Hadoop的MapReduce应用
1.创建Java Project
参照博客Linux安装、配置Eclipse
我新建的工程名为:WordCountZhm
2.导入Hadoop的Jar包
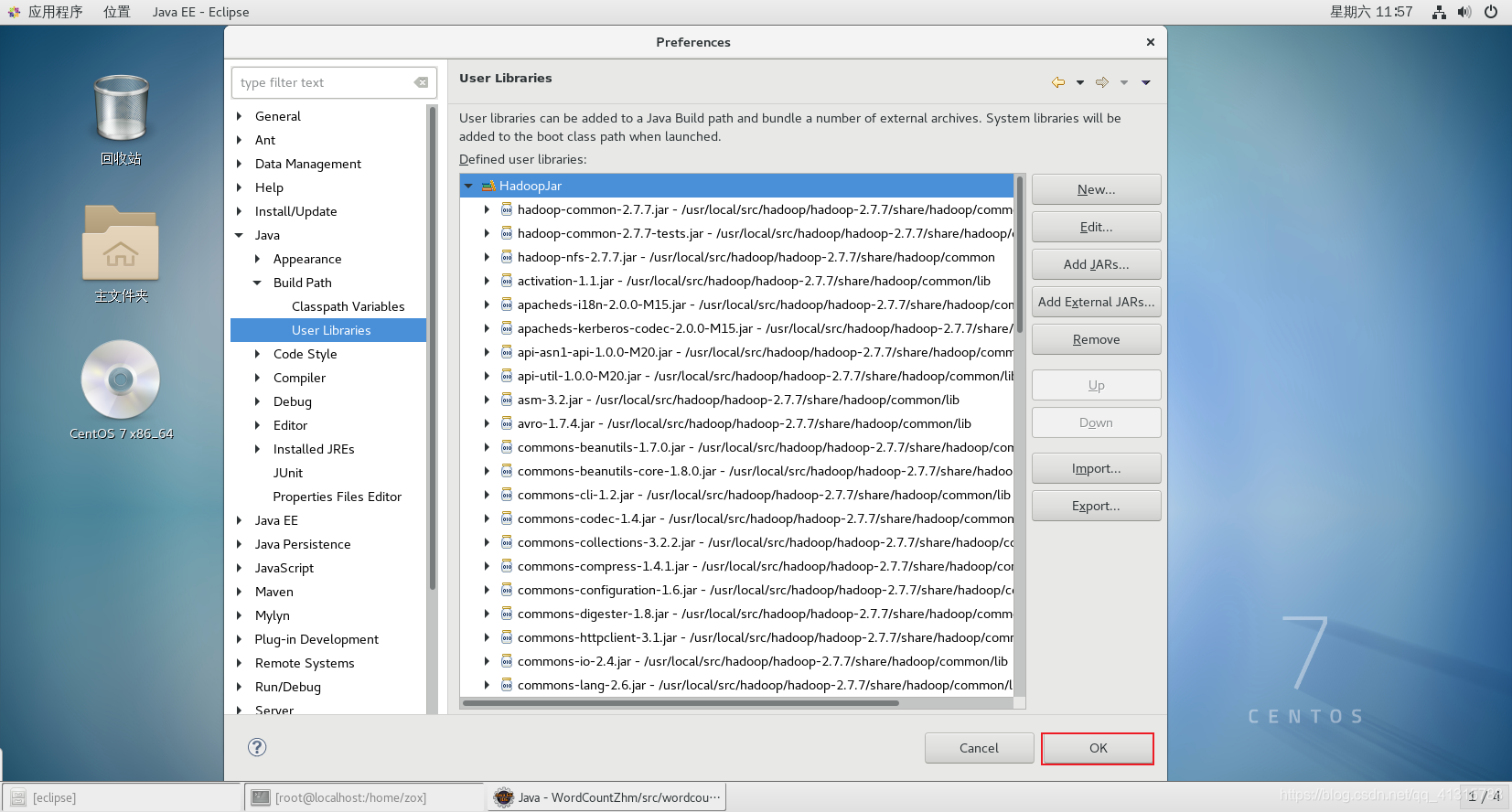
(1)新建Use Libraries
①Windows→Preferences

②Java→Build Path→Use Libraries→New

③设置名称为:HadoopJar

④添加Jar包:Add External JARs
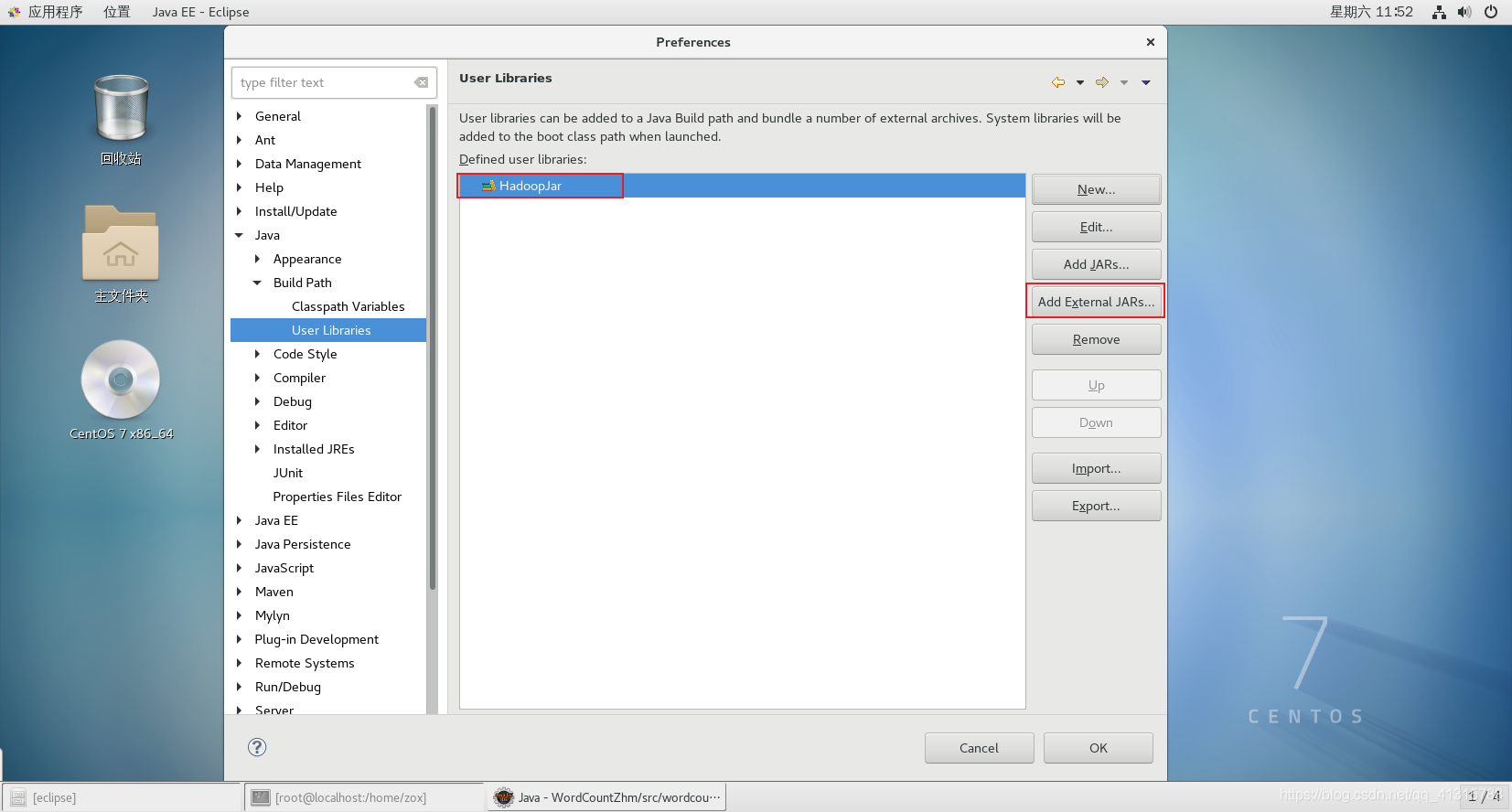
(2)目录/share/hadoop/common下的jar包

(3)目录/share/hadoop/common/lib下的jar包

(4)目录/share/hadoop/hdfs下的jar包
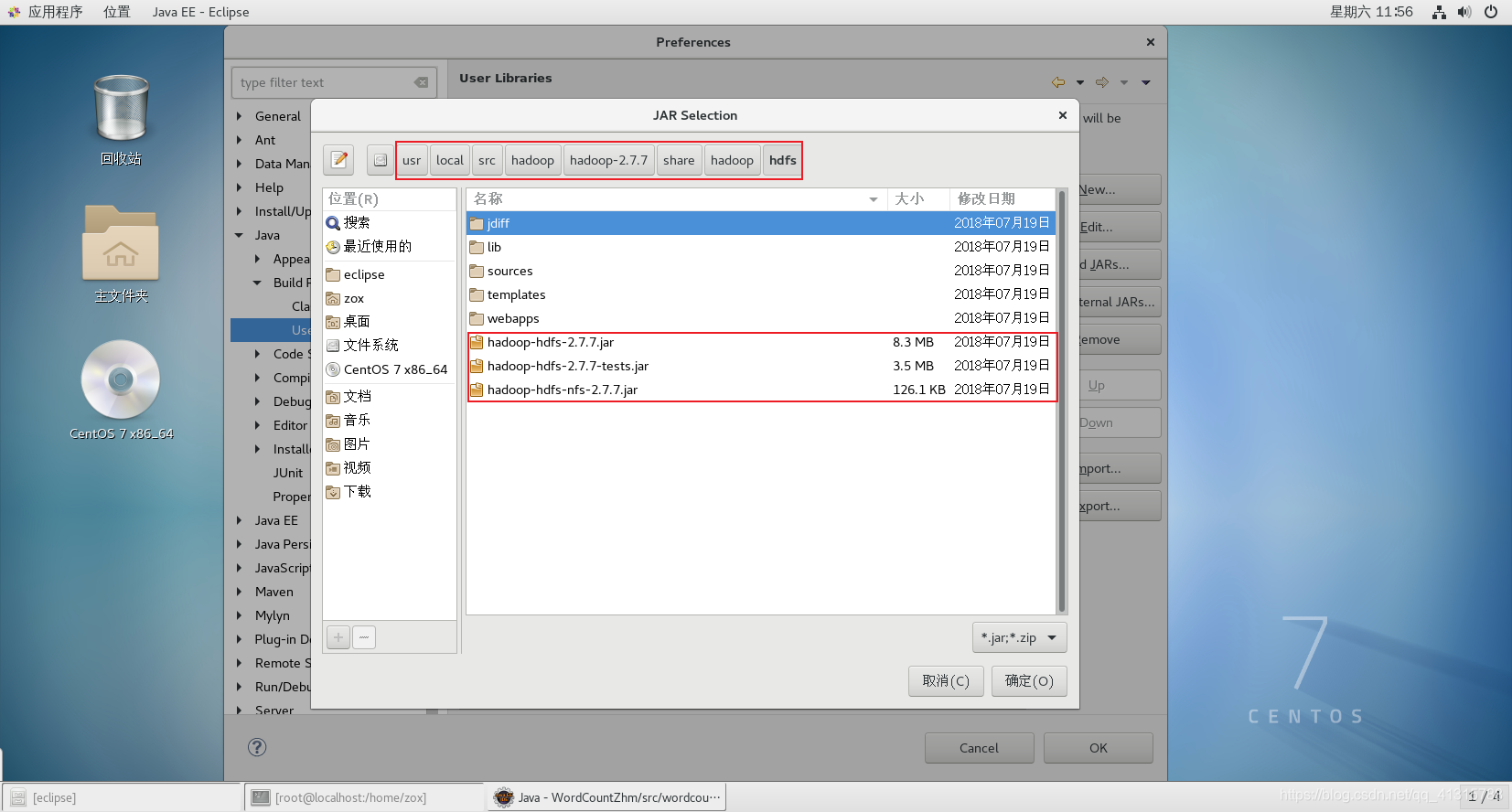
(5)目录/share/hadoop/mapreduce下的jar包
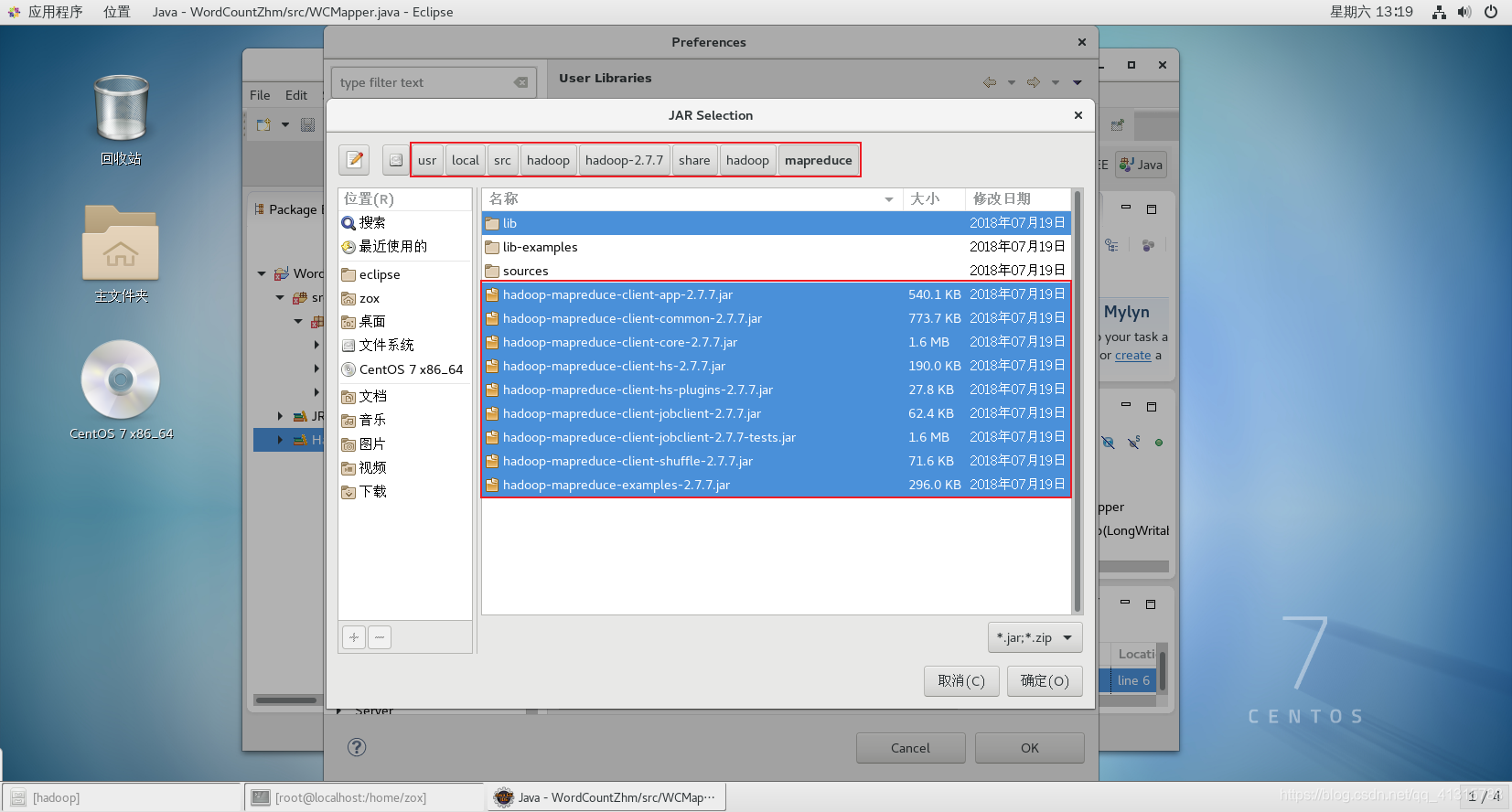
