这里写目录标题
一、sklearn中的降维算法
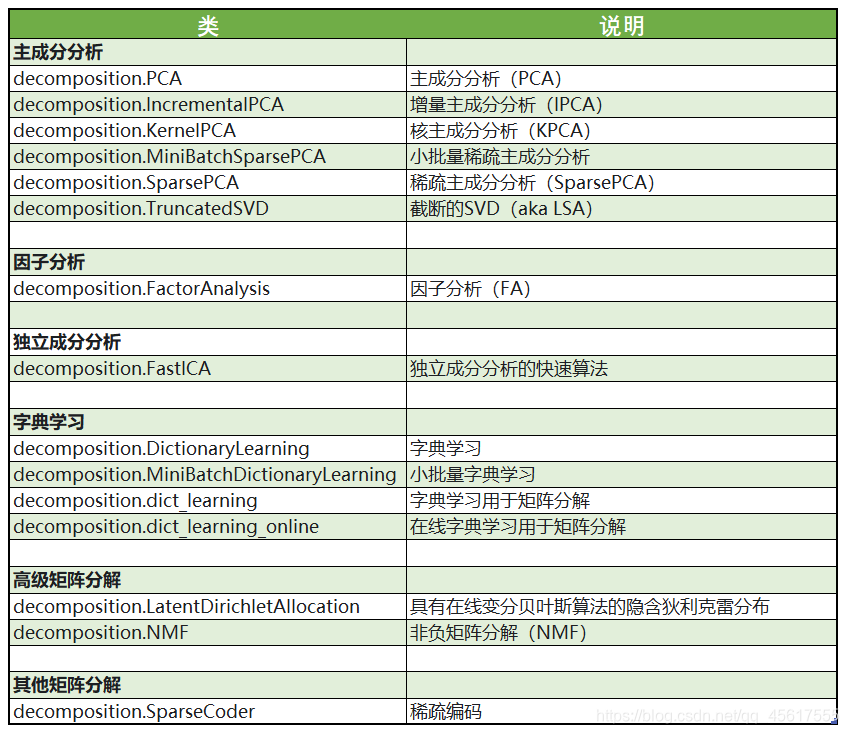
sklearn中降维算法都被包括在模块decomposition中,这个模块本质是一个矩阵分解模块。在过去的十年中,如果要讨论算法进步的先锋,矩阵分解可以说是独树一帜。矩阵分解可以用在降维,深度学习,聚类分析,数据预处理,低纬度特征学习,推荐系统,大数据分析等领域。
二、PCA与SVD
特征工程中有一种种重要的特征选择方法:方差过滤。如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同(比如90%都是1,只有10%是0,甚至100%是1),那这一个特征的取值对样本而言就没有区分度,这种特征就不带有有效信息。从方差的这种应用就可以推断出,如果一个特征的方差很大,则说明这个特征上带有大量的信息。
因此,在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。
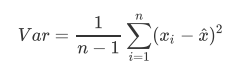
Var代表一个特征的方差,n代表样本量,xi代表一个特征中的每个样本取值,xhat代表这一列样本的均值。
2.1降维的实现

在步骤3当中,我们用来找出n个新特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。PCA和SVD是两种不同的降维算法,但他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的方法不同,信息量的衡量指标不同罢了。
1. PCA
PCA使用方差作为信息量的衡量指标,并且特征值分解来找出空间V。


2.SVD

3.PCA与特征选择技术的区别
- PCA是将已存在的特征进行压缩,降维完毕的的特征不是原来特征矩阵中的任何一种,而是特征的组合。
- 特征选择技术:从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性。
因此:可以想见,PCA一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标签之间的关系不具有意义。在线性回归模型中,我们使用特征选择。
三、sklearn代码实现
3.1PCA对鸢尾花数据集进行降维可视化
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
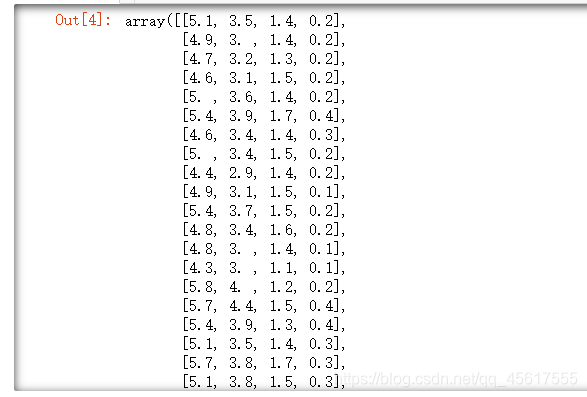
iris = load_iris()
X=iris.data
y=iris.target
X.shape
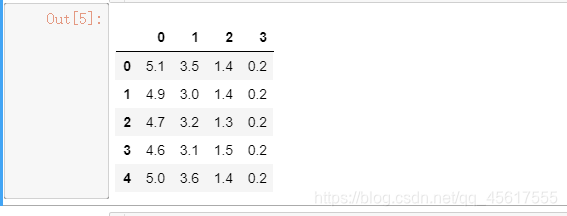
import pandas as pd
pd.DataFrame(X).head()
# 使用PCA降到两维
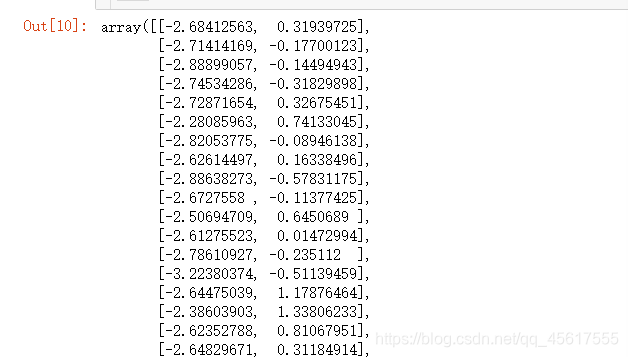
tr_X = PCA(2).fit_transform(X)
tr_X
color=['red','black','orange']
iris

