B站弹幕
概述
之前看到了网上有人做过一些up的B站弹幕数据可视化,感觉还挺有意思,于是自己就动手做着玩了一下(没有做可视化)。祝福武汉,祝福中国!
项目实现
(1)获取弹幕数据,我本来想着是获取某一个up的全部视频的弹幕数据,后来发现了一个问题:弹幕数据是存在JSON或者XMl中的。数据依靠一个id号标识,我本以为就是视频的av号,结果查看元素后却发现不是。参考了网上的一些文档发现弹幕数据存储在一个url中,因此只需要获取这个网址中的内容即可。
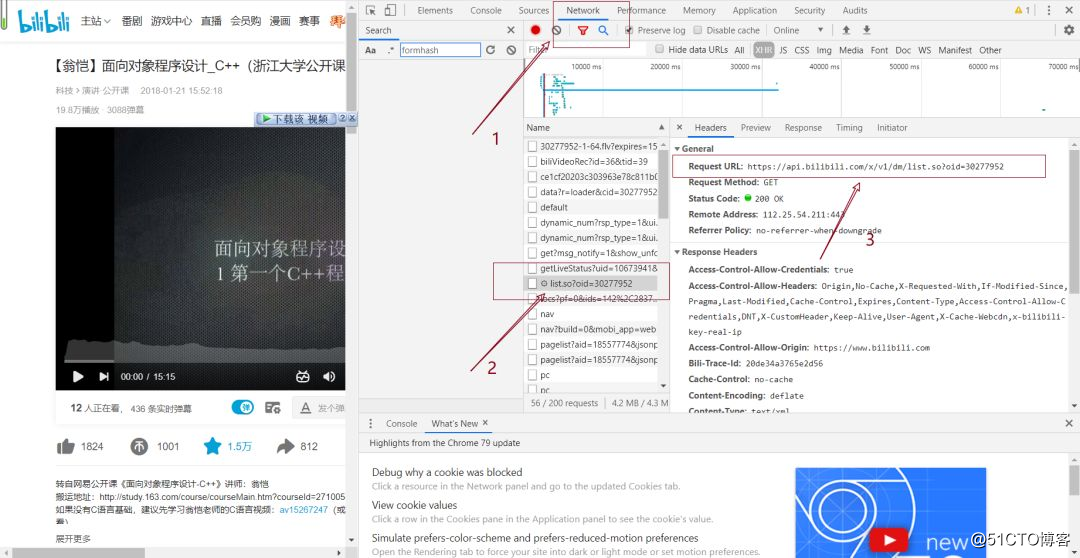
(2)获取数据,就采用爬虫惯用的requests模块即可
(3)解析数据
(4)数据持久化以及数据简单处理
初始化
扫描二维码关注公众号,回复:
12134951 查看本文章

首先初始化一些下面需要使用的基本参数
def __init__(self):
self.headers = {
# 自己添加自己的即可
}
self.base_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'
self.url = ''
self.barrage_result = []
self.danmu = []
self.danmu_count = []
初始化自己的headers,以及初始化一个基础的url。然后初始化几个下面要用的参数。
获取网页
获取网页信息,并将数据存储到本地
# 获取信息
def get_page(self):
# 延时操作,防止太快爬取
time.sleep(0.5)
response = requests.get(self.url, headers=self.headers)
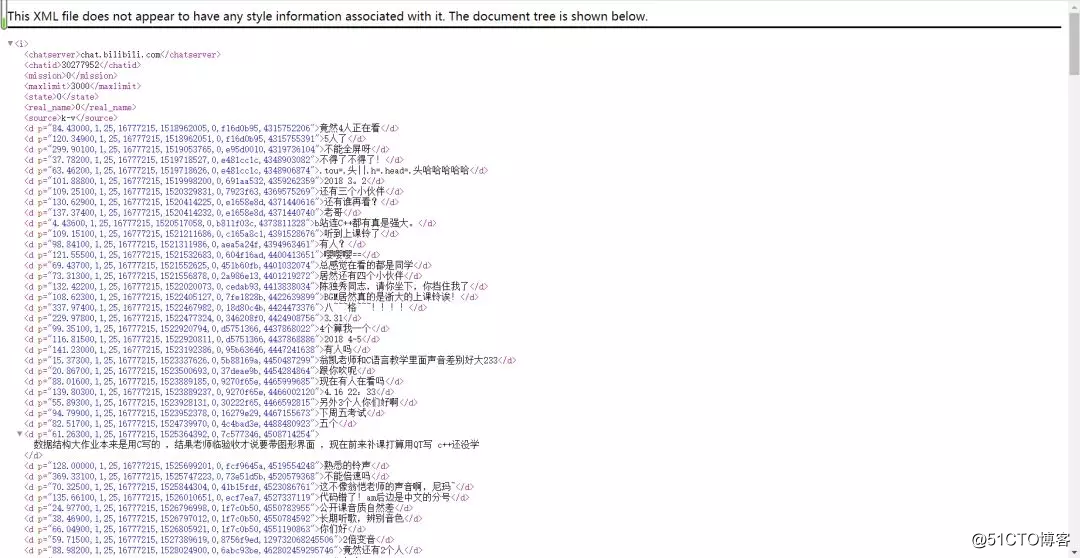
with open('bilibili.xml', 'wb') as f:
f.write(response.content解析数据
解析网页,将所有弹幕信息存储在danmu列表中
# 解析网页 将所有弹幕信息存储在danmu列表中
def param_page(self):
time.sleep(1)
if self.barrage_result:
# 文件路径,html解析器
html = etree.parse('bilibili.xml', etree.HTMLParser())
# xpath解析,获取当前所有的d标签下的所有文本内容
results = html.xpath('//d//text()')
# 将去重后的弹幕存储起来
for one in results:
self.danmu.append(one)
print('总的实时弹幕数量:', len(self.danmu))数据持久化
对获取到的数据进行简单处理,并持久化,由于后期还有其他的操作,因此我存了两种形式。