(6)为Java工程配置Jar包路径
①鼠标移到项目上右键→Build Path→Configure Build Path
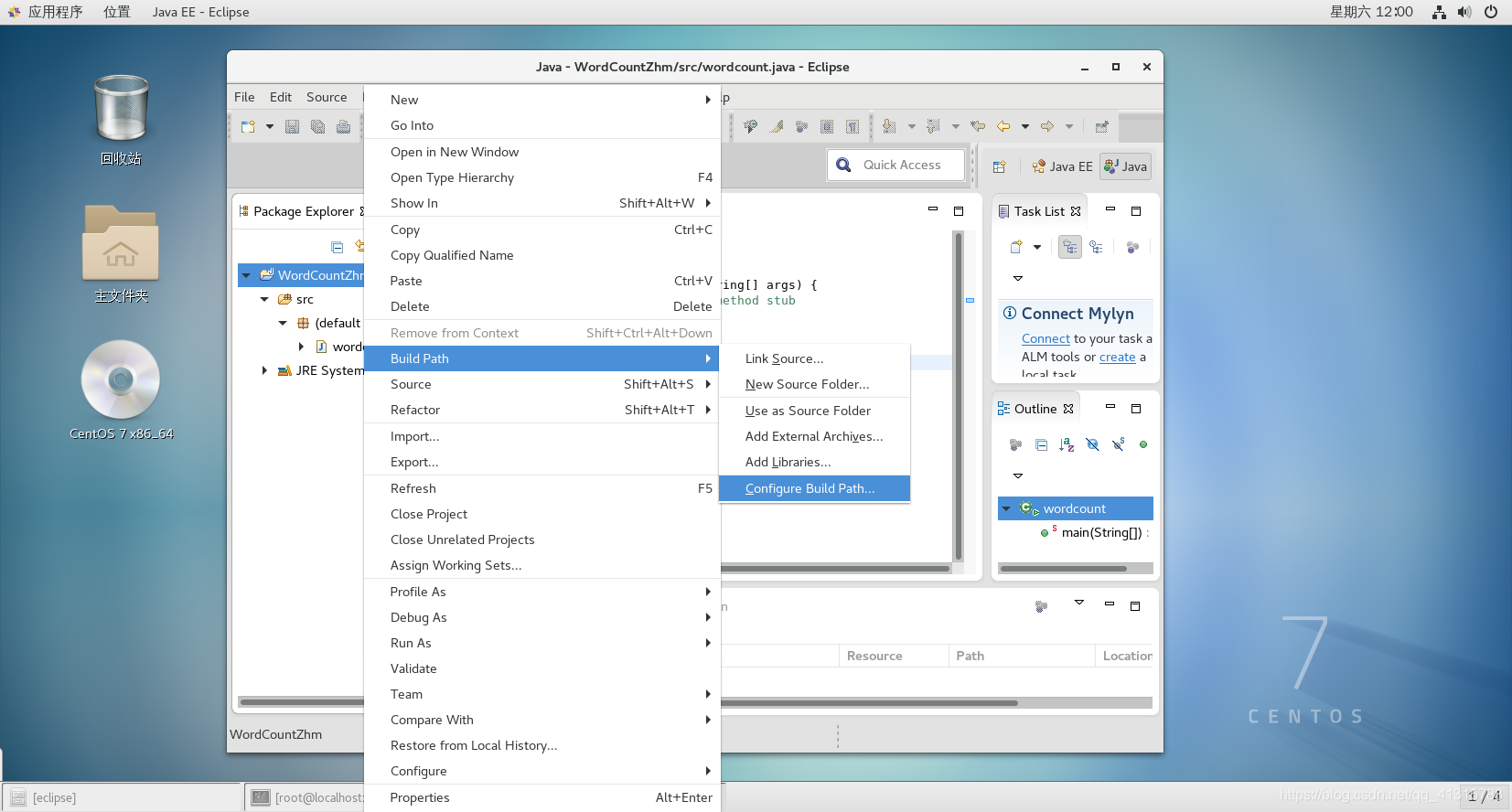
②Libraries→Add Library
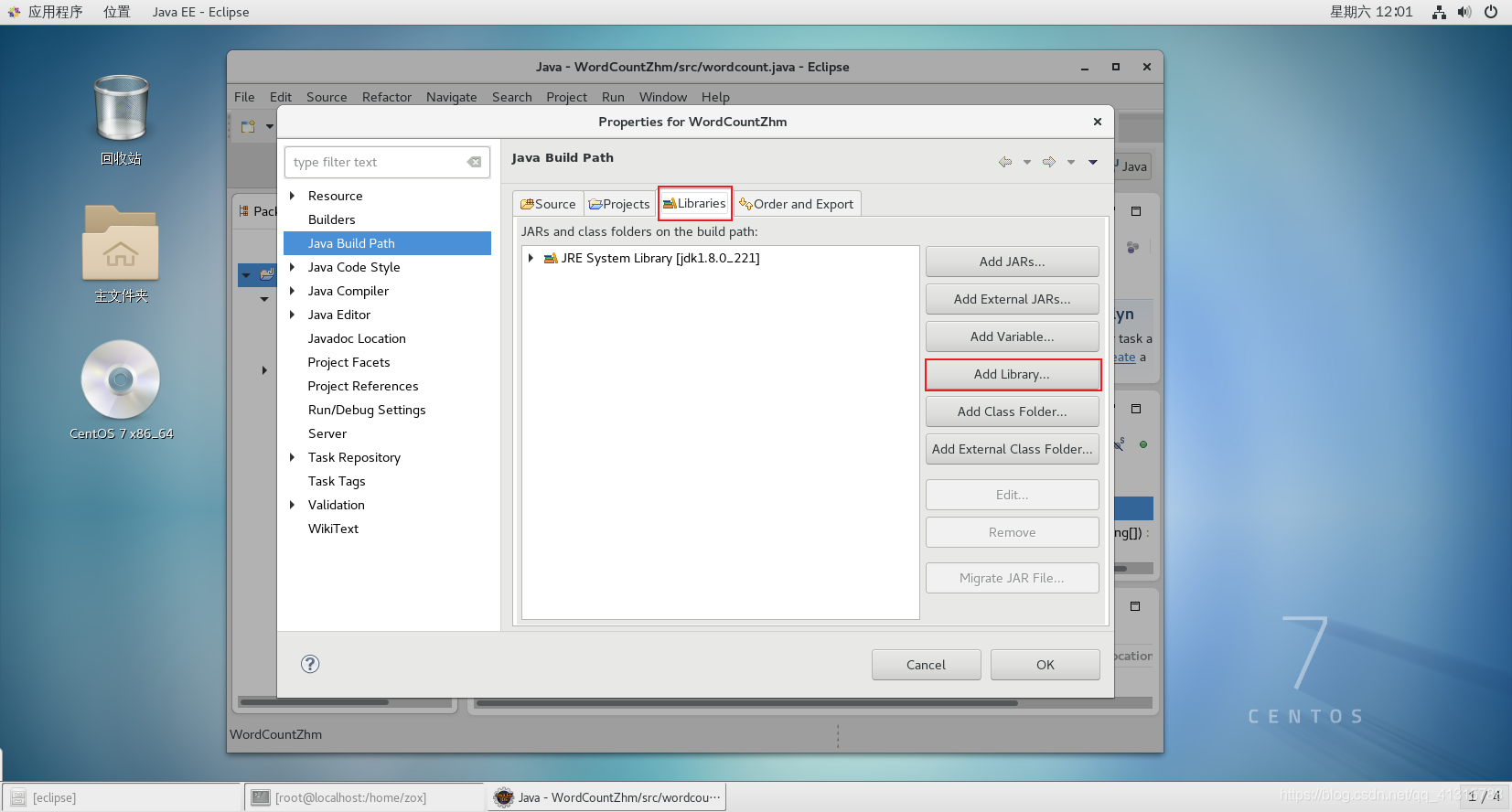
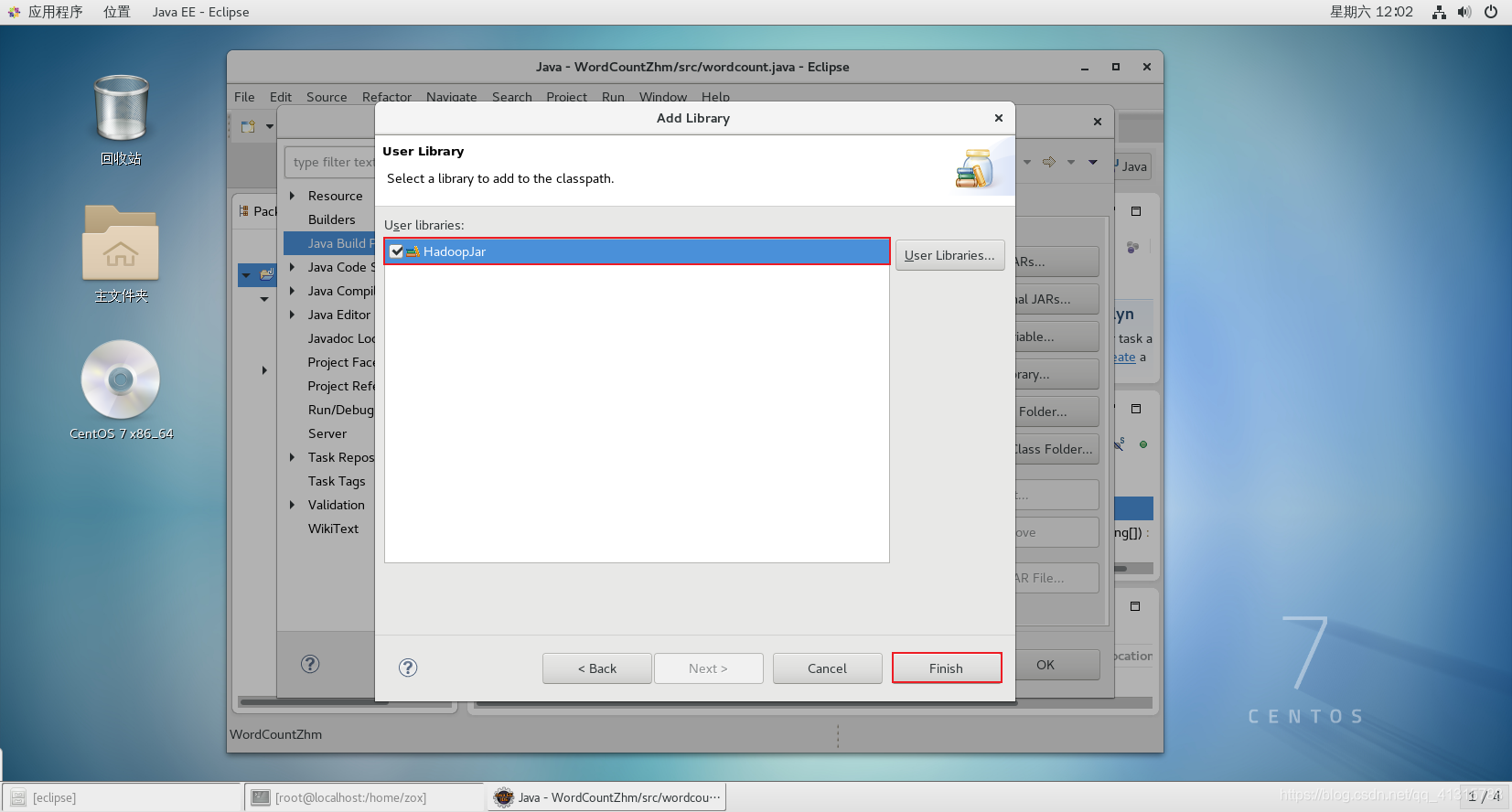
③选择Use Librariy

④选择HadoopJar
3.编写WordCount的代码
(1)创建3个Java类文件


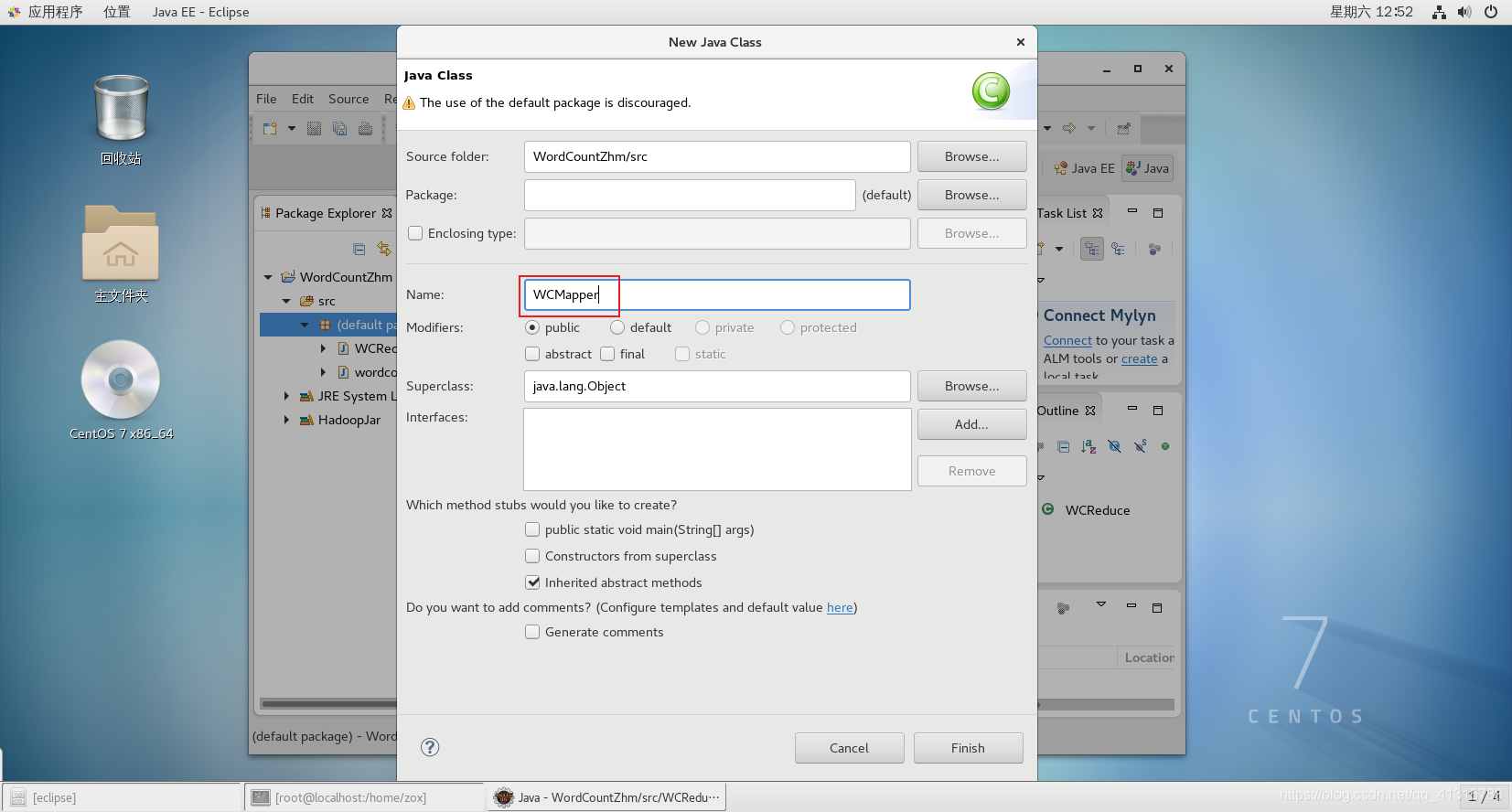

(2)WCMapper.java
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
//需要重写map方法
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
//接收数据V1
String line = value.toString();
//切分数据
