隐私相关,图片全打码了
不知道selenium的可以看一下这个大佬写的:
https://www.cnblogs.com/yiwenrong/p/12664332.html
先看要干些什么,一共有六百道题。
抓了半天包,也没有发现需要的数据。
而且这玩意儿有反爬,不管在这个页面怎么点,url地址是固定不变的。
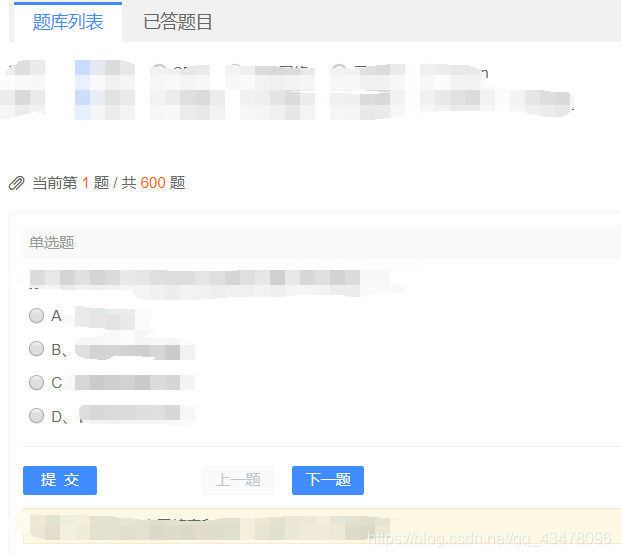
ctrl+u查看源码,虽然有题目,但是看不了答案。
 后来发现直接点击提交能看到答案
后来发现直接点击提交能看到答案
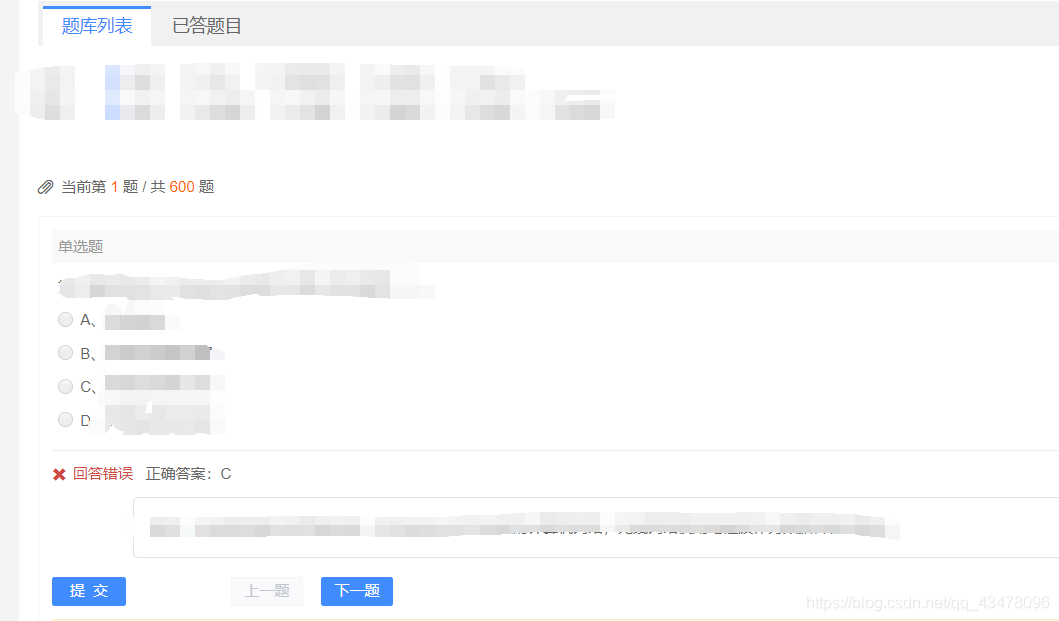
而且答案会保存到错题库,加上这个页面不能直接访问,得先登录,于是就想出了一个骚操作。
用selenium自动化测试工具(用这个前得先在下载chromedriver,火狐的叫firefoxdriver),
手动登陆后,起初是用模拟点击,后来发现看可以直接转跳网址(并且保留cookie)
driver.get('目标网址')
转跳到目标网址后,查看提交和下一题按钮的id


根据id确定点击的位置,然后用*.clike()点击。一共有600道题,循环600次。不过测试发现最后一题不知道为什么它不会去点击,只有手动点最后一题的提交了。
for i in range(0, 600):
driver.find_element_by_id('submit_question').click() # 点击提交
time.sleep(1)
driver.find_element_by_id('next_question').click() # 点击下一题
这样在已答题目里就有了一个题库
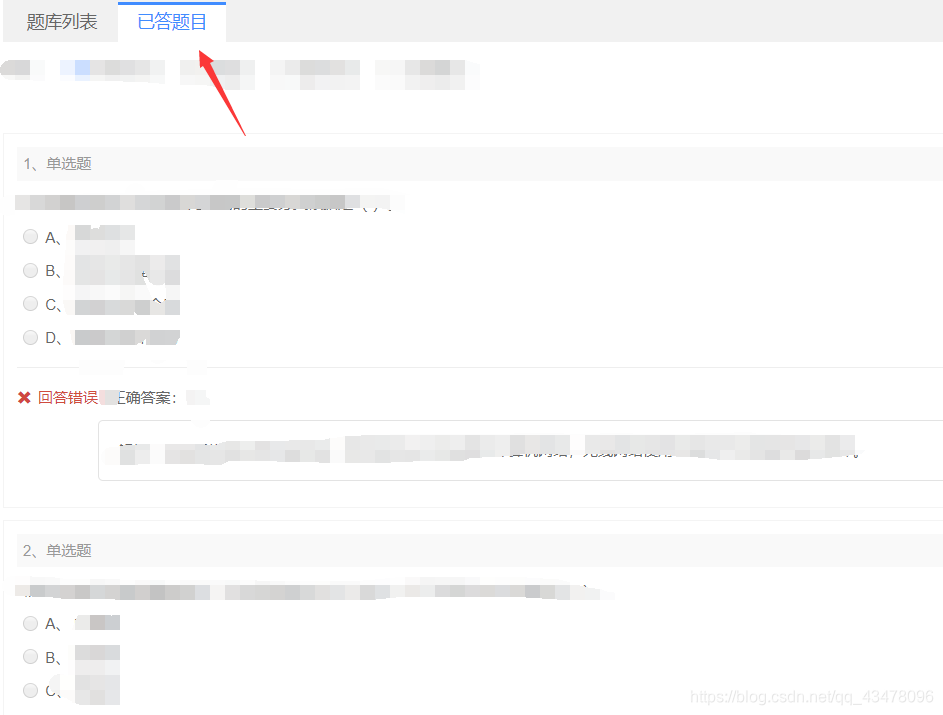 然后构造xpath语法,定位题目的文本,爬取下来。
然后构造xpath语法,定位题目的文本,爬取下来。
看到这个div标签下的div里面全是题目

divs = driver.find_elements_by_xpath('****') # 定位到所有题目的div标签
for div in divs: # 用循环遍历每道题
info = div.find_element_by_xpath('****').text # 定位到题目的文本并用text提取出来
print(info) #为了便于测试,先提取题目并答应出来,其余后续接上
然后就是这个xpath路径,搞了一上午,不知道为什么就是提取为空。我承认我xpath语法菜,但我直接复制一个节点的位置,也打印不出来。
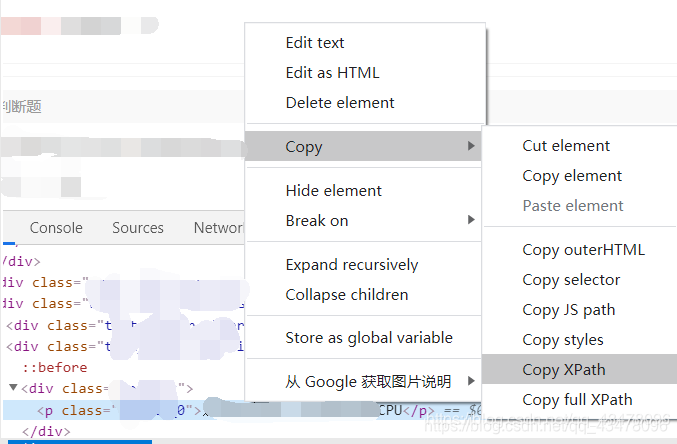
然后打开源代码,我气抖冷,看到这源码我气得浑身发抖,大热天的全身冷汗手脚冰凉,这个社会还能不能好了,我们程序员到底要怎么活着你们才满意,眼泪不争气的流了下来,这个国到处充斥着对爬虫爱好者的压迫,我们何时才能真正的站起来。
