在介绍Raft算法之前,请考虑一下如果有机会,你会怎么设计一个分布式系统?注意,这里所说的分布式系统是几台服务器组成的一个对外服务的系统,比如分布式KV系统、分布式数据库系统等。
如果是单机系统,数据一般都在本地,基本不需要与外部通信,比如单机数据库系统。但如果有一天你的系统遇到了单机系统难以承受的高请求量,为了防止系统宕机,也为了提高系统的可用性,可以搭建类似master-slave结构的系统,并且允许请求落到slave服务器上。
经过一段时间的设计和编码,你可能会发现这个系统没有想象中那么简单。首先,相比单机系统,分布式系统需要和多台服务器通信,而通信有超时的可能,此时发送方无法确定通信是成功还是失败。其次,一份数据被放到了多台服务器,数据更新有延迟。最后,一旦master服务器宕机,没有一个自动的机制可以立马提升slave服务器为master服务器。
这时你可能会想,是否有方法可以解决上述问题?或者说是否有框架可以解决分布式系统所面临的问题?答案是没有,依据是接下来要讲到的分布式系统领域的CAP定理。
CAP分别是如下3个单词的首字母缩写。
CAP定理指出,在异步网络模型中,不存在一个系统可以同时满足上述3个属性。换句话说,分布式系统必须舍弃其中的一个属性。
下图展示了分布式系统中不存在同时覆盖3个属性的区域,但是可以找到同时覆盖两个属性的区域。
在文章开头提到的系统实现问题中,通信超时和更新延迟都属于一致性问题,出现这个问题的原因是存在多台服务器,而每台服务器都有自己的数据。数据冗余虽然可以提高系统的可用性和分区容错性,但是相应地难以满足强一致性。如果想要解决一致性问题,也就是达到强一致性,比如把所有请求全部通过单台服务器处理,那么就很难达到高可用性。
CAP定理对于分布式系统的设计是一个很重要的参考。对于需要在分布式条件下运行的系统来说,如何在一致性、可用性和分区容错性中取舍,或者说要弱化哪一个属性,是首先需要考虑的问题。从经验上来说,可用性或一致性往往是被弱化的对象。
对于要求高可用性的系统来说,往往会保留强一致性。典型的例子就是延迟处理,利用Message Queue之类的中间件,在后台逐个处理队列中的请求,当处理完毕时,系统达到强一致性状态。但是要求强一致性的系统,比如元数据系统、分布式数据库系统,它们的可用性往往是有上限的。
从实现效果上来说,很多人或多或少都了解或者设计过具有强一致性的系统。但是,大部分人并不了解强一致性的系统是如何运作的,也不知道该怎么设计。老实说这确实很难,以至于计算机科学界有一类专门解决这种问题的算法 —— 共识算法。
Paxos算法
Paxos算法是Leslie Lamport在1998年发表的The Part-Time Parliament中提出的一种共识算法。
Paxos算法除了难懂之外,还难以实现。尽管如此,以下服务还是在生产环境中使用了Paxos算法和Paxos算法的修改版。
Paxos算法中的节点有以下3种可能的角色:
Paxos算法中的决议过程分两种,一种是对单个value(值)的决议过程,也就是对单个值达成一致;另一种是针对连续多个value的决议过程。前者称为Basic Paxos,后者称为Multi Paxos。
Basic Paxos的过程如下:
可以看到,对于多个value,Basic Paxos两次来回的决议使其性能不是很理想,所以有针对连续多个value决议的Multi Paxos。
Multi Paxos的基本思想是先使用Basic Paxos决议出Leader,再由Leader推进决议。Multi Paxos和Basic Paxos具体有以下不同。
每个Proposer使用唯一的id标识。
使用Basic Paxos在所有Proposer中选出一个Leader,由Leader提交proposal给Acceptor表决,这样Basic Paxos中的1~3步可以跳过,提高效率。
以上只是对Paxos算法最基本的理解,但在实际实现中还有很多具体问题需要解决。因为部分问题难以解决或者没有可以参考的解决方案,导致以下Paxos的变种算法的出现(按出现的时间先后排列)。
从系统实现的角度来说,从变种算法中选择一个并实现可能是比较好的选择,但是无法避免地要对Paxos有一定了解才能开始编码。到了2014年,出现了一种更容易理解的共识算法 —— Raft算法。
