导语
今天给大家分享下数据测试工程师的发张方向。
目录
- 整体职能介绍
- 基于业务型的测试
- 基于ETL层的测试
- 基于AI层的测试
- 技能栈介绍
1 整体职能介绍
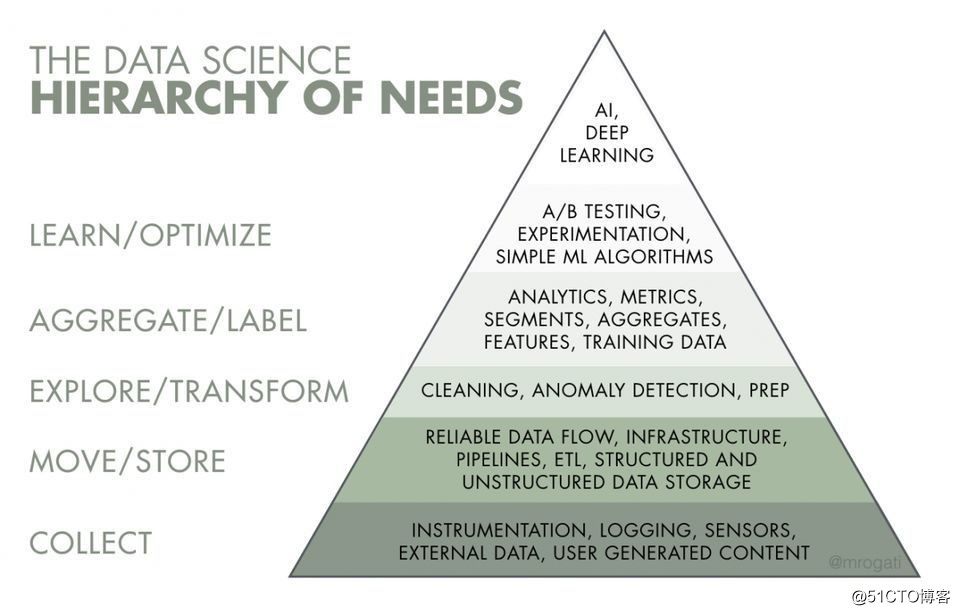
众所周知数据处理工作是围绕着: 数据收集、数据清洗、数据建模、数据应用开展了,像上图金字塔一样分为:大数据开发/运维工程师、数据挖掘工程师以及数据分析师,其中

同样的数据测试工程师的工作也是围绕着数据收集、清洗、建模、应用进行的,对应的可以分为以下几类:业务型的数据测试、ETL层的数据测试、AI层的测试,下面我们来瞅瞅到底他们的职能到底有何不同。

2 基于业务型的测试
基于业务型的数据测试是确保数据准确性、一致性、安全性,
业务型的数据测试强调:确保最终输出数据符合业务的自定义规则,
举个栗子:业务方需要一个指标A,看某个商家最高的净毛利率的门店是哪家,其中:净毛利=毛利/营业收入

作为业务型的测试人员需考虑:
1、评估指标A的构成成分,从业务层面上评估指标A由哪些子指标组成,子指标由哪些指标构成,直到拆解到子指标不能拆解为止,这里 净毛利由毛利÷营业收入得到,毛利又由主营业务收入减去主营业务成本得到。
2、评估每个构成成分获取路径,每个子指标在系统是否能直接获取,在哪个子系统获取,如果不能直接获取,需要怎样进行加工才能获取。
3、评估是否需统一数据入口,在问题2中可能一个子指标会有多个数据入口,例:主营业务的数据可能在系统S1与S2系统都获取,需要评估取S1还是S2更加准确。
4、评估每个子指标是否存在无效数据,例:主营业务中是否有包含 试运营门店的数据 或 测试门店产生的数据。
5、统一指标定义与称呼,等以上几点都评估后,还需要评估该指标定义与称呼,是否符合业务方使用习惯。
真实业务数据测试过程中还不止这几点,这里想表达的是业务型测试人员更多关注的是业务的定义,从数据的定义、获取、产出都需要遵循业务定义,很多时候业务方没有明确的定义,这时候需要不断的跟业务方具体化这些指标,让业务方来明确指标的定义。
3 基于ETL层的测试

