K均值算法
K均值聚类的核心目标是将给定的数据集划分成K个簇,并给出每个数据对应的簇中心点。
数据预处理,包括但不限于归一化,离群点处理等
随机选择K个簇中心,我们记为


定义代价函数,
令t=0,1,2,3...,进行迭代,重复直至J收敛
此时,对于每个样本,将分配到距离最近的簇
对于每个簇k,重新计算各个簇的中心
K均值在迭代中,如果J没有达到最小值,那么首先重新计算当前簇的中心,调整每个样例
所属的类别
来让J的值减少,之后计算
,调整簇中心
使J减少,如此重复迭代,直到J减少到最小值,
此时也收敛。
K均值算法示意图
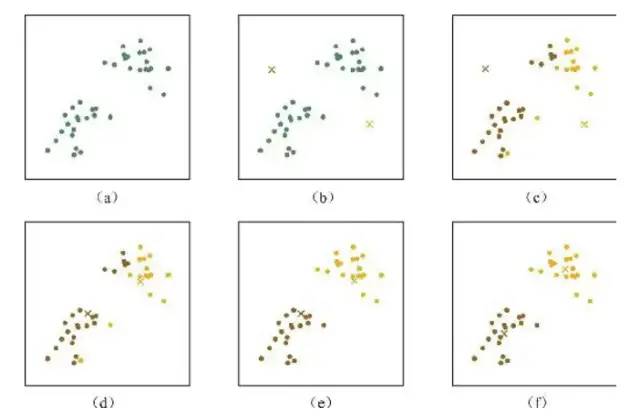
K均值聚类算法迭代图
简单说,就是一开始我们假设的簇中心是随便找的,并不能将数据合理的分类,我们不断计算各个数据与最近簇中心的误差,然后又计算每类簇新的中心,算出J,直到无法减少,也这是收敛,表示我们找到了最佳的簇中心用来分类。