在DaemonSet中讲到使用nodeSelector选择Pod要部署的节点,其实Kubernetes还支持更精细、更灵活的调度机制,那就是亲和(affinity)与反亲和(anti-affinity)调度。
Kubernetes支持节点和Pod两个层级的亲和与反亲和。通过配置亲和与反亲和规则,可以允许您指定硬性限制或者偏好,例如将前台Pod和后台Pod部署在一起、某类应用部署到某些特定的节点、不同应用部署到不同的节点等等。
Node Affinity(节点亲和)
您肯定也猜到了亲和性规则的基础肯定也是标签,先来看一下CCE集群中节点上有些什么标签。
$ kubectl describe node 192.168.0.212
Name: 192.168.0.212
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
failure-domain.beta.kubernetes.io/is-baremetal=false
failure-domain.beta.kubernetes.io/region=cn-east-3
failure-domain.beta.kubernetes.io/zone=cn-east-3a
kubernetes.io/arch=amd64
kubernetes.io/availablezone=cn-east-3a
kubernetes.io/eniquota=12
kubernetes.io/hostname=192.168.0.212
kubernetes.io/os=linux
node.kubernetes.io/subnetid=fd43acad-33e7-48b2-a85a-24833f362e0e
os.architecture=amd64
os.name=EulerOS_2.0_SP5
os.version=3.10.0-862.14.1.5.h328.eulerosv2r7.x86_64这些标签都是在创建节点的时候CCE会自动添加上的,下面介绍几个在调度中会用到比较多的标签。
- failure-domain.beta.kubernetes.io/region:表示节点所在的区域,如果上面这个节点标签值为cn-east-3,表示节点在上海一区域。
- failure-domain.beta.kubernetes.io/zone:表示节点所在的可用区(availability zone)。
- kubernetes.io/hostname:节点的hostname。
另外在Label:组织Pod的利器章节还介绍自定义标签,通常情况下,对于一个大型Kubernetes集群,肯定会根据业务需要定义很多标签。
在DaemonSet中介绍了nodeSelector,通过nodeSelector可以让Pod只部署在具有特定标签的节点上。如下所示,Pod只会部署在拥有gpu=true这个标签的节点上。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
nodeSelector: # 节点选择,当节点拥有gpu=true时才在节点上创建Pod
gpu: true
...通过节点亲和性规则配置,也可以做到同样的事情,如下所示。
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu
labels:
app: gpu
spec:
selector:
matchLabels:
app: gpu
replicas: 3
template:
metadata:
labels:
app: gpu
spec:
containers:
- image: nginx:alpine
name: gpu
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
imagePullSecrets:
- name: default-secret
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu
operator: In
values:
- "true"看起来这要复杂很多,但这种方式可以得到更强的表达能力,后面会进一步介绍。
这里affinity表示亲和,nodeAffinity表示节点亲和,requiredDuringSchedulingIgnoredDuringExecution非常长,不过可以将这个分作两段来看:
- 前半段requiredDuringScheduling表示下面定义的规则必须强制满足(require)。
- 后半段IgnoredDuringExecution表示不会影响已经在节点上运行的Pod,目前Kubernetes提供的规则都是以IgnoredDuringExecution结尾的,因为当前的节点亲缘性规则只会影响正在被调度的pod,最终,kubernetes也会支持RequiredDuringExecution,即去除节点上的某个标签,那些需要节点包含该标签的pod将会被剔除。
- 另外操作符operator的值为In,表示标签值需要在values的列表中,其他operator取值如下。
- NotIn:标签的值不在某个列表中
- Exists:某个标签存在
- DoesNotExist:某个标签不存在
- Gt:标签的值大于某个值(字符串比较)
- Lt:标签的值小于某个值(字符串比较)
需要说明的是并没有nodeAntiAffinity(节点反亲和),因为NotIn和DoesNotExist可以提供相同的功能。
下面来验证这段规则是否生效,首先给192.168.0.212这个节点打上gpu=true的标签。
$ kubectl label node 192.168.0.212 gpu=true
node/192.168.0.212 labeled
$ kubectl get node -L gpu
NAME STATUS ROLES AGE VERSION GPU
192.168.0.212 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2 true
192.168.0.94 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2
192.168.0.97 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2 创建这个Deployment,可以发现所有的Pod都部署在了192.168.0.212这个节点上。
$ kubectl create -f affinity.yaml
deployment.apps/gpu created
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE
gpu-6df65c44cf-42xw4 1/1 Running 0 15s 172.16.0.37 192.168.0.212
gpu-6df65c44cf-jzjvs 1/1 Running 0 15s 172.16.0.36 192.168.0.212
gpu-6df65c44cf-zv5cl 1/1 Running 0 15s 172.16.0.38 192.168.0.212节点优先选择规则