Raft算法
Raft算法由斯坦福大学的Diego Ongaro和John Ousterhout在2014年提出。在保证和Paxos算法一样的正确性的前提下,具体分析了选举及日志复制的实现,甚至还提供了参考代码。
关于Raft算法的论文中给出了计算机科学系学生对于Raft算法的可理解性的调查结果。结论是40多人中的大部分人认为Raft算法更容易理解,相对的只有个位数的人认为Paxos算法更容易理解。论文作者之一的Diego Ongaro之后在他的博士论文中进一步给出了Raft算法的详细分析,包括优化后的集群成员变更算法。
Raft算法的官方网站raft.github.io中给出了可视化的Raft算法中Leader的选举过程(另一个网站thesecretlivesofdata.com给出了更详细的Leader选举和日志复制的可视化过程),同时给出了一些Raft算法相关的论文、演讲和教程链接。对于想要快速了解Raft算法的人来说,这是一个很好的入口。
官方网站主页上还给出了一些Raft算法实现的列表,其中很多是试验性的实现。这些实现的源代码大部分可以在GitHub上找到。如果想要特定语言的实现版本,可以尝试在上面查找。官方网站主页上Raft算法实现的列表可以通过GitHub Pages的Pull Request通知管理员修改。如果对自己的算法实现有信心,可以克隆主页的GitHub库,然后添加自己的算法实现后提交Pull Request。
生产环境级别的Raft算法实现比较有名的是基于Go语言的etcd,基于etcd设计出来的上层软件可以用于生产环境。
下面大致介绍一下Raft算法。
Raft算法是单Leader、多Follower模型,可以理解为主从模型。Raft算法中有以下3种角色:
系统在启动后会马上选举出Leader,之后的请求全部通过Leader处理。Leader在处理请求时,会先加一条日志,把日志同步给Follower。当写入成功的节点过半之后持久化日志,通知Follower也持久化,最后将结果回复给客户端。
ZAB算法
现存的并且可以作为集群一部分的分布式同步软件中,Apache ZooKeeper(简称ZooKeeper)可能是最有名的一个。ZooKeeper原本是Apache Hadoop的一部分,现在是顶级Apache Project中的一个。ZooKeeper被很多大公司使用,是一个经过生产环境考验的中间件。
从功能上来说,ZooKeeper是一个分布式等级型KV服务(Hierarchical Key-Value Store)。和一般用于缓存的KV服务不同,客户端可以监听某个节点下的Key的变更,因此ZooKeeper经常被用于分布式配置服务。
ZooKeeper的核心是一个名叫ZAB的算法,这是Paxos算法的一个变种。ZAB算法的详细内容这里不做展开,一方面ZAB算法和Paxos算法有相同的地方,另一方面ZooKeeper在面向客户端方面所做的设计可能比ZAB算法更加复杂,因此就算理解了ZAB算法也不一定能完全理解ZooKeeper的设计。
如何选择
总体来说,如果是第一次接触分布式一致性算法,那么Raft算法是一个很好的入门算法。但如果想深入研究,Paxos算法仍旧是无法回避的。其实算法本身并无优劣之分,理解其背后的思想才是最重要的。
如果想使用现成的分布式一致性中间件,那么Apache ZooKeeper可能是一个不错的选择。如果想进一步了解分布式一致性的算法细节实现,那么ZooKeeper的源代码很值得阅读和参考。
如果是单机系统,数据一般都在本地,基本不需要与外部通信,比如单机数据库系统。但如果有一天你的系统遇到了单机系统难以承受的高请求量,为了防止系统宕机,也为了提高系统的可用性,可以搭建类似master-slave结构的系统,并且允许请求落到slave服务器上。
经过一段时间的设计和编码,你可能会发现这个系统没有想象中那么简单。首先,相比单机系统,分布式系统需要和多台服务器通信,而通信有超时的可能,此时发送方无法确定通信是成功还是失败。其次,一份数据被放到了多台服务器,数据更新有延迟。最后,一旦master服务器宕机,没有一个自动的机制可以立马提升slave服务器为master服务器。
这时你可能会想,是否有方法可以解决上述问题?或者说是否有框架可以解决分布式系统所面临的问题?答案是没有,依据是接下来要讲到的分布式系统领域的CAP定理。
