要想使用这些流式处理工具,那么就必须得了解正则表达式,由于正则表达式内容较多,一篇博客肯定写不完,所以这里只是简单的讲一下正则表达式的常用语法。
正则表达式
元字符
| 选项 | 说明 |
|---|---|
| \ | 转义字符 |
| . | 匹配任意一个字符 |
| * | 匹配其前面的字符0次或者n次 |
| ^ | 匹配开头 |
| $ | 匹配结尾 |
| [a-z] | 匹配方括号中的任意一个字符 |
拓展元字符
| 选项 | 说明 |
|---|---|
| + | 匹配前面的正则表达式至少一次 |
| ? | 匹配前面的正则表达式,出现0次或者一次 |
将这些元字符搭配起来,就成为了正则表达式,在下面几个工具的用例中会进行具体演示
下面介绍Linux中流式文本处理的三剑客——文本过滤工具grep、文本编辑工具sed、文本报告生成器awk
grep
grep是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。它也是我们在linux中最常用到的工具之一
语法
grep [选项](查询内容)(参数)
常用选项
-i:忽略大小写
-r:递归读取一个目录下所有文件
-E:支持拓展正则表达式
sed
sed是一种强大的文本编辑工具。它一次处理一行内容,处理时把当前处理行存储在临时缓冲区中(模式空间)中,接着使用sed命令处理缓冲区中的内容,把处理完的数据送往终端,接着输出下一行数据,直至文件末尾
语法
sed [选项] '命令' (参数)
常用选项
-e:直接在指令列模式上进行sed的动作编辑,即可以使用多次命令
-n:只输出匹配行(也可以指定修改行)
-r:支持使用扩展正则表达式
常用命令
a:追加,在下一行出现
i:插入,在上一行出现
d:删除
s:查找并替换
p:打印当前模式空间内容
使用示范,以下列文本分别进行增删改
hello
world
this
is
test
file
aaaaa
bbbbbbb
cccccccccc
123123124
world
hello
在以t开头的行的下一行追加xxxxxxxxx
cat test3 | sed '/^t/axxxxxxxxx'

删除所有以d结尾的行
cat test3 | sed '/d$/d'

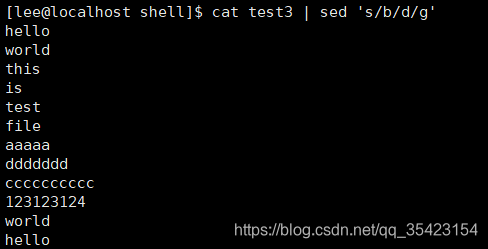
将文本中的所有b替换为d
cat test3 | sed 's/b/d/g'
awk
awk一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
其实awk是是一门用于处理文本文件的编程语言,而gawk是这门编程语言的具体实现,因此其支持和shell类似的算术运算、条件判断、流程控制等语法。
下面是man手册中awk的说明,当我们查询awk的时候就会自动跳转至gawk

语法
awk [选项] ‘匹配模式1{
执行操作1} 匹配模式2{
执行操作2}......’ (参数)
注意:只有匹配了pattern的行才会执行action
同时也可以指定开头和结尾执行的内容
awk [选项] ‘BEGIN{
开始时执行的内容} 匹配模式1{
执行操作1} END{
结束时执行的内容}’ (参数)
注意:BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。
常用选项
-F<分隔字符>:指定输入文件折分隔符
-v:赋值一个用户定义变量
常用系统变量
FILENAME:文件名
NR:已读的记录数(即当前的行数)
NF:浏览记录的域的个数(切割后,列的个数)
由于awk数组、运算、条件判断、流程控制、函数等内容与shell和c语言高度类似,这里就不多花篇幅介绍了
使用示范:切割出ifconfig中ens38的ip地址
ens38: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.220.128 netmask 255.255.255.0 broadcast 192.168.220.255
inet6 fe80::8e00:5dc0:711b:a9cf prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:4e:dd:e4 txqueuelen 1000 (Ethernet)
RX packets 1513042 bytes 952654297 (908.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1444185 bytes 1229233776 (1.1 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 185821127 bytes 25600956325 (23.8 GiB)
RX errors 0 dropped 5322 overruns 0 frame 0
TX packets 185821127 bytes 25600956325 (23.8 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ifconfig ens38 | grep inet\ | awk -F " " '{print$2}'

使用示范:查找出文本中的空行
the day is sunny the the
the sunny is is
awk '/^$/{print NR}' words