刚才答题题目的源码里面至少还有题目的信息,这个直接整了个动态页面。啥也没有,呵呵徐晃我一枪。
后来我想这样也行,我还懒得写xpath,直接用selenium全选复制下来,保存到本地。不过百度半天也没发现怎么实现。
不过在这个过程中我发现个吊的,然后我想了一个骚操作,我tm直接截屏,自动翻页,然后文字识别。这大概就是我爬虫老师说的:“可见既可爬”吧。

由于python3没有pil库,不能长截图,我也懒得去让它兼容了,直接缩小页面并且每页截屏三次保证全题目都有,重复无所谓。
driver.execute_script("document.body.style.zoom='0.3'") #缩小页面
page = 0 # 为了给图片命名
for i in range(0, 65): # 600 道题目,一共60页
# 第一张图片
#上下移动页面
driver.execute_script('window.scrollBy(0,-2000)') # 为了保证每次翻页后页面在最上面
time.sleep(0.5) # 停留0.5秒,避免还没加载就截图
driver.execute_script('window.scrollBy(0,90)') # 由于不能长截图所以要根据页面调整
time.sleep(0.5)
# 第二张图片
driver.save_screenshot("img//pic//screen{}.png".format(str(page)))
page += 1
driver.execute_script('window.scrollBy(0,650)')
time.sleep(0.5)
# 第三张图片
driver.save_screenshot("img//pic//screen{}.png".format(str(page)))
page += 1
driver.execute_script('window.scrollBy(0,650)')
time.sleep(0.5)
driver.save_screenshot("img//pic//screen{}.png".format(str(page)))
page += 1 # 13558554890
driver.execute_script('window.scrollBy(0,2000)')
click_locxy(driver, 810, 655) # 左键点击
然后是点击下一页按钮,这个也没有class属性,id啥的,我也懒得百度了,直接按照x,y轴点击

在上面的截屏里调用了点击函数,如果鼠标移动不封装为函数的话,每次移动都会叠加。如果没有查看x,y轴坐标的插件,可以用右键看位置,然后慢慢调(我就是这样的,哈哈)
# 点击函数
def click_locxy(dr, x, y, left_click=True):
'''