分布式一致性算法开发实战

CAP分别是如下3个单词的首字母缩写。
Consistency:一致性
Availability:可用性
Partition-tolerance:分区容错性
CAP定理指出,在异步网络模型中,不存在一个系统可以同时满足上述3个属性。换句话说,分布式系统必须舍弃其中的一个属性。
下图展示了分布式系统中不存在同时覆盖3个属性的区域,但是可以找到同时覆盖两个属性的区域。
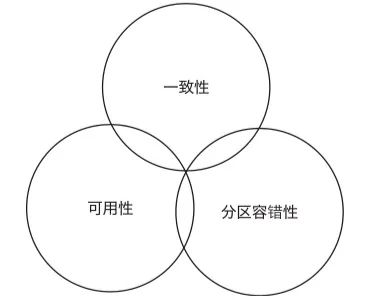
在文章开头提到的系统实现问题中,通信超时和更新延迟都属于一致性问题,出现这个问题的原因是存在多台服务器,而每台服务器都有自己的数据。数据冗余虽然可以提高系统的可用性和分区容错性,但是相应地难以满足强一致性。如果想要解决一致性问题,也就是达到强一致性,比如把所有请求全部通过单台服务器处理,那么就很难达到高可用性。
CAP定理对于分布式系统的设计是一个很重要的参考。对于需要在分布式条件下运行的系统来说,如何在一致性、可用性和分区容错性中取舍,或者说要弱化哪一个属性,是首先需要考虑的问题。从经验上来说,可用性或一致性往往是被弱化的对象。
对于要求高可用性的系统来说,往往会保留强一致性。典型的例子就是延迟处理,利用Message Queue之类的中间件,在后台逐个处理队列中的请求,当处理完毕时,系统达到强一致性状态。但是要求强一致性的系统,比如元数据系统、分布式数据库系统,它们的可用性往往是有上限的。
从实现效果上来说,很多人或多或少都了解或者设计过具有强一致性的系统。但是,大部分人并不了解强一致性的系统是如何运作的,也不知道该怎么设计。老实说这确实很难,以至于计算机科学界有一类专门解决这种问题的算法 —— 共识算法。
共识算法
Paxos算法
Paxos算法是Leslie Lamport在1998年发表的The Part-Time Parliament中提出的一种共识算法。
Paxos算法除了难懂之外,还难以实现。尽管如此,以下服务还是在生产环境中使用了Paxos算法和Paxos算法的修改版。
Google Chubby:分布式锁服务
Google Spanner:NewSQL
Ceph
Neo4j
Amazon Elastic Container Service
Paxos算法中的节点有以下3种可能的角色:
Proposer:提出提案,并向Acceptor发送提案。
Acceptor:参与决策,回应提案。如果提案获得多数(过半)Acceptor接受,则认为提案被批准。
Learner:不参与决策,只学习最新达成一致的提案。
Paxos算法中的决议过程分两种,一种是对单个value(值)的决议过程,也就是对单个值达成一致;另一种是针对连续多个value的决议过程。前者称为Basic Paxos,后者称为Multi Paxos。
Basic Paxos的过程如下:
Proposer生成全局唯一且递增的proposal id,并向所有Acceptor发送prepare请求。
Acceptor收到请求后,如果proposal id正常,则回复已接受的proposal id中最大的决议id和value。
Proposer接收到多数Acceptor的响应后,从应答中选择proposal id最大的value,并发送给所有Acceptor。
Acceptor收到proposal之后,接收并持久化当前proposal id和value。
Proposer收到多数Acceptor的响应之后形成决议,Proposer发送决议给所有Learner。
可以看到,对于多个value,Basic Paxos两次来回的决议使其性能不是很理想,所以有针对连续多个value决议的Multi Paxos。
Multi Paxos的基本思想是先使用Basic Paxos决议出Leader,再由Leader推进决议。Multi Paxos和Basic Paxos具体有以下不同。
每个Proposer使用唯一的id标识。
使用Basic Paxos在所有Proposer中选出一个Leader,由Leader提交proposal给Acceptor表决,这样Basic Paxos中的1~3步可以跳过,提高效率。
