文章目录
前言
在如今数据使用场景越来越多的环境下,如何对数据做到更准确,更高效的处理无疑是我们开发者所重点关注以及所期望达成的目标。说到数据的处理,在当今成熟的分布式系统下,我们已经能够达到比较高效的数据并行处理能力了。但是这并不意味着说对此我们没有别的改善空间的余地了。在数据的并行处理过程中,不是所有情况我们都能保证每个并行处理任务都能按照预期顺利执行,中间就可能出现长尾任务现象。这里笔者想抛出的一个关键词:数据切分。在数据切分不均匀的情况下,是极有可能出现任务执行时间不均等的现象,从而影响到整个Job的完成耗时。本文笔者以Hadoop DistCp任务的内部数据处理过程为例,来聊聊DistCp内部的数据切分方式。
基于文件数/文件Size的数据切分方式
在分布式计算过程中,我们有专门的名词来定义不同task处理数据量的差异,叫做data skew(数据倾斜)。在DistCp任务中,对应的情况就是其内部map task需要处理(拷贝)的数据量差异比较大。
在笔者内部测试的一个例子中,笔者打算拷贝300w量级的文件目录,最后发现将近200w的目录分布到了一个map task内,然后造成DistCp的结束不了的情况。后来经过进一步分析,才知道原来是DistCp默认按照数据拷贝大小来均分输入数据到各个map内。这种策略在拥有大规模目录的情况下不见得是适用的,因为目录是没有size的,可理解为其size为0。这样就可能出现目录扎堆聚集的情况。
在上面这种情况下,一种更为妥善的办法是根据数据输入文件数来做均衡,我们确保每个map task需要拷贝相同的一个文件数。不过这里可能又有人会说了,我们怎么保证这些文件中个别文件是超大文件的情况,DistCp拷贝这个超大文件耗时比一般的文件要多很长时间怎么办?
上面说的这种情况是有可能出现的,DistCp采用事前打散输入文件path的方式,来减小这种事情发生的概率,避免大size文件聚集在一个map task内的情况。然后再将打散后的文件按照先后顺序写成split文件后供map task处理。
此过程图如下所示:
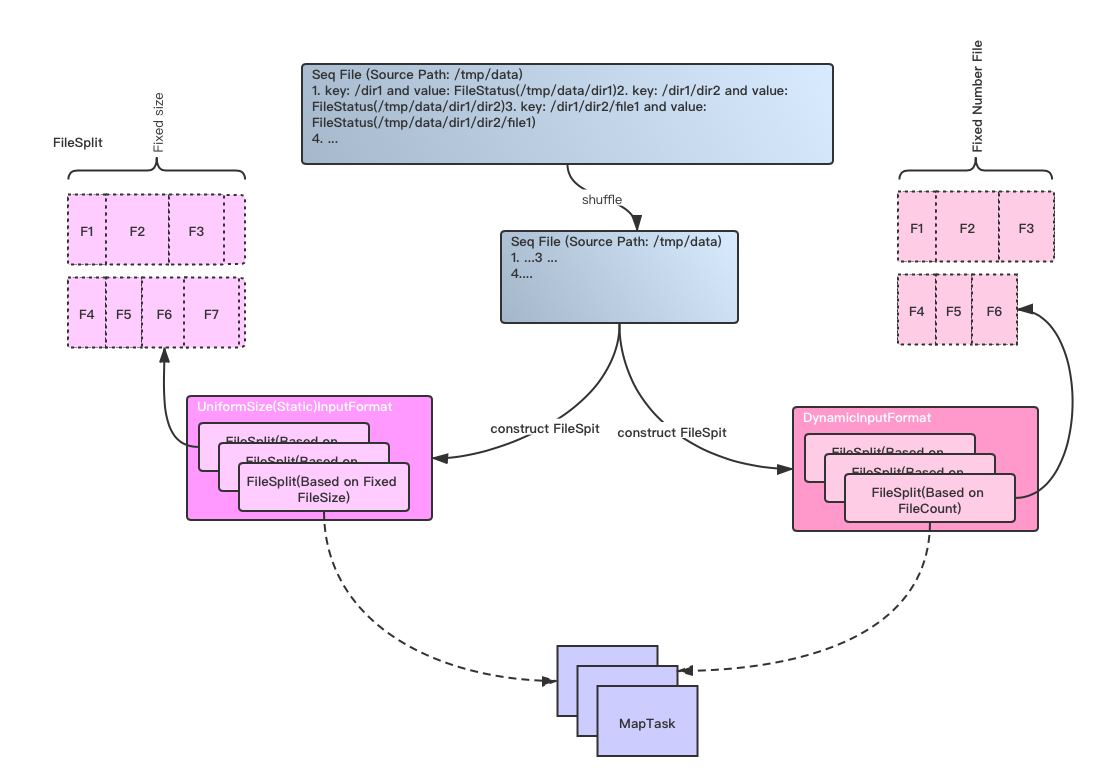
上面Seq File内部存储的一对对的K-V对,代表DistCp需要拷贝的目录/文件 path以及在目标FileSystem的全路径名。
上图左边显示的是基于固定文件总Size的Split处理,上图右边的则是基于文件数的Split处理。