0.概述
模型融合,是把不同模型结果进行整合,个人觉得模型融合需要和特征构造相区别,如果将模型的结果作为特征来进行学习,其实应该算一种新的特征构造,即特征工程的内容。因此,模型融合的方法应该是平均法,投票法,纠错码法,boosting和bagging。模型融合的思想,是兼听则明,多个模型结果融合,降低了单一模型严重偏离真值的概率。模型融合的结果,要么可以提升精度,要么降低方差,好的模型融合,应该可以在提升精度的同时,降低方差。
1.平均法
- 简单加权平均,结果直接融合
求多个预测结果的平均值。pre1-pren分别是n组模型预测出来的结果,将其进行加权融
pre = (pre1 + pre2 + pre3 +...+pren )/n
- 加权平均法
一般根据之前预测模型的准确率,进行加权融合,将准确性高的模型赋予更高的权重。
pre = 0.3pre1 + 0.3pre2 + 0.4pre3
2.投票
- 简单投票
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=4, min_child_weight=2, subsample=0.7,objective='binary:logistic')
vclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('xgb', clf3)])
vclf = vclf .fit(x_train,y_train)
print(vclf .predict(x_test))
- 加权投票
在VotingClassifier中加入参数 voting='soft', weights=[2, 1, 1],weights用于调节基模型的权重
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=4, min_child_weight=2, subsample=0.7,objective='binary:logistic')
vclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('xgb', clf3)], voting='soft', weights=[2, 1, 1])
vclf = vclf .fit(x_train,y_train)
print(vclf .predict(x_test))
3.boosting/bagging
集成模型集成方法(ensemble method)
集成模型可按照数据使用的规则和模型组合的规则来分为提升(boosting)和打包(bagging),提升使用全体数据,对错误率高的数据不断提升其权重,主要作用是减少偏差。而bagging使用数据抽样的方法,最后各模型进行投票,其主要特点是减少方差。
通过组合多个学习器来完成学习任务,通过集成方法,可以将多个弱学习器组合成一个强分类器,因此集成学习的泛化能力一般比单一分类器要好。
集成方法主要包括Bagging和Boosting,Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个更加强大的分类。两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果。常见的基于Baggin思想的集成模型有:随机森林、基于Boosting思想的集成模型有:Adaboost、GBDT、XgBoost、LightGBM等。
Baggin和Boosting的区别总结如下:
样本选择上: Bagging方法的训练集是从原始集中有放回的选取,所以从原始集中选出的各轮训练集之间是独立的;而Boosting方法需要每一轮的训练集不变,只是训练集中每个样本在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整
样例权重上: Bagging方法使用均匀取样,所以每个样本的权重相等;而Boosting方法根据错误率不断调整样本的权值,错误率越大则权重越大
预测函数上: Bagging方法中所有预测函数的权重相等;而Boosting方法中每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重
并行计算上: Bagging方法中各个预测函数可以并行生成;而Boosting方法各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
4.stacking & blending
- stacking
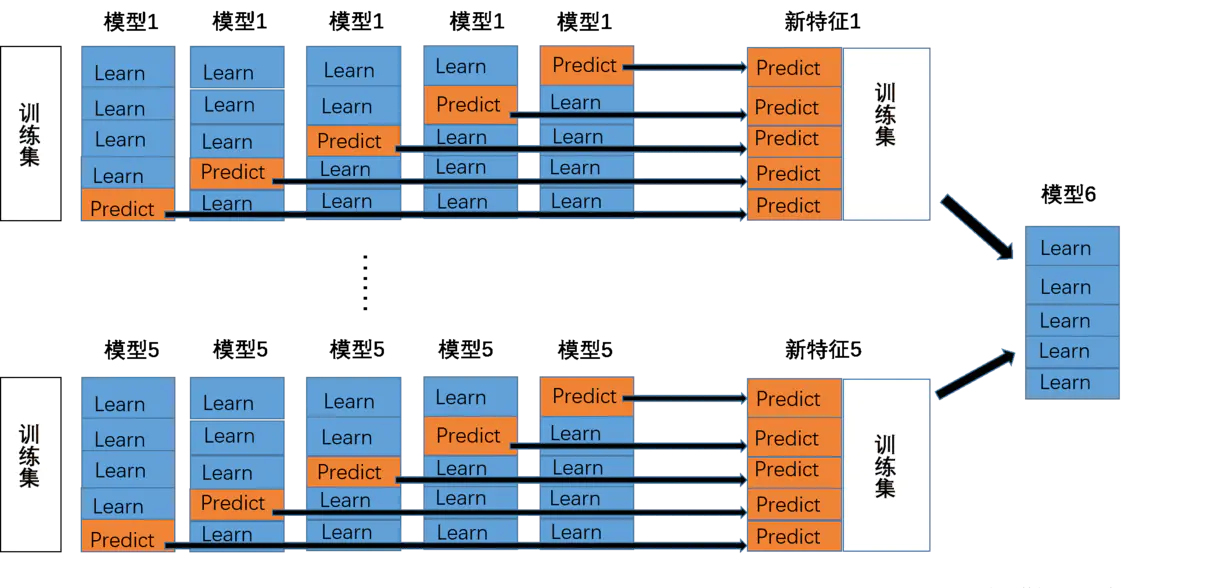
将若干基学习器获得的预测结果,将预测结果作为新的训练集来训练一个学习器。如下图 假设有五个基学习器,将数据带入五基学习器中得到预测结果,再带入模型六中进行训练预测。但是由于直接由五个基学习器获得结果直接带入模型六中,容易导致过拟合。所以在使用五个及模型进行预测的时候,可以考虑使用K折验证,防止过拟合。
- blending
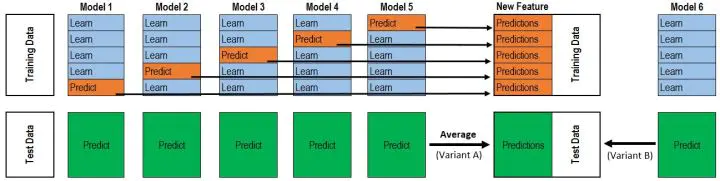