其它常用工具
以下是其他常用的工具,由于用法简单,所以这里就简单介绍一下
cut
cut的主要功能就是剪切数据
语法
cut [选项](参数)
常用选项
-f:列号,提取第几列
-d<分隔字符>:分隔符,按照指定分隔符分割列
使用示范:获取文本中的姓名
name age
alice 21
ryan 30
cat test | cut -d ' ' -f 1

sort
sort用于对文本内容进行排序
语法
sort [选项](参数)
常用选项
-t<分隔字符>:指定排序时所用的栏位分隔字符
-n:依照数值的大小排序
-r:以相反的顺序来排序
-k:指定需要排序的列
使用示范:对文本中的数据进行排序
123123
42
647
453
6789
23
1
457
97312
cat nums | sort -n

uniq
uniq命令用于对数据流进行去重,通常与sort搭配使用
语法
uniq [选项](参数)
常用参数
-c:在每列旁边显示该行重复出现的次数;
-d:仅显示重复出现的行列;
使用示范:统计文本中每个单词出现的次数
the
day
is
sunny
the
the
the
sunny
is
is
先去重,根据重复的次数进行排序
cat test2 | uniq -c | sort -n

tr
tr用于对文本内容进行修改、替换、压缩
语法
tr [选项](参数)
常用参数
-d:删除所有属于第一字符集的字符;
-s:把连续重复的字符以单独一个字符表示
使用示范:将小写转换为大写
the day is sunny the the
the sunny is is
cat words | tr 'a-z' 'A-Z'

常见面试题
以下题目来源于leetcode
第十行
给定一个文本文件 file.txt,请只打印这个文件中的第十行。
示例:
假设 file.txt 有如下内容:
Line 1
Line 2
Line 3
Line 4
Line 5
Line 6
Line 7
Line 8
Line 9
Line 10
你的脚本应当显示第十行:
Line 10
说明:
- 如果文件少于十行,你应当输出什么?
- 至少有三种不同的解法,请尝试尽可能多的方法来解题。
答案:
解法1:sed -n '10p' file.txt
解法2:awk 'NR==10{print $0}' file.txt
解法3:tail -n +10 file.txt | head -n 1
解题思路:
- 解法1的思路即使用sed的-n选项来只显示匹配行,然后用p命令来输出第十行
- 解法2的思路是使用awk中的系统变量NR来指定行号
- 解法3的思路是首先用tail -n +10(+为指定开始的行号)选项来获取从第十行开始的内容,接着使用head -n 1进行过滤,即只留下第一条数据,也就是第十行的内容
有效电话号码
给定一个包含电话号码列表(一行一个电话号码)的文本文件 file.txt,写一个 bash 脚本输出所有有效的电话号码。
你可以假设一个有效的电话号码必须满足以下两种格式: (xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一个数字)
你也可以假设每行前后没有多余的空格字符。
示例:
假设 file.txt 内容如下:
987-123-4567
123 456 7890
(123) 456-7890
你的脚本应当输出下列有效的电话号码:
987-123-4567
(123) 456-7890
答案:
awk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/' file.txt
解题思路:
- 直接使用awk用正则表达式进行匹配即可
统计词频
写一个 bash 脚本以统计一个文本文件 words.txt 中每个单词出现的频率。
为了简单起见,你可以假设:
words.txt只包括小写字母和 ’ ’ 。
每个单词只由小写字母组成。
单词间由一个或多个空格字符分隔
示例:
the day is sunny the the
the sunny is is
你的脚本应当输出(以词频降序排列):
the 4
is 3
sunny 2
day 1
答案:
cat words.txt | tr -s ' ' '\n' | sort | uniq -c | sort -nr | awk '{print $2,$1}'
解题思路:
- 由于每个单词以空格为间隔,而结果是按行统计,所以使用tr命令将空格替换为换行符,使得每个单词一行
- 我们需要对出现次数进行统计,所以先使用sort对数据进行排序,使得相邻的靠在一起,然后使用uniq进行排序,并用-c选项统计出重复的次数
- 使用sort -nr,利用重复次数进行降序排序
- 使用awk对文本进行处理,将单词放在前面,次数放在后面
转置文件
给定一个文件 file.txt,转置它的内容。
你可以假设每行列数相同,并且每个字段由 ’ ’ 分隔.
示例:
假设 file.txt 文件内容如下:
name age
alice 21
ryan 30
应当输出:
name alice ryan
age 21 30
答案:
awk '{
for (i=1; i<=NF; i++)
{
if (NR==1)
{
res[i]=$i
}
else
{
res[i]=res[i]" "$i
}
}
}
END{
for(j=1; j<=NF; j++)
{
print res[j]
}
}' file.txt
解题思路:
- 由题意可得,我们需要将行和列反转过来,所以我们需要一个数组来保存每行的字符串
- 当行号为1时,说明列号为i个单词就是第i行的开头
- 当行号不为1时,将列号为i个单词追加到数组第i项中,也就是反转后的第i行
- 需要注意的是,由于awk是按行读取的,所以我们只需要一层循环来处理每一列即可