dr:浏览器
x:页面x坐标
y:页面y坐标
left_click:True为鼠标左键点击,否则为右键点击
'''
if left_click:
ActionChains(dr).move_by_offset(x, y).click().perform()
else:
ActionChains(dr).move_by_offset(x, y).context_click().perform()
ActionChains(dr).move_by_offset(-x, -y).perform() # 将鼠标位置恢复到移动前
测试过程又nm出问题了,页码出现两位数时,按钮会右移一点,导致一直在当前页面循环,这样又得调x,y参数了。

这样截了180张图片
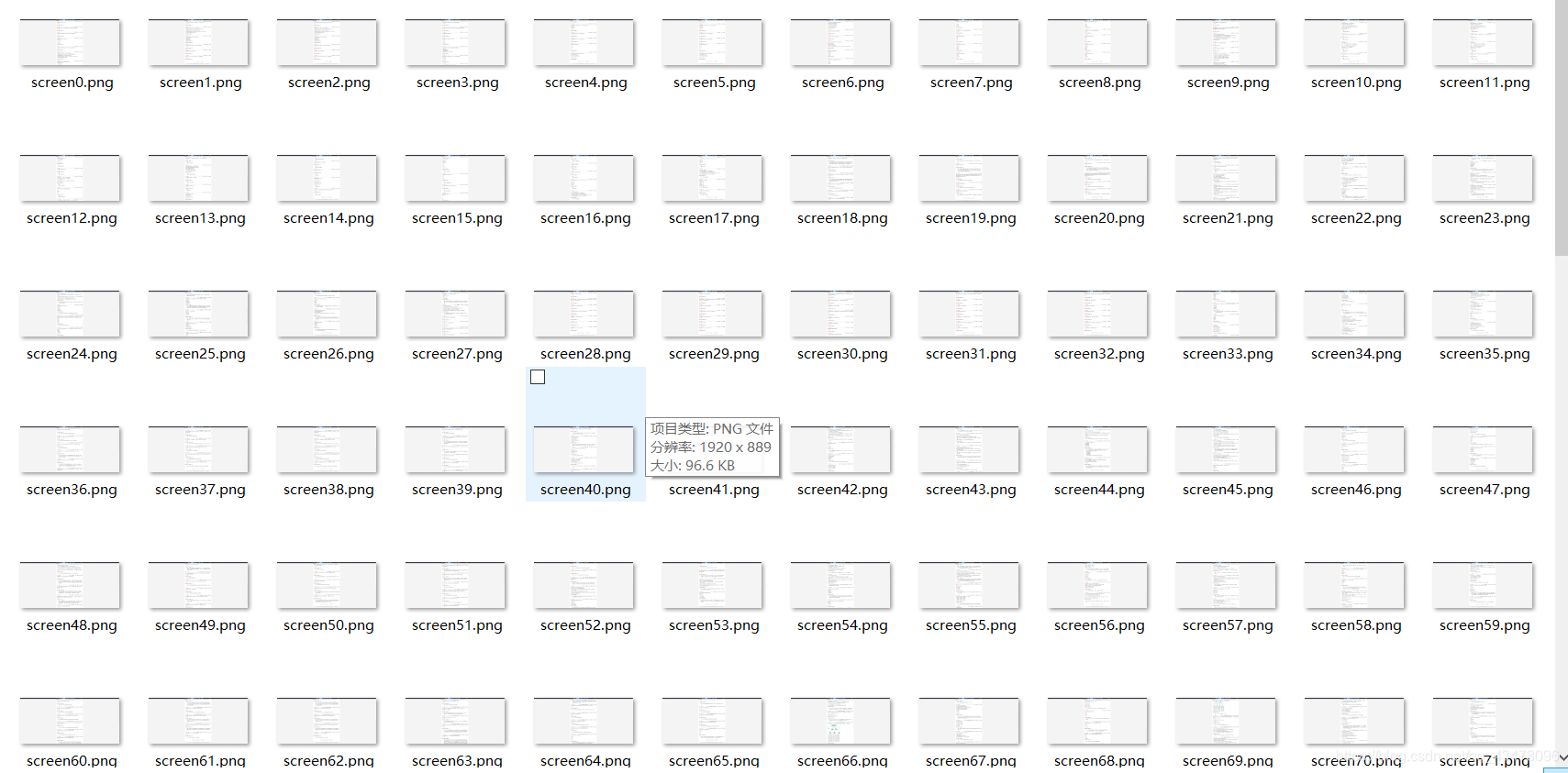
然后找了好久的免费图片识别软件,都没有,最后发现还是百度api来的快。
from aip import AipOcr
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
for i in range(0, 180):
image = get_file_content('pic22/screen{}.png'.format(i))
print(i)
""" 调用通用文字识别, 图片参数为本地图片 """
client.basicGeneral(image);
""" 如果有可选参数 """
options = {
}
options["language_type"] = "CHN_ENG"
options["detect_direction"] = "true"
options["detect_language"] = "true"
options["probability"] = "true"
""" 带参数调用通用文字识别, 图片参数为本地图片 """
a = client.basicGeneral(image, options)
if 'words_result' in a:
str = ' '.join([w['words'] for w in a['words_result']])
with open('pic3/{}.txt'.format(i), 'a', encoding='utf-8') as f:
f.write(str)
本来想的是整一个180个字符串拼接后再保存,结果遇到巨多的编码问题(一会utf-8,一会有时ansi),然后保存了180个txt文件。
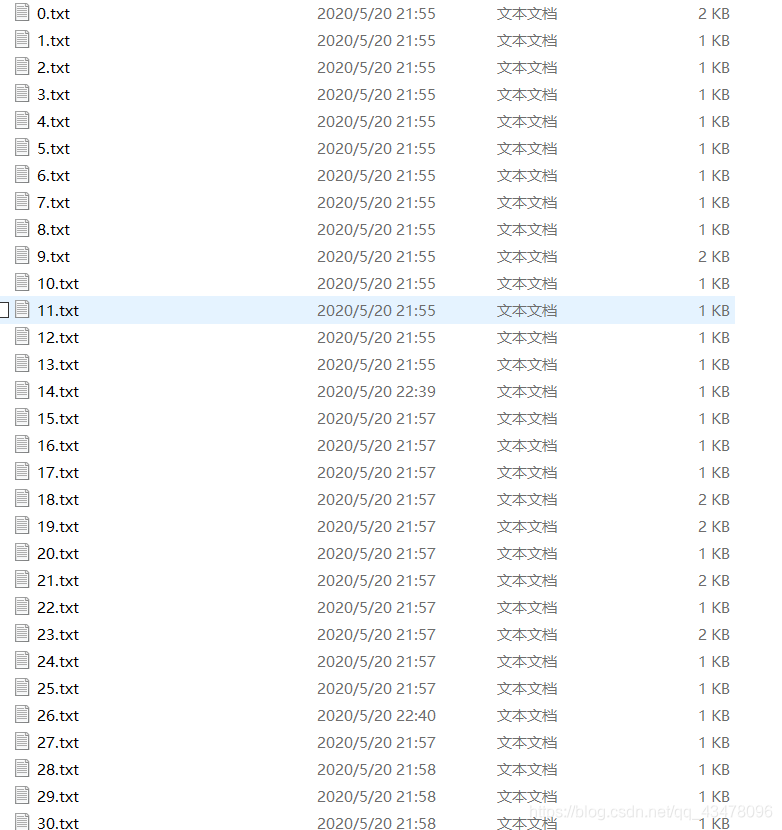
然后写脚本拼接180个txt,编码问题我真的服了,前40个要用utf-8编码,后面要gbk编码。
str = ''
for page in range(49, 181):
