前言:
伴随着音视频技术高速发展,直播行业异军突起,在社交、娱乐、电商、教育、医疗等领域高歌猛进。当下,5G和AI时代已至,音视频技术已经上升到一个全新的高度,新场景、新应用、新标准也必将出现。anyRTC紧跟时代的步伐,成立AI实验室,将自身的平台技术跟AI深度结合,全新架构了服务端和客户端音视频引擎-下一代音视频SDK以及下一代音视频引擎。那么全新的AI音视频实验室有哪些核心技术?又能在哪些场景下提供更优质的音视频服务呢?下面为大家简单的介绍一下;
本次文章将由以下几个方面展开:
- 音视频目前的发展趋势
- anyRTC成立AI实验室的初衷
- anyRTC AI实验室的功能
- 音视频功能场景化实施
- 总结
一、音视频目前的发展趋势
在年初的时候,我们经历了一场全球性的“战役”,但我们仍然心存希望,认为很快就会过去。而在接近年底的时候,我们依然在祈祷着疫情能够尽快结束,以便恢复我们往常的生活。事实上每年都会有大事件发生,但却从未像2020年这般贯穿始终过。可以说我们经历了绝对不平凡的一年。
因为今年疫情的影响所有的办公、教育、娱乐、都转战到了线上。学生们开始在网上上课,大人们开始在家办公,会议变成了视频会议,面试也变成了线上面试。正是因为如此所以“音视频”这三个字也让广大的群众熟悉了起来。
而且随着5G的来临,传输更高速、资费更便宜、耗电发热更低,会彻底改变即时通讯的“带宽”,带来高可靠超低延时的通讯体验。这让视频这种社交媒介有了具备普及的基础要求。也给超高清视频和虚拟现实技术的应用铺平了道路。
随着音视频市场的蓬勃发展,anyRTC也在不断提升自己在音视频领域的核心竞争力。在5G和AI双重的发展下,anyRTC提出了anyRTC音视频实验室,目的是为了让音视频的交付更加简单,下面为大家简单介绍一下;
二、anyRTC成立AI实验室的初衷
如今的音视频需求,已经不再是实现功能即可,更多的是要求是服务质量、个性化需求。传统的技术已经很难有大的优化空间,所以anyRTC在2019年初成立了AI实验室,专门负责AI在音视频中的应用,我们从采集(美颜滤镜)到传输(智能传输)以及到渲染(图像增强、音频降噪)深度结合了AI技术。我们时刻秉承着“让音频交付更简单”的理念,造福开发者,为开发者提供更加便捷、易用、专业的音视频服务。
三、anyRTC AI实验室的功能
anyRTC AI实验室包含以下3个模块:SD-RTN模块、音频处理模块、视频处理模块,下面就分别介绍一下3个模块的功能点和优势:
1、SD-RTN全球实时传输网
SD-RTN(Software Defined Real-time Network) 软件定义实时网,专为双向实时音视频互动而设计。超高清音视频的传输需要稳定的网络和充足的带宽,任何的网络波动都会对音视频质量造成影响。在实时通讯的场景下,如何高速地检测网络状态并根据网络状态制定合适的抗性和传输策略,一直是学术界和业界的难题。我们的团队具有丰富的学术界和业界经验,为此提供了能适应各种复杂场景的高品质高可靠性的解决方案。

功能点
- 拥塞控制
基于延迟和丢包拥塞控制算法,结合我们丰富的网络状态数据库,提出了新的实时拥塞控制算法,在不同网络场景下都能迅速给出可靠的带宽预测。
- 损伤抗性
互联网网络不稳定因素有很多,我们的智能抗性算法可以在极低的延时下抵御住各种突发性的网络波动及网络损伤,将有限资源的能力最大化,确保优质的播放体验。
- QoS/QoE最优化
