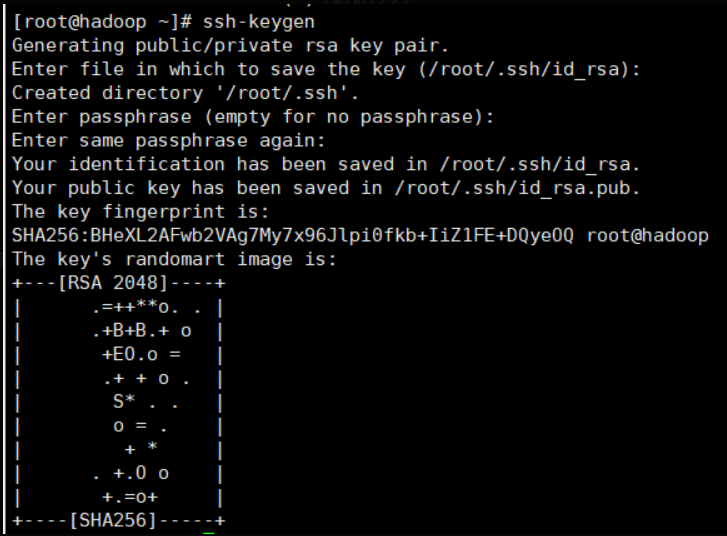
此时会在 ~/.ssh 目录下生成 id_rsa 和 id_rsa.pub 两个文件,id_rsa 为私钥, id_rsa.pub 为公钥,紧接着将公钥文件复制成 authorized_keys 文件(存放远程免密登录的公钥,主要通过这个文件记录多台机器的公钥 )
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
此时无密码登录已经配置完成,我们测试一下
ssh hadoop
第一次会提示你是否继续操作,输入yes即可成功登录
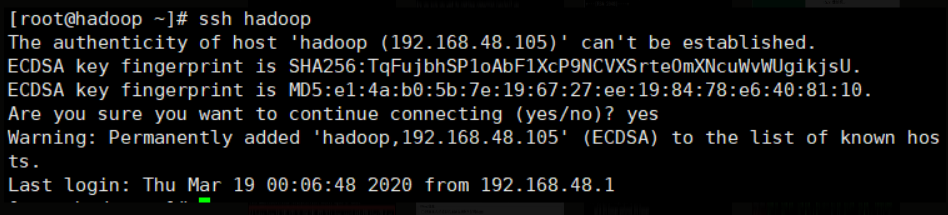
配置Java环境变量
打开环境变量配置文件
vi /etc/profile
在配置文件末尾加入
export JAVA_HOME=/root/app/jdk1.8.0_231
export PATH=$PATH:$JAVA_HOME/bin
刷新配置文件
source /etc/profile
输入java,如果出现以下内容,说明Java配置成功
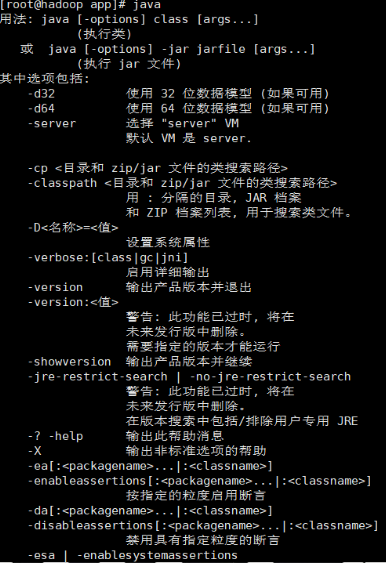
配置Hadoop环境变量
打开环境变量配置文件
vi /etc/profile
在配置文件末尾加入
export HADOOP_HOME=/root/app/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新配置文件
source /etc/profile
输入hadoop version,如果出现以下内容,说明配置成功

**注:**Hadoop安装后默认即为单机模式,不需要修改其他配置文件,也就是说到这里,Hadoop单机模式已经配置成功,接下来我们开始伪分布式的配置
伪分布式配置
首先进入到Hadoop的配置文件目录
cd /root/app/hadoop-2.7.7/etc/hadoop
配置 hadoop-env.sh
vi hadoop-env.sh
将JAVA_HOME修改为你的jdk安装路径

配置core-site.xml
vi core-site.xml
在/中间添加配置
<configuration>
<!--指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!--指定HADOOP运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/tmp</value>
</property>
</configuration>
配置hdfs-site.xml
vi hdfs-site.xml
在/中间添加配置
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置 mapred-site.xml
vi mapred-site.xml.template
在/中间添加配置
<configuration>
<!--指定mr运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
然后将该文件复制一份并重命名
cp mapred-site.xml.template mapred-site.xml
配置yarn-site.xml
vi yarn-site.xml
在/中间添加配置
<configuration>
<!-- 指定YARN的老大(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
格式化NameNode
cd /root/app/hadoop-2.7.7/bin
hdfs namenode -format
注,此代码的作用是格式化文件,故只能执行一次,不要轻易执行第二次
如果没有报错且在最后显示以下信息,说明格式化成功

启动Hadoop
cd /root/app/hadoop-2.7.7
sbin/start-all.sh
第一次启动可能需要输入几个yes,如下图所示代码
再次启动时就不需要了,如下图
接下来使用jps命令查看进程
jps
如果看到以下进程,恭喜你,Hadoop伪分布式搭建成功

在浏览器中输入地址登录HDFS管理页面:
192.168.48.105:50070
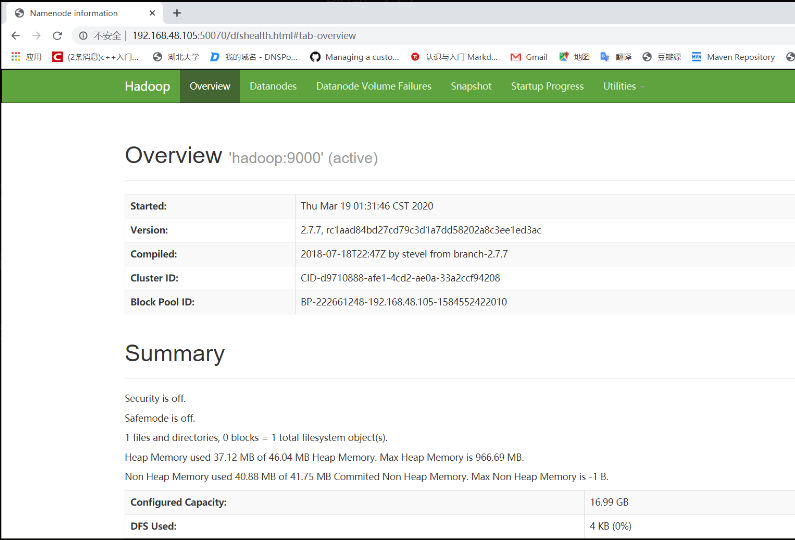
至此,整个Hadoop伪分布式搭建就完成啦!