String[] words = line.split(" ");
//循环输出word
for(String word : words){
//由于word是String类型数据,没有序列化,因此在写出去之前先序列化。
//1是int类型,没有序列化,因此要序列化。
context.write(new Text(word), new LongWritable(1));
}
}
}
(3)WCReduce.java
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WCReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> v2s,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//定义一个counter用来统计某个单词出现的次数是多少
long counter=0;
//其实v2s当中存储的都是一个个被序列化好了的1
for(LongWritable i : v2s){
counter+=i.get();//跟我们熟悉的counter++是一个意思
}
//输出<K3、V3>,比如<"hello", 5>
context.write(key, new LongWritable(counter));
}
}
(4)wordcount.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class wordcount {
public static void main(String[] args) throws Exception {
long startTime = System.currentTimeMillis(); //获取开始时间
// TODO Auto-generated method stub
//我们已经自定义好了Mapper和Reduce而现在我们要做的就是把MapReduce作业提交上去
//现在我们把MapReduce作业抽象成Job对象了
Job job = Job.getInstance(new Configuration());
//注意:一定要将main方法所在的类设置进来。
job.setJarByClass(wordcount.class);
//接下来我们设置一下Job的Mapper相关属性
job.setMapperClass(WCMapper.class);//设置Mapper类
job.setMapOutputKeyClass(Text.class);//设置K2的类型
job.setMapOutputValueClass(LongWritable.class);//设置V2的类型
//接下来我们得告诉程序我们应该去哪里读取文件。需要注意的是Path是指在Hadoop的HDFS系统上的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));//这里我们采用变量的形式传进来地址
//接下来我们来设置一下Job的Reducer相关属性
job.setReducerClass(WCReduce.class);//设置Reducer类
job.setOutputKeyClass(Text.class);//设置K3的类型
job.setOutputValueClass(LongWritable.class);//设置V3的类型
//接下来我们得告诉程序应该把结果信息写到什么位置。注意:这里的Path依然是指文件在Hadoop的HDFS系统