# 对获取的弹幕数据进行简单处理
def ana_result(self):
print('开始处理弹幕')
for one_danmu in self.danmu:
if one_danmu not in self.danmu_count:
self.danmu_count.append(one_danmu)
print('弹幕去重后数量为:', len(self.danmu_count))
with open('tanmu.txt', 'w', encoding='utf-8') as f:
for danmu in self.danmu_count:
# 数量的统计
amount = self.danmu.count(danmu)
f.write(danmu + ':' + str(amount) + '\n')
book = xlwt.Workbook(encoding='utf-8-sig', style_compression=0)
sheet = book.add_sheet('B站部分视频弹幕', cell_overwrite_ok=True)
sheet.write(0, 0, '弹幕内容')
sheet.write(0, 1, '弹幕出现次数')
n = 1
for danmu in self.danmu_count:
amount = self.danmu.count(danmu)
sheet.write(n, 0, danmu)
sheet.write(n, 1, amount)
n = n + 1
book.save(u'B站部分视频弹幕.xls')
一般而言数据持久化之后也就结束了,不过为了后面一些操作,在此处我又做的一个某关键字弹幕计数的功能
# 对含有某关键字的弹幕计数
def key_count(self, key):
value = key
pattern = '.*' + value + '.*'
tempList = []
for one in self.danmu:
obj = re.findall(pattern, one)
if len(obj) > 0:
tempList.extend(obj)
print('弹幕中含有', key, '的弹幕数量为:', len(tempList))
整个爬虫我用以下程序段调用。
def run(self):
for i in range(145134329, 145144329):
self.get_url(i)
self.barrage_result = self.get_page()
self.param_page()
self.key_count('武汉加油')
self.key_count('武汉')
self.ana_result()
在range中填写一个oid列表,遍历这个列表去抓取弹幕数据。如果没有已知oid列表可以像我上面的方法去遍历。
运行时界面如下。