在网络带宽受限的情况下,清晰度、流畅性和延时不可兼得。我们根据应用的上下文和网络状态,实时自动做出最优的取舍,让最终用户能获得最好的体验。
- 多人通讯流控
多人通讯环境,既要保证重要通话的清晰度,又要兼顾他人的体验。我们使用了两套策略:在决策空间有限的情况下使用人工智能进行流控;在更复杂的场景下提供基于主观体验调整策略。
- 网络度量
网络策略的制定离不开现网大量数据支持。我们有丰富的去隐私数据集用来提取和学习网络的状态,可以在离线场景下复现差网状态,与在线场景下迅速判断网络状态。
- 动态路由
网络状态变化多端,跨运营商、跨区域、跨国等多重复杂网络环境,需要实时对网络状况进行检测和调整;基于实时状态数据进行分析和计算,获取最优的传输线路。
SD-RTN的优势
| 高延时传输方案 | SD-RTN |
|---|---|
| 端到端单向延时 > 1s | 端到端单向延时 < 400ms |
| 基于 TCP 协议,延时不可控 | 基于 UDP 协议,延时可控 |
| 抗丢包能力差,在丢包 2% 时明显卡顿,达到 30% 可能断开连接 | 通过定制具有超强抗丢包能力,80% 丢包率也可通话 |
| 层层缓存,就近下发 | 基于自定义路由,选择最优传输路径,实时端到端传输 |
| 适用于单向直播、视频点播等无互动需求场景 | 适用于互动课堂、互动直播、音视频社交、游戏对讲等对实时互动高需求场景 |
SD-RTN是一种可承载任何点到点(peer-to-peer)实时数据传输需求的业务架构:只要调用开放的API,无论是实时视频(会议、教育、直播、社交、监控、VR)、文件传输(短视频、办公)还是高速数据同步(游戏、AI、IOT、物联网)都可以很方便的接入SD-RTN的实时数据传输云服务。
2、音频处理模块
核心技术效果对应与试听
智能语音增强解决方案,集成了AI智能降噪、回声消除、混响消除、自动增益等核心技术。该方案创新性地应用深度学习技术,实时分离语音和背景噪声,清晰提取人声,有效消除环境中的各类噪音,让用户畅享更清晰高效的在线音视频通话体验。
anyRTC自19年初成立AI实验室以来,经过长达一年多的时间,收集公开语音数据资源,以及第三方提供的数据和自己的内部会议来训练AI模型。噪音抑制功能将分析用户的音频输入,并使用经过特殊训练的深度神经网络来减少背景声音,例如键盘的敲击声、风扇产生的噪音等。目前我们anyRTC已经配备了全套工具和环境,我们现在已经自己采集了很多数据集,并且应用到了我们AI算法中。下面就是我们anyRTC在AI音频模型中取得的成就:
-
智能降噪:基于计算听觉场景分析理论,应用深度学习技术,能够在不依赖任何硬件的基础上,实现将人声和噪音分离,有效抑制环境中的各种噪音。
-
DHS深度啸叫抑制:基于深度学习技术,智能阻断声反馈回路,抑制啸叫产生。有效解决实时游戏、在线会议等多人实时通话场景下啸叫问题。
点击视频查看看效果
智能降噪演示场景
啸叫抑制演示场景
anyRTC AI 降噪技术规划的关键策略包括音频通信核心体验、声音场景分类和处理、音频痛点难点问题及差异化体验,最终目标则是提升语音可懂度、自然度、舒适度。
3、视频处理模块
核心技术
最高支持 1080P,分辨率、码率可自由切换,融合多种领先的视频编码处理算法,画质更好、码率更低,支持移动端实时超分,实现低分辨率视频到高分辨率视频的实时重建,全面提升源视频画质和分辨率。AI 辅助功能:支持实时暗光增强算法,即使在较暗的环境下,也能提供清晰、明亮的图像。