path = 'img/pic3/{}.txt'.format(page)
with open(path, 'r', encoding='utf-8') as f:
data = f.read()
# str = str + data
with open("img/result1.txt", 'a', encoding='utf-8') as a:
a.write(data)
a.write('\n')
print(path)
最后搞到了个这样玩意儿,翻译的时候没有加格式,而且有的题目还没有识别出来…
算了,又不是不能用

就这些搞了一整天,现在我在想如果我不截图,直接人工复制,是不是还得快点,而且还有格式。
更新:
第二天我来看代码,然后试了一下xpath语法,发现搞出来了,woc。因为第一天没有去掉前面的循环,所以没出来。
 说到底还是技术不行啊,然后我准备直接用for循环xpath路径(老师见到会打我)
说到底还是技术不行啊,然后我准备直接用for循环xpath路径(老师见到会打我)
 成功的将题目搞了出来,后来突发奇想,反正是自己用的,能不能直接复制整个题目标签的文本。
成功的将题目搞了出来,后来突发奇想,反正是自己用的,能不能直接复制整个题目标签的文本。
直接每页复制这个总的标签的xpath语法,结果成功了。
 然后开始爬数据,不过有一个毛病就是每页的前4或5题没有爬到,搞了半天都崩溃了,然后网上有大佬提示不要用.text获取文本,要用.get_attribute(‘textContent’),试了一下,果然行。
然后开始爬数据,不过有一个毛病就是每页的前4或5题没有爬到,搞了半天都崩溃了,然后网上有大佬提示不要用.text获取文本,要用.get_attribute(‘textContent’),试了一下,果然行。
然后我就把所有的题目爬下来了,我真的服了我之前的截图识别文字。

selenium代码
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
import csv
from selenium.webdriver.common.keys import Keys
# 点击函数 左键
def click_locxy(dr, x, y, left_click=True):
'''
dr:浏览器
x:页面x坐标
y:页面y坐标
left_click:True为鼠标左键点击,否则为右键点击
'''
if left_click:
ActionChains(dr).move_by_offset(x, y).click().perform()
else:
ActionChains(dr).move_by_offset(x, y).context_click().perform()
ActionChains(dr).move_by_offset(-x, -y).perform() # 将鼠标位置恢复到移动前