以上只是对Paxos算法最基本的理解,但在实际实现中还有很多具体问题需要解决。因为部分问题难以解决或者没有可以参考的解决方案,导致以下Paxos的变种算法的出现(按出现的时间先后排列)。
Disk Paxos,2002年
Cheap Paxos,2003年
Fast Paxos,2004年
Generalized Paxos,2005年
Stoppable Paxos,2008年
Vertical Paxos,2009年
从系统实现的角度来说,从变种算法中选择一个并实现可能是比较好的选择,但是无法避免地要对Paxos有一定了解才能开始编码。到了2014年,出现了一种更容易理解的共识算法 —— Raft算法。
Raft算法
Raft算法由斯坦福大学的Diego Ongaro和John Ousterhout在2014年提出。在保证和Paxos算法一样的正确性的前提下,具体分析了选举及日志复制的实现,甚至还提供了参考代码。
关于Raft算法的论文中给出了计算机科学系学生对于Raft算法的可理解性的调查结果。结论是40多人中的大部分人认为Raft算法更容易理解,相对的只有个位数的人认为Paxos算法更容易理解。论文作者之一的Diego Ongaro之后在他的博士论文中进一步给出了Raft算法的详细分析,包括优化后的集群成员变更算法。
Raft算法的官方网站raft.github.io中给出了可视化的Raft算法中Leader的选举过程(另一个网站thesecretlivesofdata.com给出了更详细的Leader选举和日志复制的可视化过程),同时给出了一些Raft算法相关的论文、演讲和教程链接。对于想要快速了解Raft算法的人来说,这是一个很好的入口。
官方网站主页上还给出了一些Raft算法实现的列表,其中很多是试验性的实现。这些实现的源代码大部分可以在GitHub上找到。如果想要特定语言的实现版本,可以尝试在上面查找。官方网站主页上Raft算法实现的列表可以通过GitHub Pages的Pull Request通知管理员修改。如果对自己的算法实现有信心,可以克隆主页的GitHub库,然后添加自己的算法实现后提交Pull Request。
生产环境级别的Raft算法实现比较有名的是基于Go语言的etcd,基于etcd设计出来的上层软件可以用于生产环境。
下面大致介绍一下Raft算法。
Raft算法是单Leader、多Follower模型,可以理解为主从模型。Raft算法中有以下3种角色:
Leader:集群的Leader
Candidate:想要成为Leader的候选者
Follower:Leader的跟随者。
系统在启动后会马上选举出Leader,之后的请求全部通过Leader处理。Leader在处理请求时,会先加一条日志,把日志同步给Follower。当写入成功的节点过半之后持久化日志,通知Follower也持久化,最后将结果回复给客户端。
ZAB算法
现存的并且可以作为集群一部分的分布式同步软件中,Apache ZooKeeper(简称ZooKeeper)可能是最有名的一个。ZooKeeper原本是Apache Hadoop的一部分,现在是顶级Apache Project中的一个。ZooKeeper被很多大公司使用,是一个经过生产环境考验的中间件。
从功能上来说,ZooKeeper是一个分布式等级型KV服务(Hierarchical Key-Value Store)。和一般用于缓存的KV服务不同,客户端可以监听某个节点下的Key的变更,因此ZooKeeper经常被用于分布式配置服务。
ZooKeeper的核心是一个名叫ZAB的算法,这是Paxos算法的一个变种。ZAB算法的详细内容这里不做展开,一方面ZAB算法和Paxos算法有相同的地方,另一方面ZooKeeper在面向客户端方面所做的设计可能比ZAB算法更加复杂,因此就算理解了ZAB算法也不一定能完全理解ZooKeeper的设计。
如何选择
总体来说,如果是第一次接触分布式一致性算法,那么Raft算法是一个很好的入门算法。但如果想深入研究,Paxos算法仍旧是无法回避的。其实算法本身并无优劣之分,理解其背后的思想才是最重要的。
如果想使用现成的分布式一致性中间件,那么Apache ZooKeeper可能是一个不错的选择。如果想进一步了解分布式一致性的算法细节实现,那么ZooKeeper的源代码很值得阅读和参考。
总结