1. 内存爆炸问题
1.1 loss.item或 float(loss)
首先附上主要代码
下图接上图

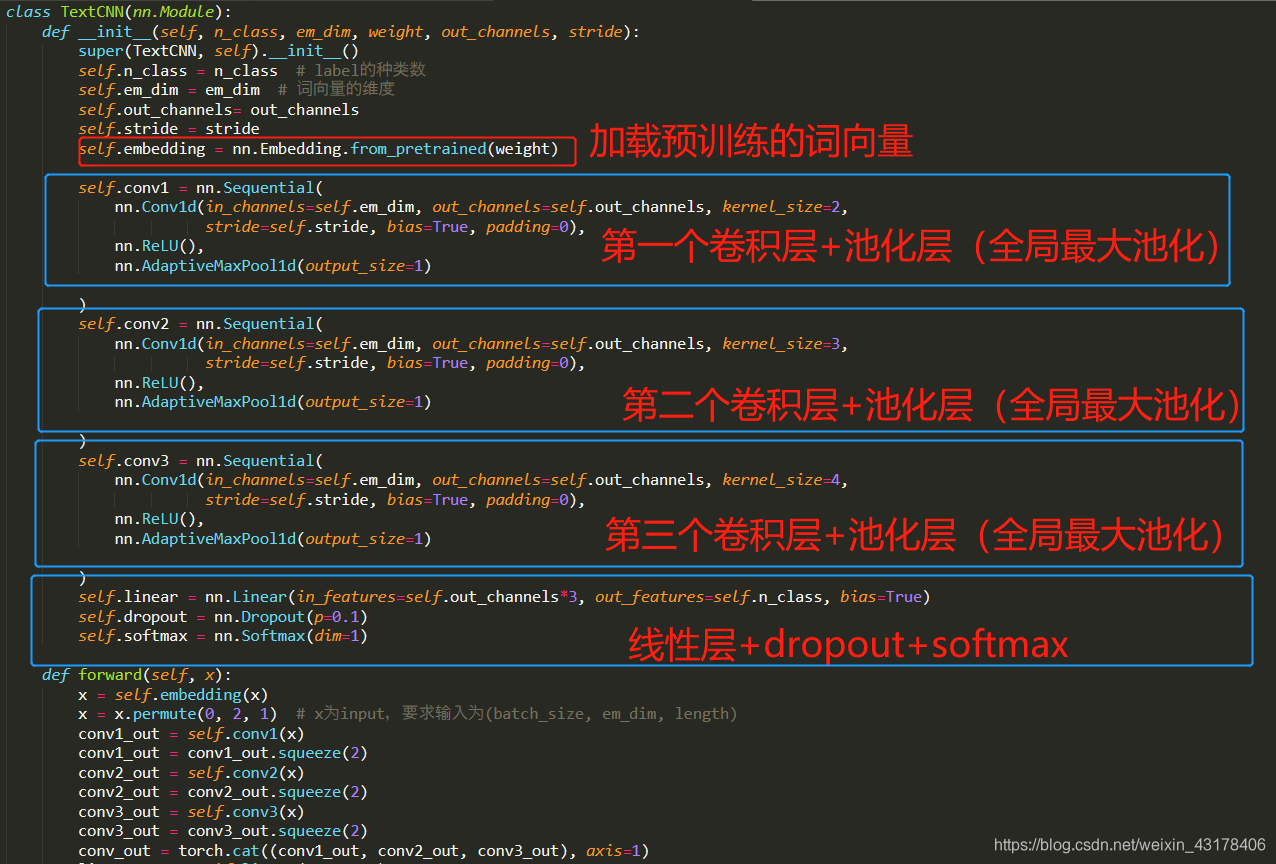
上面为定义的TextCNN模型,下图为主要的训练及预测测试集的过程
下图接上图

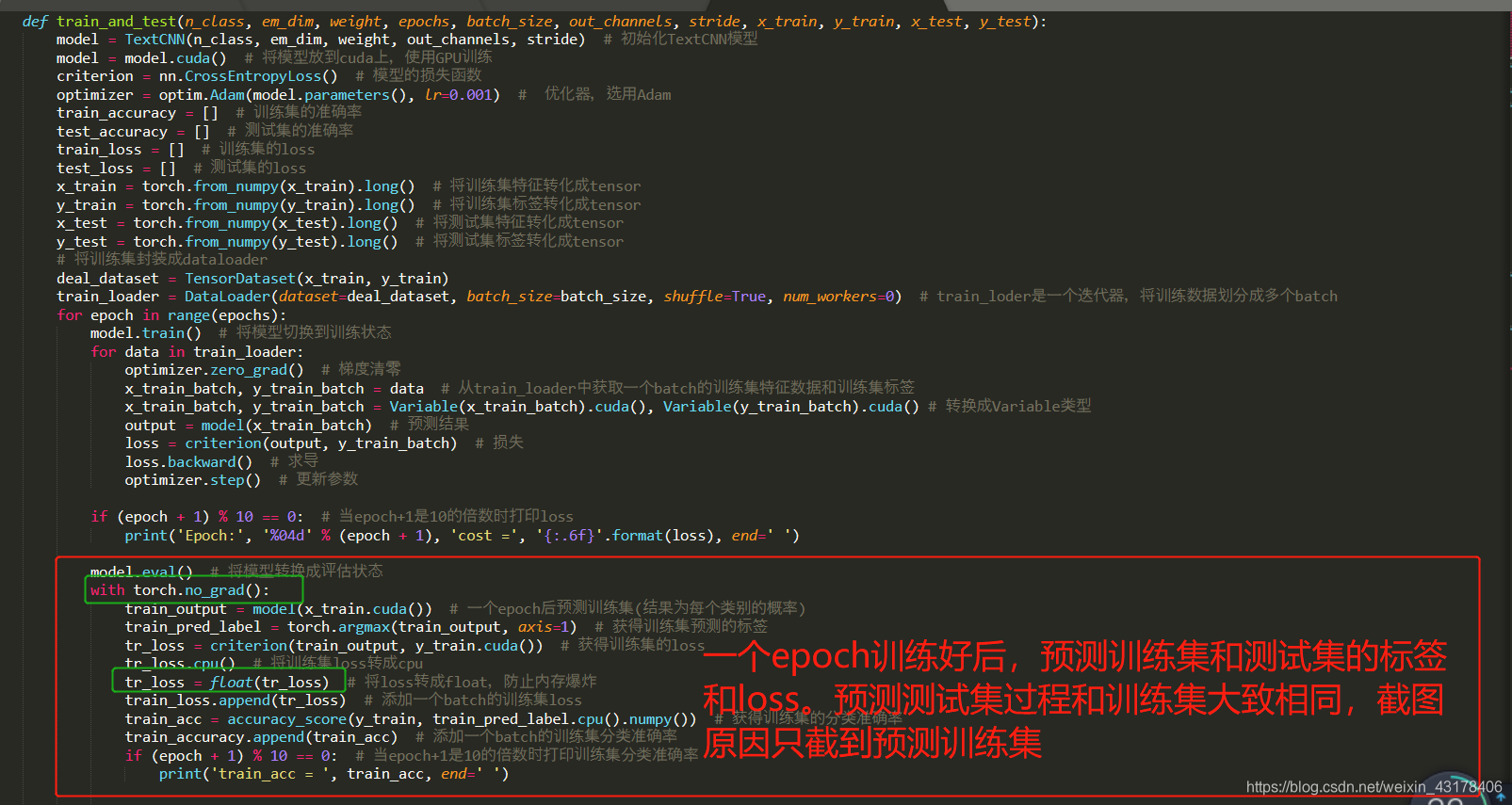
可以从第三张图片看到绿框部分有一个tr_loss = float(tr_loss)。在pytorch中涉及需要求导/梯度变量的计算将保存在内存中,如果不释放指向计算图形的指针,这些变量在循环训练中就会超出你内存。因此千万不要在循环中累积历史记录。
如果不加tr_loss = float(tr_loss),tr_loss(可求导变量,一直会保留副本在内存中)就会一直有副本,并保留在内存中,经过多个epoch后,就会撑爆内存。一般释放副本的方式为tr_loss.item()上面提到的tr_loss = float(tr_loss)也可以,但更推荐使用tr_loss.item()。如果没有释放副本(内存),就会出现以下错误:
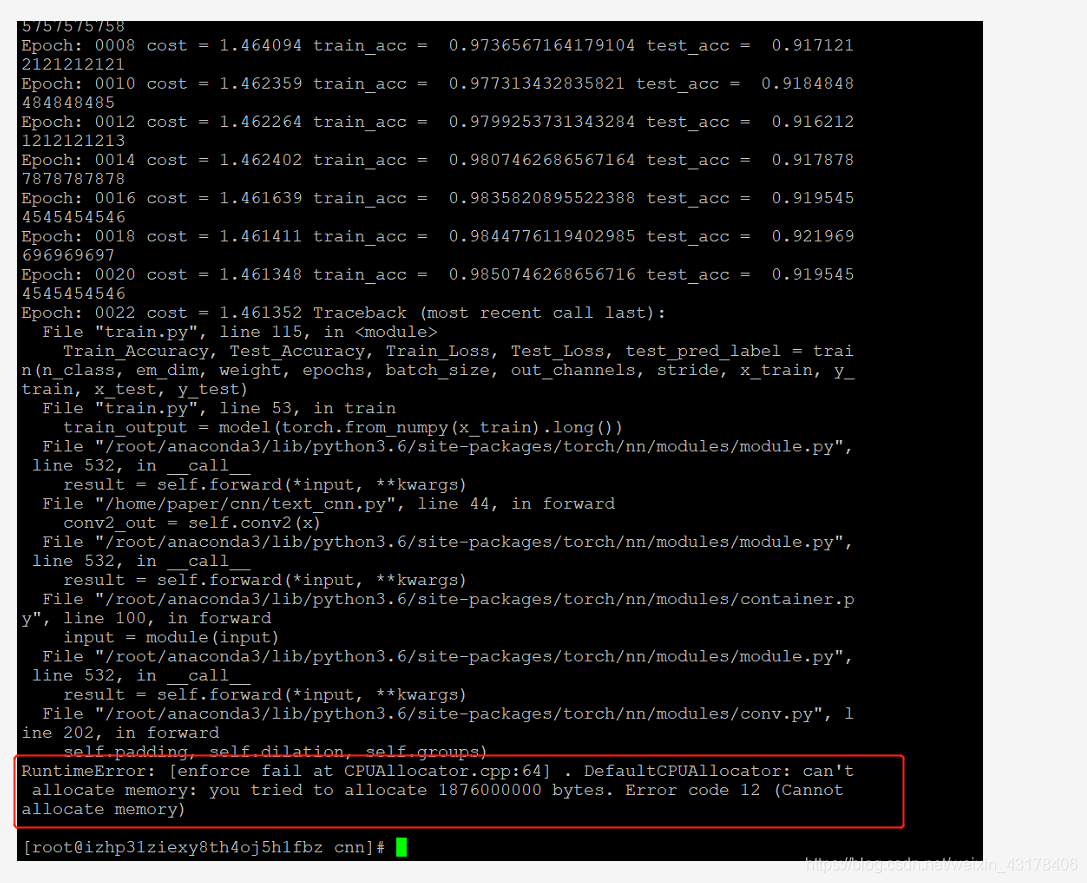
看似是内存问题,其实使我们代码写的有问题。
有时我们需要算累积的loss,也是一样的方式,如下所示:
total_loss = 0
for i in range(10000):
optimizer.zero_grad()
output = model(input)
loss = criterion(output)
loss.backward()
optimizer.step()
total_loss += loss.item()
仔细想一想,pytorch训练的时候有一个optimizer.zero_grad()似乎也是释放计算图,因此不会撑爆内存
1.2 with torch.no_grad()
第三张图片还有一个绿框部分即with torch.no_grad()这个作用也是防止内存爆炸。