//上的路径。
FileOutputFormat.setOutputPath(job, new Path(args[1]));//我们依然采用变量的形式传进来输出地址。
job.waitForCompletion(true);//把作业提交并且等待执行完成,参数为true的话,会打印进度和详情。
long endTime = System.currentTimeMillis();//获取结束时间
System.out.println("程序运行时间:" + (endTime - startTime) + "ms"); //输出程序运行时间
}
}
4.打包WordCount为Jar包
①鼠标移到项目上右键→Export
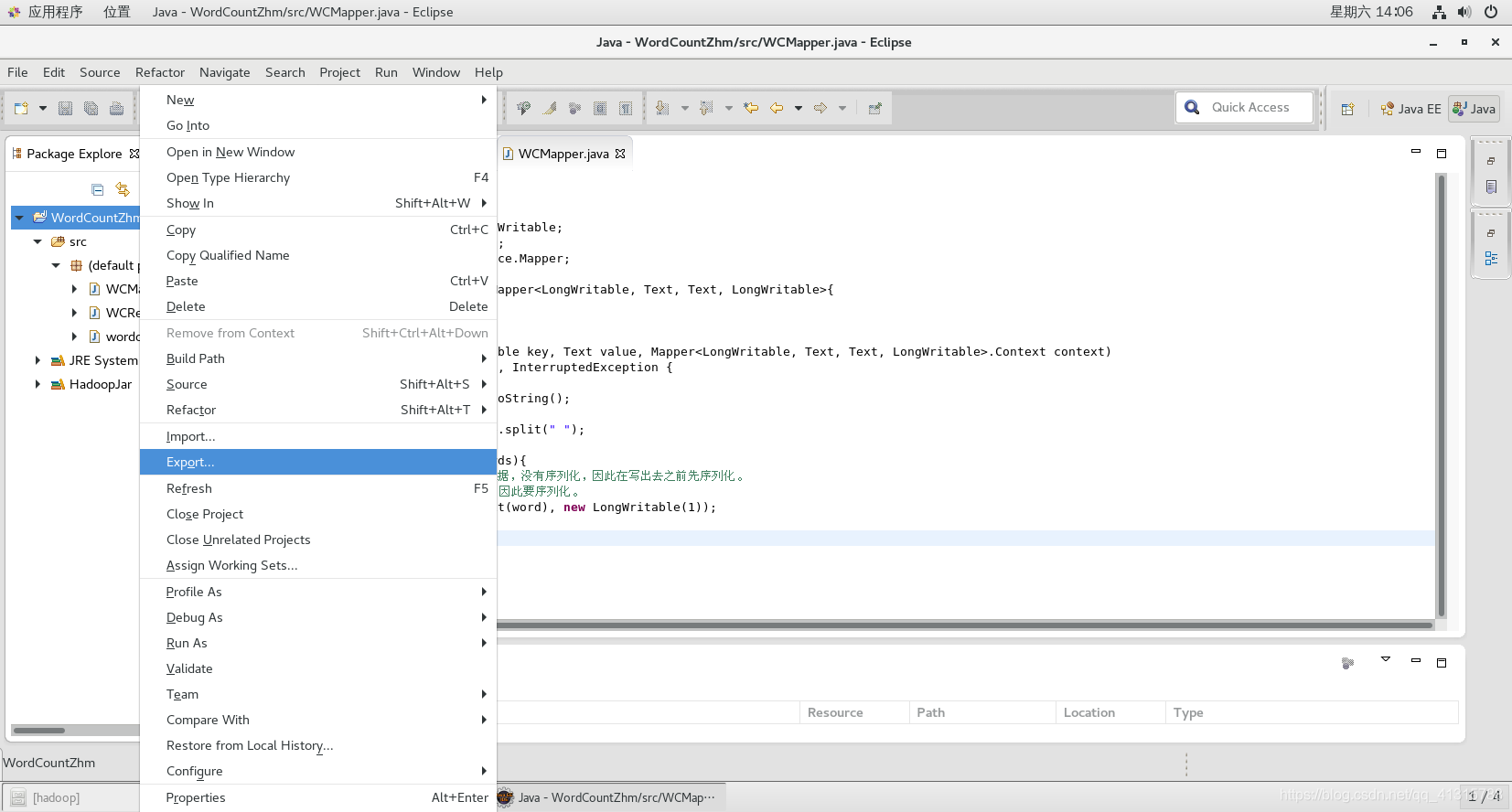
②Java→JAR file→Next

这里设置的目录要记住,我设置的为:/usr/local/src/hadoop/hadoop-2.7.7/
5.运行测试WordCount
(1)进入上一步生成的Jar包所在的目录下
# cd /usr/local/src/hadoop/hadoop-2.7.7/

(2)创建一个文档文件