ETL全称是Extract-Transform-Load,提取、清洗、加载,这里测试人员需要确保研发人员这三个阶段数据不失真:
提取需考虑:
1、 考虑获取数据源有哪些,例: mysql,mongdb,es,csv,erp系统,当前的抽取工具或者系统是否能全部兼容?
2、 考虑抽取方式如何,数据量大的系统应该是增量抽取的,研发是否有考虑,抽取是实时进行还是离线进行的,哪个更适用于现在的业务形态?
清洗/加载 需考虑:
清洗的目的是为了过滤掉不符合要求的数据,测试则是独立于研发,需要基于etl清洗规则对结果数据进行check:
1、评估不完整的数据处理,这一类数据主要是一些应该有的信息缺失:如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全,补全后才写入数据仓库。
2、评估错误的数据处理:这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。
3、评估重复的数据处理:对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来。
4、评估不一致数据处理:这个过程是一个整合的过程,将不同业务系统的相同类型的数据统一,比如同一个供应商在结算系统的编码是XX0001,而在CRM中编码是YY0001,这样在抽取过来之后统一转换成一个编码。
4 基于AI层的测试
AI全称是Artificial Intelligence,人工智能层面的质量保证,这个层面则需取评估一些算法模型是否智能,
评估一些算法模型是否智能,
可能没有一个明确的点证明它智能或者不够智能,只能从业务目的、数据集是否合格、制定ABtest方案最终再看效果上面来评判:
好比女朋友生气了原因可能有多种,直接问肯定问不出结果,但正确做法:
1、尝试分析惹她生气的原因是,可能有多种原因,可能是你提到前女友了,可能是生日忘记了,可能是你嫌弃她做饭不好吃...,对各类原因的权重进行评估,你提到前女友比重肯定占98%...
2、那么分析生气的原因,肯定要做些补救的办法,比如:生日忘记了就补救买礼物,提到前女友就下次注意点,嫌弃饭菜做不好就你自己做并说声:“亲爱的,我来做吧(潜台词:你做饭不好吃)”
说完不正经的,我们继续聊聊正经的AI测试:
例:如何鉴定一套智能推荐算法是否智能,AI测试人员评估过程如下:
1、了解业务目的是什么,参与评估影响因子以及权重。
例:当前商品无货时推荐用户另一种相似的商品,提高用户购物体验,另一方面拉动整体销售的GMV————这些是算法模型解决的核心问题,影响因子评估包括:
商品A与商品B在同一个订单内出现的次数、
商品A与商品B所属商品类目的层级结构、
同一类标签的用户购买商品A后也购买了商品B、
...
最后以上的影响因子的所占权重进行评估。
2、了解并评估算法模型,并评估训练数据集的数据是否“合格”。
目前大多数互联网公司的算法模型都是业界的一些通用且成熟的算法模型,AI算法工程师通过对一些模型的一些参数进行配置实现与自家公司业务贴合,所以AI测试工程师在算法模型层面参与度不多,
重点还是关注训练数据集是否“合格”以及参与制定AB test方案对算法效果评估进行评估,
评估数据是否合格:包含etl过程————对数据完整性、一致性、重复性的处理,除此之前外还应该评估数据的降噪是否合理,
例: 某商品历史日均销量都是几万,突然某天到了几百万,需要评估这天是否由大型促销或者是否上游计算错误导致,算法这层需要有对这些数据的监控以及处理。
3、参与AB test方案制定,制定AB test方案不光光是产品、运营、研发的任务,
测试人员作为对系统最熟悉的人员,
应该全程参与AB test:
3.1、评估且制定影响算法的核心因子以及其之间的权重
3.2、评估且制定最终AB test方案的效果指标
3.3、同一时间内将线上同一类型的少量用户分为A组与B组,每次test 改变模型内指标因子
3.4、然后通过效果指标去评估本次 AB test的好坏,从而确定最优的核心因子以及其之间的权重

例:
智能推荐算法影响因子可能是:商品A与商品B在同一个订单出现次数、商品A与商品B所属商品类目的层级结构...
权重占比可能是:各占25%、4:3:2:1...
效果指标可能是:分流到A组的用户的总GMV高于分流到B组的用户总GMV、分流到A组的用户的客单价高于分流到B组的用户客单价...
通过模型分为AB组,然后将同一类型用户引流到不同组内,最终通过效果指标评估模型好坏,从而确定最优的模型。
5 技能栈介绍
就更学习武功一样往往厉害的是一些内功心法,招式都是在这基础上才有的东西,反过来说业务层、ETL层、AI层的数据测试80%的工作其实还是对业务进行深入理解(这就是内功心法),然后制定出合理、可行的数据测试方案,然后通过hadoop、hive、jupyter、pandas、spark...(才有招式)等一系列语言或者工具来执行测试方案,最终达到数据质量保证的目的。
喜欢我本次的分享同学可以扫描下方微信二维码,这里更多的大数据测试干货。