模型训练阶段,会存储一些用于反向传播的内部信息。当需要由训练阶段(反向传播)转至预测阶段时,需要使用model.eval()和with torch.no_grad()。model.eval()是告诉计算机,我现在不需要训练了(反向传播),我要开始测试了,这时,计算机就会固定住dropout和batch normalization(不会取平均,而是用训练好的值),简单理解就是不需要更新参数了,而是用训练好的参数进行预测。由于不需要更新参数,故不会产生用于反向传播的内部信息,更不会存储到内存了。with torch.no_grad()是为了释放训练过程中产生的用于反向传播的内部信息,从而释放内存。不管是对训练集进行预测,还是对测试集进行预测,都需要使用with torch.no_grad()
2. 如何观察内存变化
第一章提到内存爆炸,那么如何观察内存的变化呢
2.1 cpu
当使用cpu训练模型时,可在命令行输入top然后按大写的M即可看到占用内存最大的程序。
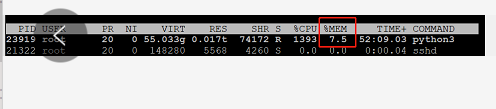
图片中红框部分就是cpu占用率,说明我们现在使用了7.5%的内存
2.2 GPU
当我们使用cuda时,使用命令watch -n 0.1 nvidia-smi观察内存变化
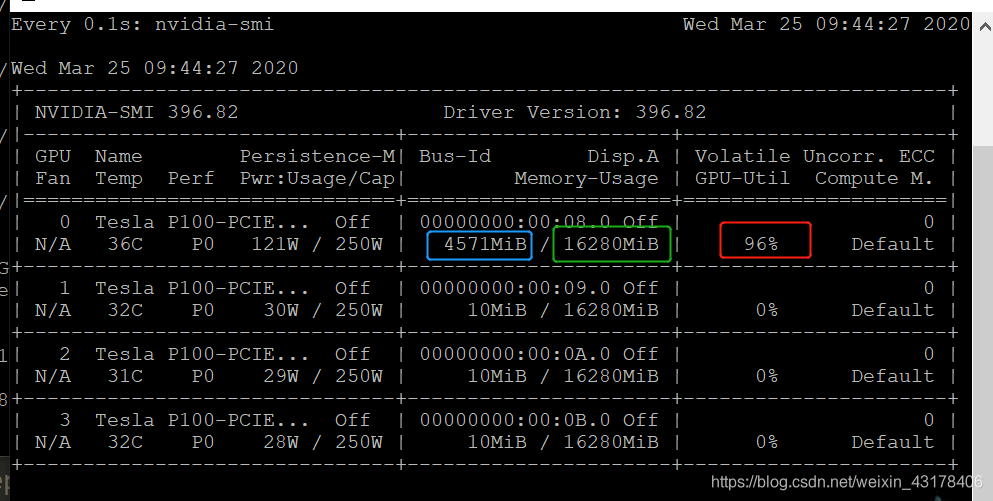
上图显示我们共有4块GPU,一块大约16G(图中绿框),目前,我们仅使用了其中一块GPU,利用率为96%(红框部分,该数表示程序96%的部分都在GPU上跑,剩余4%在cpu跑),目前共占用GPU的显存为4G左右(蓝框部分)
3. 多块GPU(数据并行),lstm参数展平
当我们有多块GPU,并且全部使用时,训练lstm,需要进行参数展平的操作,否则会有一堆提示信息(这不算报错吧,warning)

由于多次循环,满屏基本都是上图中的warning了。
那么怎样进行参数展平,只需要在lstm cell前加lstm.flatten_parameters(),如下图所示
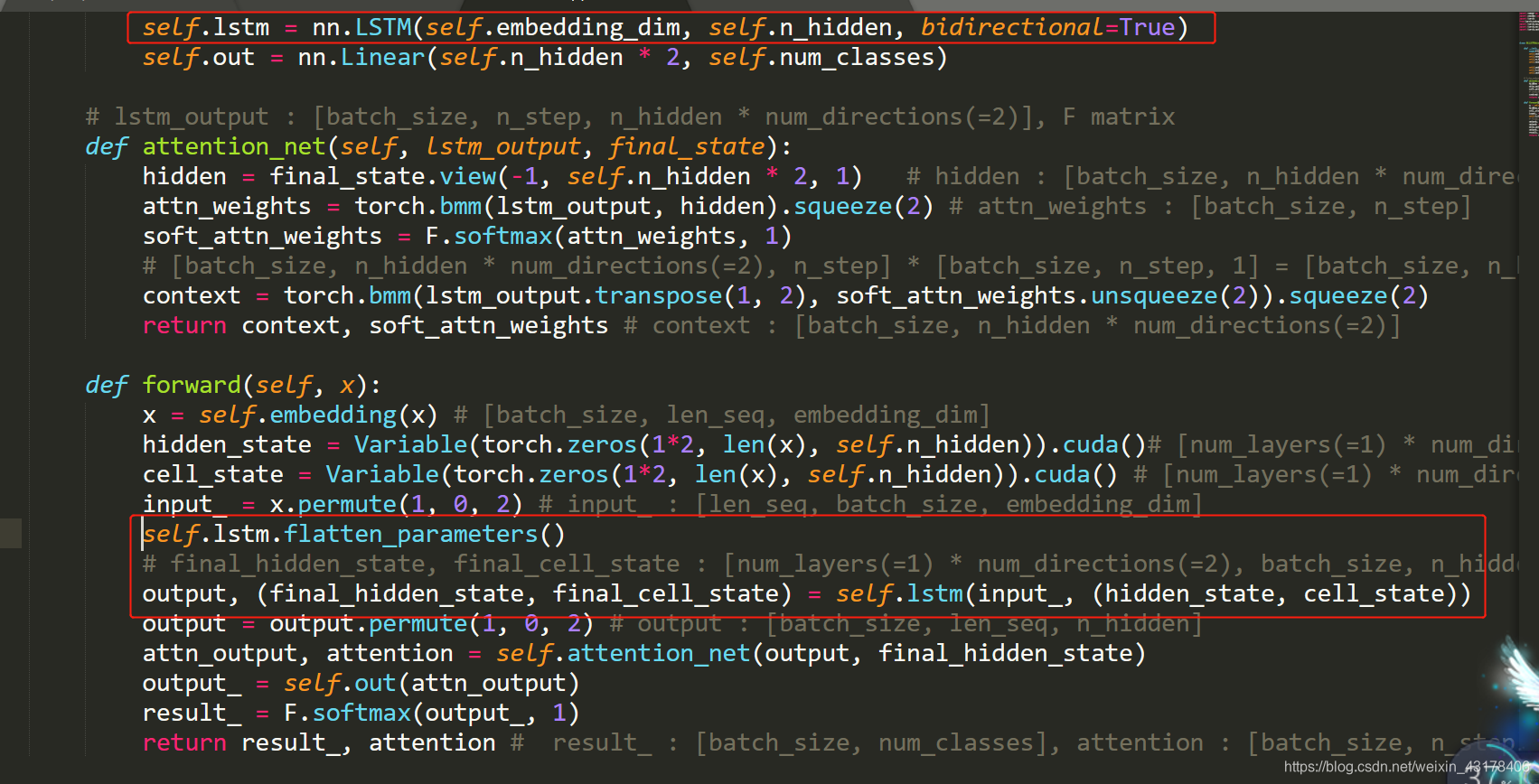
这个问题好像有时候出现,有时候不出现。。。且仅使用多块GPU时出现(如果只使用一块GPU,还没有出现过)