上面讲的requiredDuringSchedulingIgnoredDuringExecution是一种强制选择的规则,节点亲和还有一种优先选择规则,即preferredDuringSchedulingIgnoredDuringExecution,表示会根据规则优先选择哪些节点。
为演示这个效果,先为上面的集群添加一个节点,且这个节点跟另外三个节点不在同一个可用区,创建完之后查询节点的可用区标签,如下所示,新添加的节点在cn-east-3c这个可用区。
$ kubectl get node -L failure-domain.beta.kubernetes.io/zone,gpu
NAME STATUS ROLES AGE VERSION ZONE GPU
192.168.0.100 Ready <none> 7h23m v1.15.6-r1-20.3.0.2.B001-15.30.2 cn-east-3c
192.168.0.212 Ready <none> 8h v1.15.6-r1-20.3.0.2.B001-15.30.2 cn-east-3a true
192.168.0.94 Ready <none> 8h v1.15.6-r1-20.3.0.2.B001-15.30.2 cn-east-3a
192.168.0.97 Ready <none> 8h v1.15.6-r1-20.3.0.2.B001-15.30.2 cn-east-3a 下面定义一个Deployment,要求Pod优先部署在可用区cn-east-3a的节点上,可以像下面这样定义,使用preferredDuringSchedulingIgnoredDuringExecution规则,给cn-east-3a设置权重(weight)为80,而gpu=true权重为20,这样Pod就优先部署在cn-east-3a的节点上。
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu
labels:
app: gpu
spec:
selector:
matchLabels:
app: gpu
replicas: 10
template:
metadata:
labels:
app: gpu
spec:
containers:
- image: nginx:alpine
name: gpu
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
imagePullSecrets:
- name: default-secret
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
preference:
matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- cn-east-3a
- weight: 20
preference:
matchExpressions:
- key: gpu
operator: In
values:
- "true"来看实际部署后的情况,可以看到部署到192.168.0.212这个节点上的Pod有5个,而192.168.0.100上只有2个。
$ kubectl create -f affinity2.yaml
deployment.apps/gpu created
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
gpu-585455d466-5bmcz 1/1 Running 0 2m29s 172.16.0.44 192.168.0.212
gpu-585455d466-cg2l6 1/1 Running 0 2m29s 172.16.0.63 192.168.0.97
gpu-585455d466-f2bt2 1/1 Running 0 2m29s 172.16.0.79 192.168.0.100
gpu-585455d466-hdb5n 1/1 Running 0 2m29s 172.16.0.42 192.168.0.212
gpu-585455d466-hkgvz 1/1 Running 0 2m29s 172.16.0.43 192.168.0.212
gpu-585455d466-mngvn 1/1 Running 0 2m29s 172.16.0.48 192.168.0.97
gpu-585455d466-s26qs 1/1 Running 0 2m29s 172.16.0.62 192.168.0.97
gpu-585455d466-sxtzm 1/1 Running 0 2m29s 172.16.0.45 192.168.0.212
gpu-585455d466-t56cm 1/1 Running 0 2m29s 172.16.0.64 192.168.0.100
gpu-585455d466-t5w5x 1/1 Running 0 2m29s 172.16.0.41 192.168.0.212上面这个例子中,对于节点排序优先级如下所示,有个两个标签的节点排序最高,只有cn-east-3a标签的节点排序第二(权重为80),只有gpu=true的节点排序第三,没有的节点排序最低。
图1 优先级排序顺序
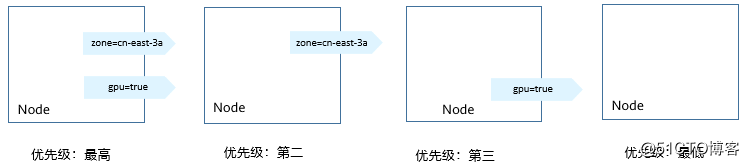
这里您看到Pod并没有调度到192.168.0.94这个节点上,这是因为这个节点上部署了很多其他Pod,资源使用较多,所以并没有往这个节点上调度,这也侧面说明preferredDuringSchedulingIgnoredDuringExecution是优先规则,而不是强制规则。
Pod Affinity(Pod亲和)
节点亲和的规则只能影响Pod和节点之间的亲和,Kubernetes还支持Pod和Pod之间的亲和,例如将应用的前端和后端部署在一起,从而减少访问延迟。Pod亲和同样有requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution两种规则。
来看下面这个例子,假设有个应用的后端已经创建,且带有app=backend的标签。
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
backend-658f6cb858-dlrz8 1/1 Running 0 2m36s 172.16.0.67 192.168.0.100将前端frontend的pod部署在backend一起时,可以做如下Pod亲和规则配置。
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
labels:
app: frontend
spec:
selector:
matchLabels:
app: frontend
replicas: 3
template:
metadata:
labels:
app: frontend
spec:
containers:
- image: nginx:alpine
name: frontend
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
imagePullSecrets:
- name: default-secret