# vi wordtest
输入自己想要统计单词数的文档,我填入的是如下内容
hello nongyuanwei
hello shenyaxin
hello huchen
hello luying
hello wangli
hello danche
hello jiangyunsheng
hello huachenyu
shenyaxin is working there
nongyuanwei is playing there
they are stupid
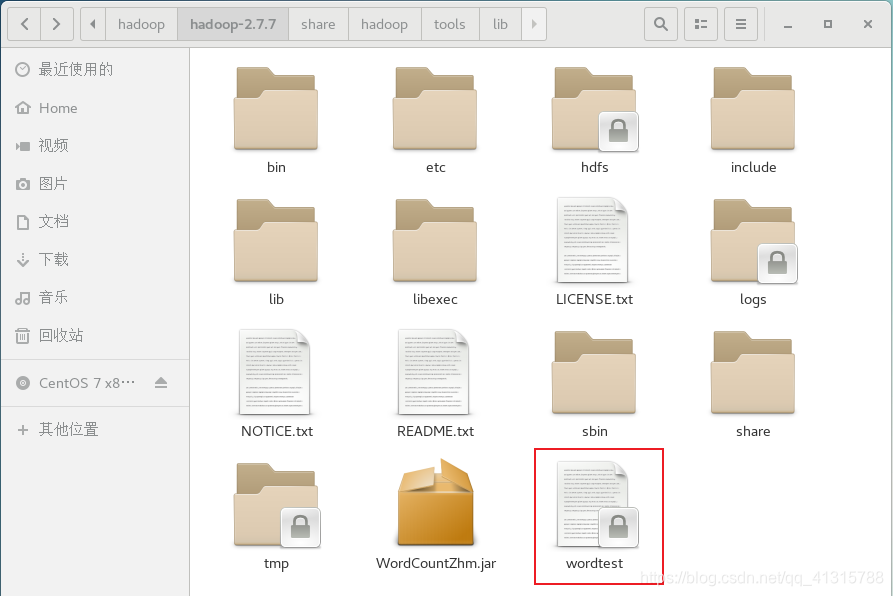
(3)上传文件到HDFS系统中
# hadoop fs -put wordtest hdfs://localhost:9000/wordtest
(4)查看hafs文件系统内容
# hadoop fs -ls hdfs://localhost:9000/

(5)执行应用、并查看时间开销
# time hadoop jar WordCountZhm.jar wordcount /wordtest /WCOut
执行成功!