4. 多块GPU与DataLoder
pytroch中有DataLoader,可以将数据划分成多个batch,DataLodaer有一个参数num_workers,这是pytroch加快速度的一种方法,其允许批量并行加载。所以,你可以一次加载许多批量,而不是一次加载一个。但是当既使用DataLoder又使用多块GPU时,就可能出现segmentation faultmentation fault的问题,看了很多博客,大概是DataLoder是多线程,与多块GPU发生了冲突,故有人建议将num_worker设成1,然而我不管设成1还是0还是会出现segmentation fault的问题。有一篇大神的博客https://meteorix.github.io/2019/04/30/pytorch-coredump/从c++的角度去debug问题,其最终使用了线程加锁,解决了问题,不过,我尝试在DataLoder加锁,还是没有解决问题(可能是加锁位置不对)。最终采用了最极端的方式,放弃DataLoder,换用其他方式,最终不再报错。
由于上述问题是多线程与多GPU冲突的问题,故仅仅使用一块GPU应该不会报错,即使使用多块GPU,上述问题也不一定出现,因为这个问题是随机性的。。。我在测试中,有一次程序的确跑通了。
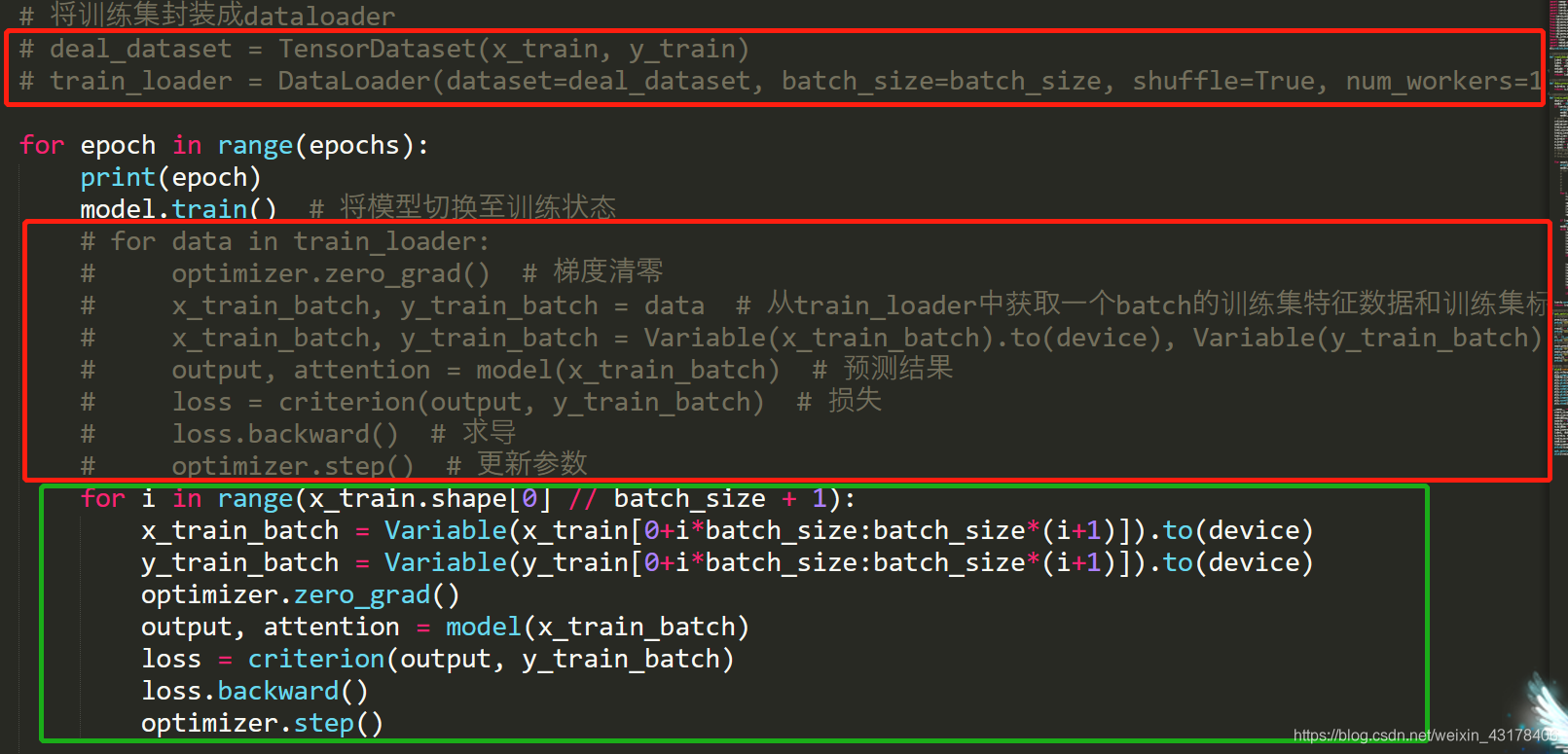
弃用了红框的DataLoder,换用绿框的方式
5. pytroch训练及预测部分怎么写
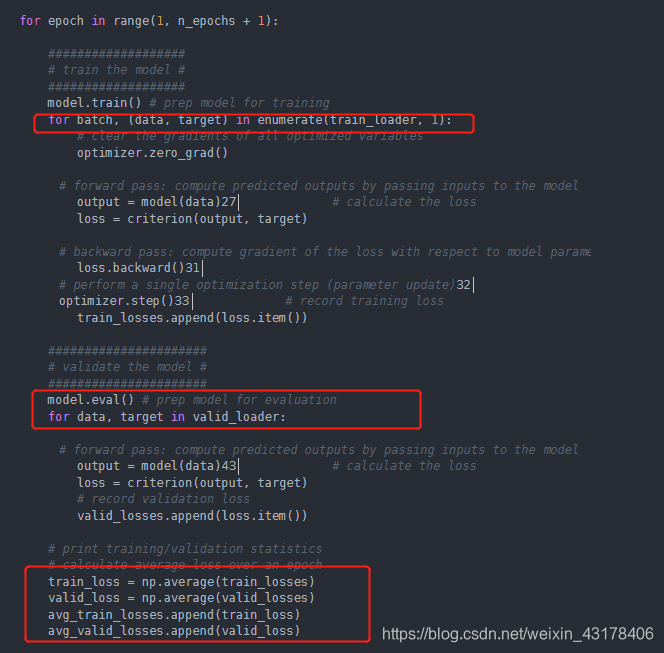
回顾第一章的TextCNN,我的代码是在一个epoch训练结束后,再对整个训练集和测试集进行预测,获得loss和acc并存储在列表中。此外,还有另外一种写法。训练集和测试集都分成很多batch,一个epoch中的每个batch都记录下loss和acc,当一个epoch结束后,求一个epoch下n个batch的平均值(loss和acc)作为一个epoch的loss和acc。
参考链接:https://blog.csdn.net/weixin_40446557/article/details/103387629