与stacking不同,blending是将预测的值作为新的特征和原特征合并,构成新的特征值,用于预测。为了防止过拟合,将数据分为两部分d1、d2,使用d1的数据作为训练集,d2数据作为测试集。预测得到的数据作为新特征使用d2的数据作为训练集结合新特征,预测测试集结果。
-
Blending与stacking的不同
- stacking
- stacking中由于两层使用的数据不同,所以可以避免信息泄露的问题。
- 在组队竞赛的过程中,不需要给队友分享自己的随机种子。
- Blending
- 由于blending对将数据划分为两个部分,在最后预测时有部分数据信息将被忽略。
- 同时在使用第二层数据时可能会因为第二层数据较少产生过拟合现象。
- stacking
-
Stacking:
import warnings
warnings.filterwarnings('ignore')
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from mlxtend.plotting import plot_learning_curves
from mlxtend.plotting import plot_decision_regions
# 以python自带的鸢尾花数据集为例
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
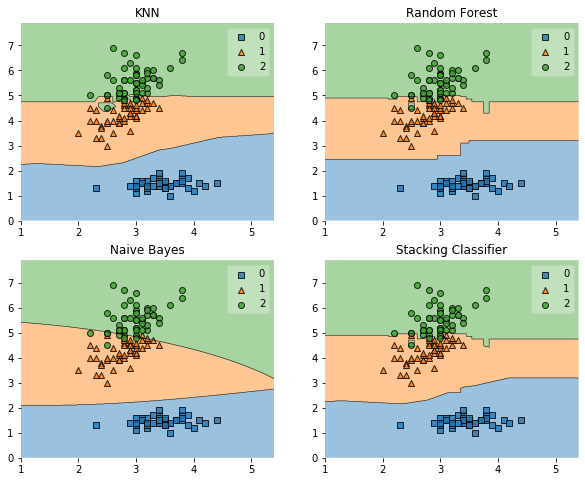
label = ['KNN', 'Random Forest', 'Naive Bayes', 'Stacking Classifier']
clf_list = [clf1, clf2, clf3, sclf]
fig = plt.figure(figsize=(10,8))
gs = gridspec.GridSpec(2, 2)
grid = itertools.product([0,1],repeat=2)
clf_cv_mean = []
clf_cv_std = []
for clf, label, grd in zip(clf_list, label, grid):
scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %.2f (+/- %.2f) [%s]" %(scores.mean(), scores.std(), label))
clf_cv_mean.append(scores.mean())
clf_cv_std.append(scores.std())
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(label)
plt.show()
Accuracy: 0.91 (+/- 0.07) [KNN]
Accuracy: 0.94 (+/- 0.04) [Random Forest]
Accuracy: 0.91 (+/- 0.04) [Naive Bayes]
Accuracy: 0.94 (+/- 0.04) [Stacking Classifier]
- blending
# 以python自带的鸢尾花数据集为例
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
#模型融合中基学习器
clfs = [LogisticRegression(),
RandomForestClassifier(),
ExtraTreesClassifier(),
GradientBoostingClassifier()]
#切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=914)
#切分训练数据集为d1,d2两部分
X_d1, X_d2, y_d1, y_d2 = train_test_split(X, y, test_size=0.5, random_state=914)
dataset_d1 = np.zeros((X_d2.shape[0], len(clfs)))
dataset_d2 = np.zeros((X_predict.shape[0], len(clfs)))
for j, clf in enumerate(clfs):
#依次训练各个单模型
clf.fit(X_d1, y_d1)
y_submission = clf.predict_proba(X_d2)[:, 1]
dataset_d1[:, j] = y_submission
#对于测试集,直接用这k个模型的预测值作为新的特征。
dataset_d2[:, j] = clf.predict_proba(X_predict)[:, 1]
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_d2[:, j]))
#融合使用的模型
clf = GradientBoostingClassifier()
clf.fit(dataset_d1, y_d2)
y_submission = clf.predict_proba(dataset_d2)[:, 1]
print("Val auc Score of Blending: %f" % (roc_auc_score(y_predict, y_submission)))