# 点击函数 右键
def click_locx(dr, x, y, left_click=False):
'''
dr:浏览器
x:页面x坐标
y:页面y坐标
left_click:True为鼠标左键点击,否则为右键点击
'''
if left_click:
ActionChains(dr).move_by_offset(x, y).click().perform()
else:
ActionChains(dr).move_by_offset(x, y).context_click().perform()
ActionChains(dr).move_by_offset(-x, -y).perform() # 将鼠标位置恢复到移动前
# 搜索
def search_product():
time.sleep(7) # 休息15秒 可以在这段时间登录账号
driver.get('url')
# 点击错题
# for i in range(0, 610):
# driver.find_element_by_id('submit_question').click() # 点击提交
# time.sleep(1)
# driver.find_element_by_id('next_question').click() # 点击下一题
driver.find_element_by_id('').click() # 点击错题库
driver.maximize_window()
driver.execute_script("document.body.style.zoom='0.3'") #缩小页面
# 将当前网页窗口保存为screen01.png文件,保存在当前目录
page = 0 # 为了给图片命名
for i in range(0, 600): # 600 道题目,一共60页
# 第一张图片
#上下移动页面
driver.execute_script('window.scrollBy(0,-2000)') # 为了保证每次翻页后页面在最上面
time.sleep(0.5) # 停留0.5秒,避免还没加载就截图
driver.execute_script('window.scrollBy(0,90)') # 由于不能长截图所以要根据页面调整
time.sleep(0.5)
# 第二张图片
driver.save_screenshot("img//pic//screen{}.png".format(str(page)))
page += 1
driver.execute_script('window.scrollBy(0,650)')
time.sleep(0.5)
# 第三张图片
driver.save_screenshot("img//pic//screen{}.png".format(str(page)))
page += 1