时间开销:

(6)查看hafs文件系统内容
# hadoop fs -ls hdfs://localhost:9000/

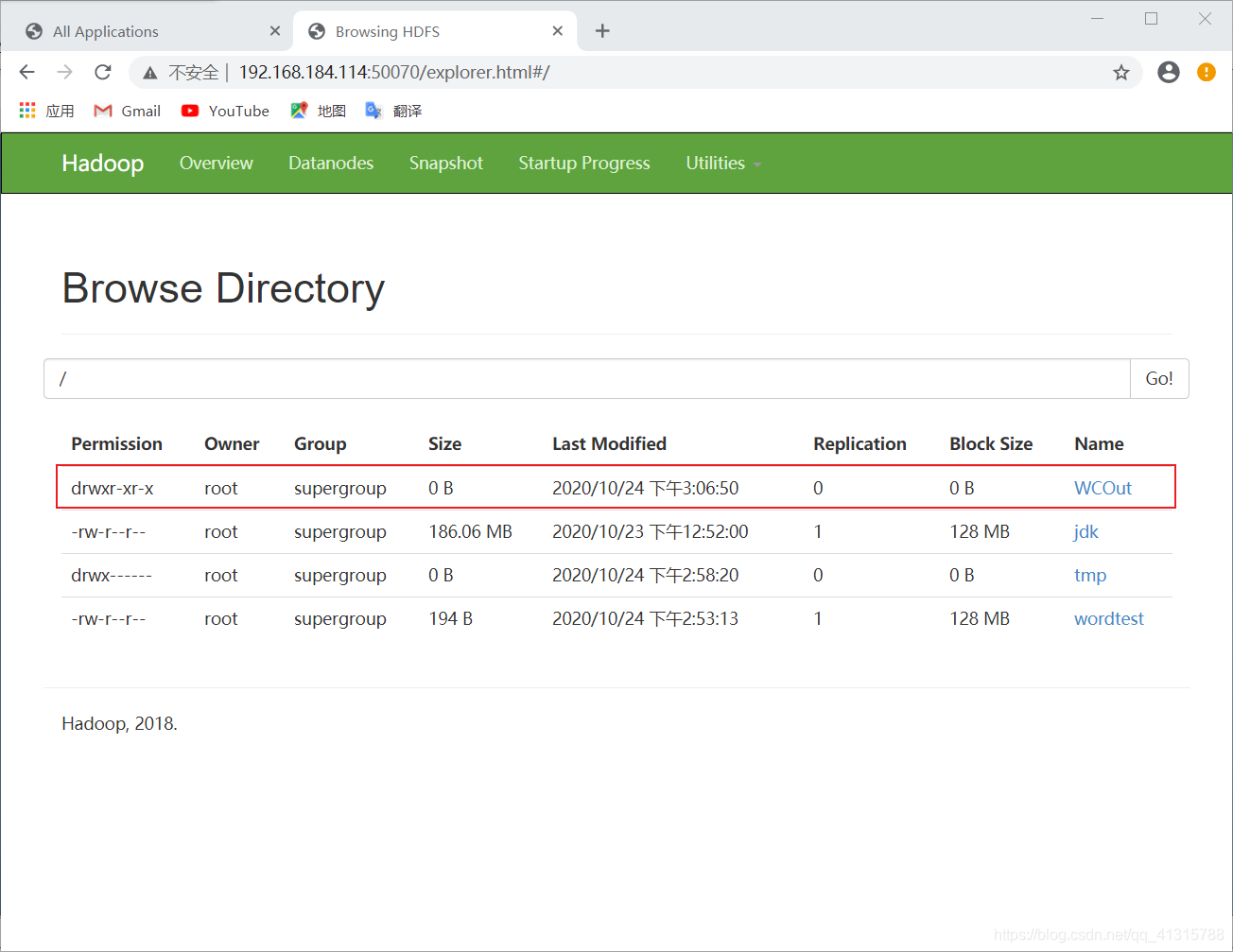
(7)查看统计的单词数结果
# hadoop fs -cat /WCOut/part-r-00000