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
app: backend创建frontend然后查看,可以看到frontend都创建到跟backend一样的节点上了。
$ kubectl create -f affinity3.yaml
deployment.apps/frontend created
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
backend-658f6cb858-dlrz8 1/1 Running 0 5m38s 172.16.0.67 192.168.0.100
frontend-67ff9b7b97-dsqzn 1/1 Running 0 6s 172.16.0.70 192.168.0.100
frontend-67ff9b7b97-hxm5t 1/1 Running 0 6s 172.16.0.71 192.168.0.100
frontend-67ff9b7b97-z8pdb 1/1 Running 0 6s 172.16.0.72 192.168.0.100这里有个topologyKey字段,意思是先圈定topologyKey指定的范围,然后再选择下面规则定义的内容。这里每个节点上都有kubernetes.io/hostname,所以看不出topologyKey起到的作用。
如果backend有两个Pod,分别在不同的节点上。
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
backend-658f6cb858-5bpd6 1/1 Running 0 23m 172.16.0.40 192.168.0.97
backend-658f6cb858-dlrz8 1/1 Running 0 2m36s 172.16.0.67 192.168.0.100给192.168.0.97和192.168.0.94打一个perfer=true的标签。
$ kubectl label node 192.168.0.97 perfer=true
node/192.168.0.97 labeled
$ kubectl label node 192.168.0.94 perfer=true
node/192.168.0.94 labeled
$ kubectl get node -L perfer
NAME STATUS ROLES AGE VERSION PERFER
192.168.0.100 Ready <none> 44m v1.15.6-r1-20.3.0.2.B001-15.30.2
192.168.0.212 Ready <none> 91m v1.15.6-r1-20.3.0.2.B001-15.30.2
192.168.0.94 Ready <none> 91m v1.15.6-r1-20.3.0.2.B001-15.30.2 true
192.168.0.97 Ready <none> 91m v1.15.6-r1-20.3.0.2.B001-15.30.2 true将podAffinity的topologyKey定义为perfer。
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: perfer
labelSelector:
matchLabels:
app: backend调度时,先圈定拥有perfer标签的节点,这里也就是192.168.0.97和192.168.0.94,然后再匹配app=backend标签的Pod,从而frontend就会全部部署在192.168.0.97上。
$ kubectl create -f affinity3.yaml
deployment.apps/frontend created
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
backend-658f6cb858-5bpd6 1/1 Running 0 26m 172.16.0.40 192.168.0.97
backend-658f6cb858-dlrz8 1/1 Running 0 5m38s 172.16.0.67 192.168.0.100
frontend-67ff9b7b97-dsqzn 1/1 Running 0 6s 172.16.0.70 192.168.0.97
frontend-67ff9b7b97-hxm5t 1/1 Running 0 6s 172.16.0.71 192.168.0.97
frontend-67ff9b7b97-z8pdb 1/1 Running 0 6s 172.16.0.72 192.168.0.97Pod AntiAffinity(Pod反亲和)
前面讲了Pod的亲和,通过亲和将Pod部署在一起,有时候需求却恰恰相反,需要将Pod分开部署,例如Pod之间部署在一起会影响性能的情况。
下面例子中定义了反亲和规则,这个规则表示Pod不能调度到拥有app=frontend标签Pod的节点上,也就是下面将frontend分别调度到不同的节点上(每个节点只有一个Pod)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
labels:
app: frontend
spec:
selector:
matchLabels:
app: frontend
replicas: 5
template:
metadata:
labels:
app: frontend
spec:
containers:
- image: nginx:alpine
name: frontend
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
imagePullSecrets:
- name: default-secret
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
app: frontend创建并查看,可以看到每个节点上只有一个frontend的Pod,还有一个在Pending,因为在部署第5个时4个节点上都有了app=frontend的Pod,所以第5个一直是Pending。
$ kubectl create -f affinity4.yaml
deployment.apps/frontend created
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
frontend-6f686d8d87-8dlsc 1/1 Running 0 18s 172.16.0.76 192.168.0.100
frontend-6f686d8d87-d6l8p 0/1 Pending 0 18s <none> <none>
frontend-6f686d8d87-hgcq2 1/1 Running 0 18s 172.16.0.54 192.168.0.97
frontend-6f686d8d87-q7cfq 1/1 Running 0 18s 172.16.0.47 192.168.0.212
frontend-6f686d8d87-xl8hx 1/1 Running 0 18s 172.16.0.23 192.168.0.94