driver.execute_script('window.scrollBy(0,650)')
time.sleep(0.5)
driver.save_screenshot("img//pic//screen{}.png".format(str(page)))
page += 1 # 13558554890
driver.execute_script('window.scrollBy(0,2000)')
click_locxy(driver, 810, 655) # 左键点击
# click_locx(driver, 810, 655) # 右键键点击
# ActionChains(driver).move_by_offset(800, 650).click().perform() # 鼠标左键点击, 200为x坐标, 100为y坐标
# ActionChains(driver).move_by_offset(800, 650).context_click().perform() # 鼠标右键点击
# driver.find_element_by_xpath('//*[@id="paginator"]/ul/li[5]/a').click() # 下一页
# 解析数据
def get_product():
divs = driver.find_elements_by_xpath('')
for div in divs:
# info = div.find_element_by_xpath('').text # .text 题目
# price = div.find_element_by_xpath('').text # .text 选项
deal = div.find_element_by_xpath('').text # .text 答案
# print(info, price, deal, sep="|") # sep 分隔符为竖线
print(deal)
# with open("img//timu.csv", 'a', newline='') as filecsv:
# csvwriter = csv.writer(filecsv, delimiter=',')
# csvwriter.writerow([info, price, deal]) # 一行一行写入
def main():
search_product()
# get_product()
if __name__ == '__main__':
#keyword = input("please input the keyword:")
# 实例化一个对象(浏览器)
driver = webdriver.Chrome()
driver.get('')
main()
总结
- 爬取前先确认是否为动态页面
- 编码问题
- xpath
- .text方法换为.get_arrtibute(‘textContent’)