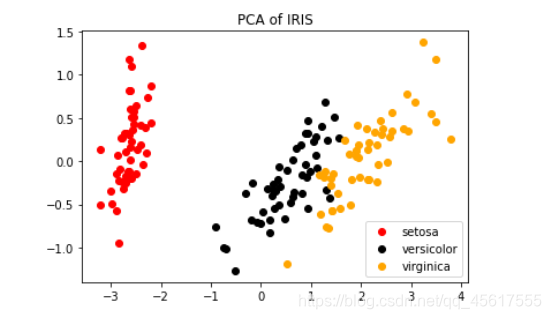
plt.figure()
for i in [0,1,2]:
plt.scatter(tr_X[y==i, 0]
, tr_X[y==i, 1]
, c=color[i]
, label=iris.target_names[i])
plt.legend()
plt.title('PCA of IRIS')
plt.show()
#属性explained_variance_,查看降维后每个新特征向量上所带的信息量大小(可解释性方差的大小)
pca.explained_variance_#查看方差是否从大到小排列,第一个最大,依次减小

#属性explained_variance_ratio,查看降维后每个新特征向量所占的信息量占原始数据总信息量的百分比
#又叫做可解释方差贡献率
pca.explained_variance_ratio_

import numpy as np
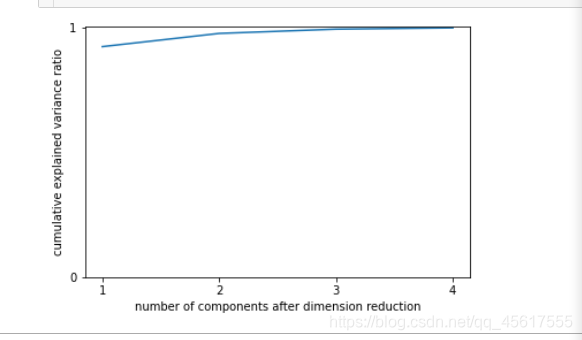
pca_line = PCA().fit(X)
# pca_line.explained_variance_ratio_#array([0.92461872, 0.05306648, 0.01710261, 0.00521218])
plt.plot([1,2,3,4],np.cumsum(pca_line.explained_variance_ratio_))
plt.xticks([1,2,3,4]) #这是为了限制坐标轴显示为整数
plt.yticks([0,1])
plt.xlabel("number of components after dimension reduction")
plt.ylabel("cumulative explained variance ratio")
plt.show()
3.2PCA降维后使用随机森林算法寻最优参数
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = pd.read_csv(r".\digit recognizor.csv")
X=data.iloc[:,1:]
y=data.iloc[:,0]
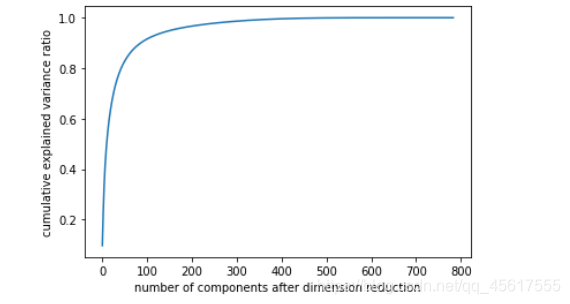
pca_line=PCA().fit(X)
print(pca_line.explained_variance_ratio_)
降维后的数据:

plt.figure()
plt.plot(np.cumsum(pca_line.explained_variance_ratio_))
plt.xlabel("number of components after dimension reduction")
plt.ylabel("cumulative explained variance ratio")
plt.show()
判断降到几维模型效果最好
score=[]
for i in range(1,101,10):
tr_X=PCA(i).fit_transform(X)
once = cross_val_score(RFC(n_estimators=10,random_state=0)
,tr_X,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,101,10),score)
plt.show()
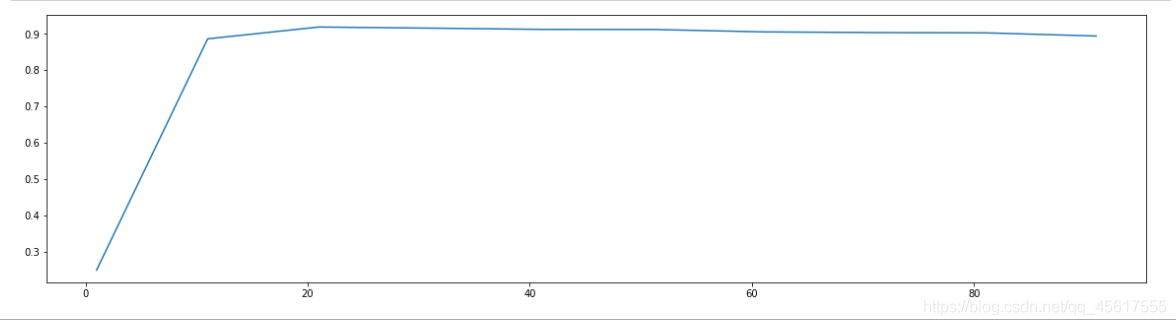
发现在10~25之间:
交叉验证方法!
score = []
for i in range(10,25):
X_dr = PCA(i).fit_transform(X)
once = cross_val_score(RFC(n_estimators=10,random_state=0),X_dr,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(10,25),score)
plt.show()
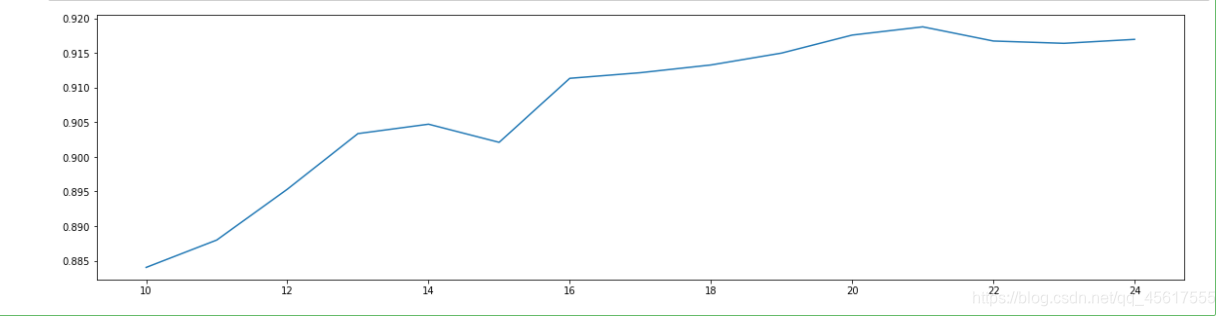
发现降维到25最好
X_dr = PCA(22).fit_transform(X)
#======【TIME WARNING:1mins 30s】======#
cross_val_score(RFC(n_estimators=100,random_state=0),X_dr,y,cv=5).mean()#0.946524472295366
3.3PCA降维后使用KNN寻最优参数
交叉验证的用法!
#======【TIME WARNING: 】======#
score = []
for i in range(10):
X_dr = PCA(22).fit_transform(X)
once = cross_val_score(KNN(i+1),X_dr,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(10),score)
plt.show()
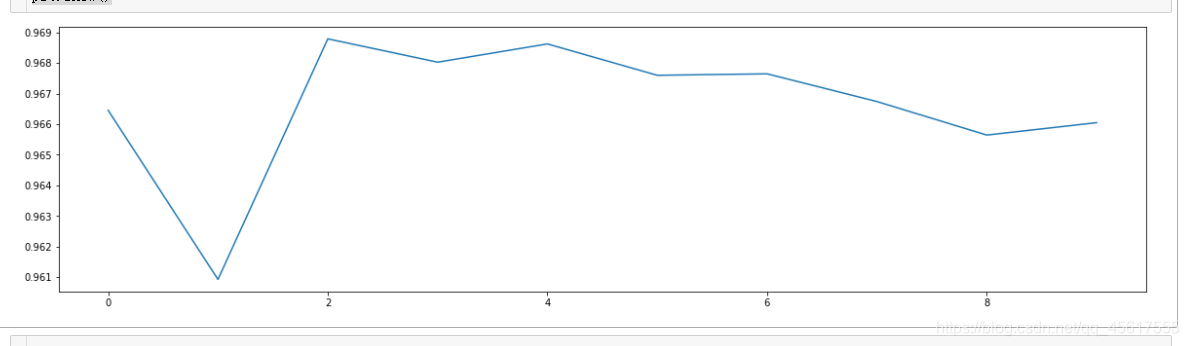
最优参数为2