anyRTC在其他领域也有所涉及:AI 智能传输,超分辨率,智能插帧,图像增强等。
- AI智能传输
由于网络传输线路上有丢包,接收的数据有失真,所以 AI 智能传输被用来做算法补偿,提升传输质量。
- 超分辨率
实时通信视频在接收端提高原有图像的分辨率,得到高分辨率的图像,该功能有效减少了网络传输带宽,为移动端为用户带来极致视频体验。
- 智能插帧
智能插帧是通过运动估算,计算出画面中物体的运动轨迹,生成新的帧来进行插补。可以将普通常见的30fps进行智能插帧计算,可以获得60fps的顺滑视频,让眼睛看到的自然形象更为自然。
- 图像增强
图象增强是数字图象处理常用的技术之一。图象增强技术的目的是为了改进图象的质量,以达到赏心悦目的效果。通常要完成的工作是除去图象中的噪声,使边缘清晰以及突出图象中的某些性质等。
四、音视频功能场景化实施
以上就是anyRTC-AI实验室的功能介绍。最后一起来看一下这些功能在实际场景中的应用,毕竟再好的技术也是要放在最适合他使用的场景中才能发挥最大的效果。
1、在线合唱
在线合唱与以往的合唱不同,以往的合唱都是用户开启合唱功能之后先一个人和伴奏演唱,完成之后上传,其他用户可以使用这个已经有人声的伴奏再唱一遍,实现“合唱”,而我们要做到的合唱是两位用户同时在线唱歌,合唱的伴奏是同时通过网络发送给两位歌手的,而且两位歌手在演唱的同时可以听到彼此的声音。
- 第一,合唱场景下对延迟要求是很高的,所以整体的低延迟、QoS 的能力在这个场景里面得到了很明确的体现,包括可以明确知道这个效果好还是不好;
- 第二,对于音质的要求很高,大家听音乐肯定不希望语音效果是很差的,这是不能接受的。所以我们的高音质能力,包括 AI降噪能力都在这个场景中得到了应用和实践;
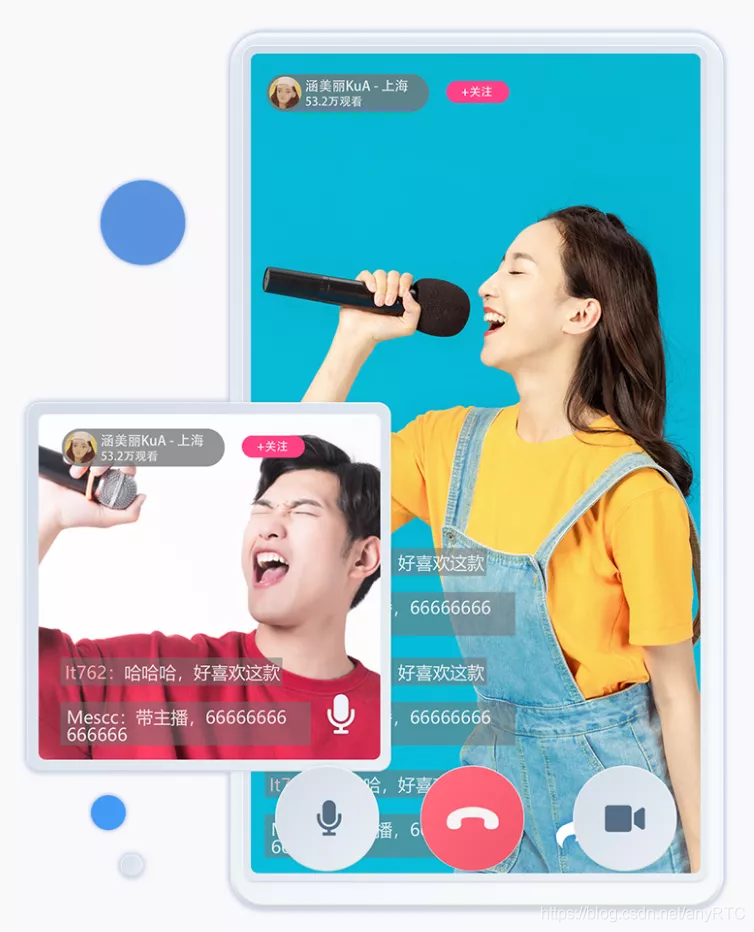
2、主播PK
主播PK就是一个主播在直播时,可以对另一个直播间的主播发起挑战。一旦挑战接受,让两个直播间的主播就开始进行连麦互动,直播界面一分为二,同时显示两个主播的画面,两方粉丝也会进入到同一个直播间中。
一般直播场景里,同一个直播频道,或者说同一个直播间里的主播与用户是可以进行连麦互动的。而主播之间的PK互动,其实是一种跨直播间连麦。主播PK经常遇到的问题就是两个主播之间延迟比较高,会影响到观众的观看体验,而anyRTC使用的旁路推流模式,可以最高限度的降低延迟,主播端直接推流,减少了传输过程中的延迟损耗。
- 该场景对视频质量的要求比较高,anyRTC新一代自研高清视频编码和视频 AI 超分能力也在这个场景得到充分应用;

3、语音聊天室
语音聊天室属于多人聊天的一种,通常为6-8人一个频道,玩家可以自由上麦发言,也可以创建子频道私聊,观众人数不限。
语音聊天室适用于多人聊天,狼人杀,语音开黑等场景。
- 在语音聊天的场景中,因为大多数情况下大家都没有办法保证在一个安静的环境的进行聊天,所以 AI
降噪和智能回声消除的能力就为语音聊天提供了高质量的音频效果; - QoS 抗弱网和去抖动能力,则保证了聊天室内多人同时上麦后的网络稳定性;
五、总结
anyRTC下一代实时音视频SDK引擎已深度结合AI,全新架构支持百亿级并发,对于anyRTC来说,AI实验室只是在人工智能领域研究的冰山一角,后续我们会逐步推出更多关于AI技术的应用,挖掘更多的应用场景,为广大开发者朋友们提供最专业的服务。