前言
在多集群模式下,为了保证数据的一定冗余性要求,我们有时会跨集群或跨data center去备份一些重要的数据。这样可以避免某天一旦一个cluster或者data center处于不可用状态时,从而影响集群正常的数据服务。如果在不额外实现此功能代码的情况下,我们可以采用简单直接的Distcp工具来做集群间的数据拷贝。不过这种方式无法做到实时的数据replication,我们可以按照实际的使用场景做到一天同步一次或者小时级别的同步。不过本文笔者要介绍与此相关的一个重要的ViewFs的新特性:Nfly link模式。
Nfly link模式的由来
社区在JIRA HADOOP-12077:Provide a multi-URI replication Inode for ViewFs 中提出了在ViewFs模式下能够通过多uri地址的方式做跨集群的replication。而这里提到的multi-URL mount point link即Nfly模式,这里的N指的是N个data center。
在社区JIRA里,将数据冗余备份在不同的data center(cluster)里,保持high availability是一方面,可以到时出问题时应以可以做failover到下一个URI地址读写数据。另外一方面,它还能够减少用户application的迁移可能带来的影响。比如用户的application原本运行在cluster1上,它会优先于读取cluster1上的C数据。但是当某一天,这个用户的application migration到cluster2上后,这个时候它则会优先读取cluster2上的数据了。这里其实就避免了跨集群读取数据的过程了,概括来说,多集群备份数据还具有data access locality的好处。
OK,下面我们来深入地了解下ViewFs Nfly模式的实现细节部分的内容。
Nfly link实现细节分析
Nfly link在实现上属于ViewFs的一种新的mount point类型,相比较原始mount point 一个path对一个single cluster地址的方式,Nfly则是对应对个地址,类似如下配置所示:
<property>
<name>fs.viewfs.mounttable.global.linkNfly../ads</name>
<value>uri1,uri2,uri3</value>
</property>
实际样例配置如下:
<property>
<name>fs.viewfs.mounttable.global.linkNfly.minReplication=3,readMostRecent=true,repairOnRead=false./ads</name>
<value>hdfs://datacenter-east/ads,hdfs://datacenter-west/ads,s3a://models-us-west/ads,file:/tmp/ads</value>
</property>
其次如上所示,在Nfly内部实现中,还能够支持下列特殊属性要求:
- minReplication,最少副本数要求,replication出去的文件要达到规定成功的数量才能算写成功文件。
- readMostRecent,读文件时选取一个最近一次被更改的文件数据。
- repairOnRead,如果副本间的数据状态不一致,则在读操作的时候做检查并进行恢复(从其它健康的副本数据拷贝覆盖掉stale的那个副本数据)。
- 如果不考虑上述read属性,Nfly模式在读文件操作时会返回client一个最closest的副本数据,根据传入topology位置来做。
注意上面提到的副本和replication指的是夸集群location的replication,副本,可不是单集群内的。
当Nfly模式从开始写一个文件到最后文件关闭的时候,它基于的流程如下图所示:
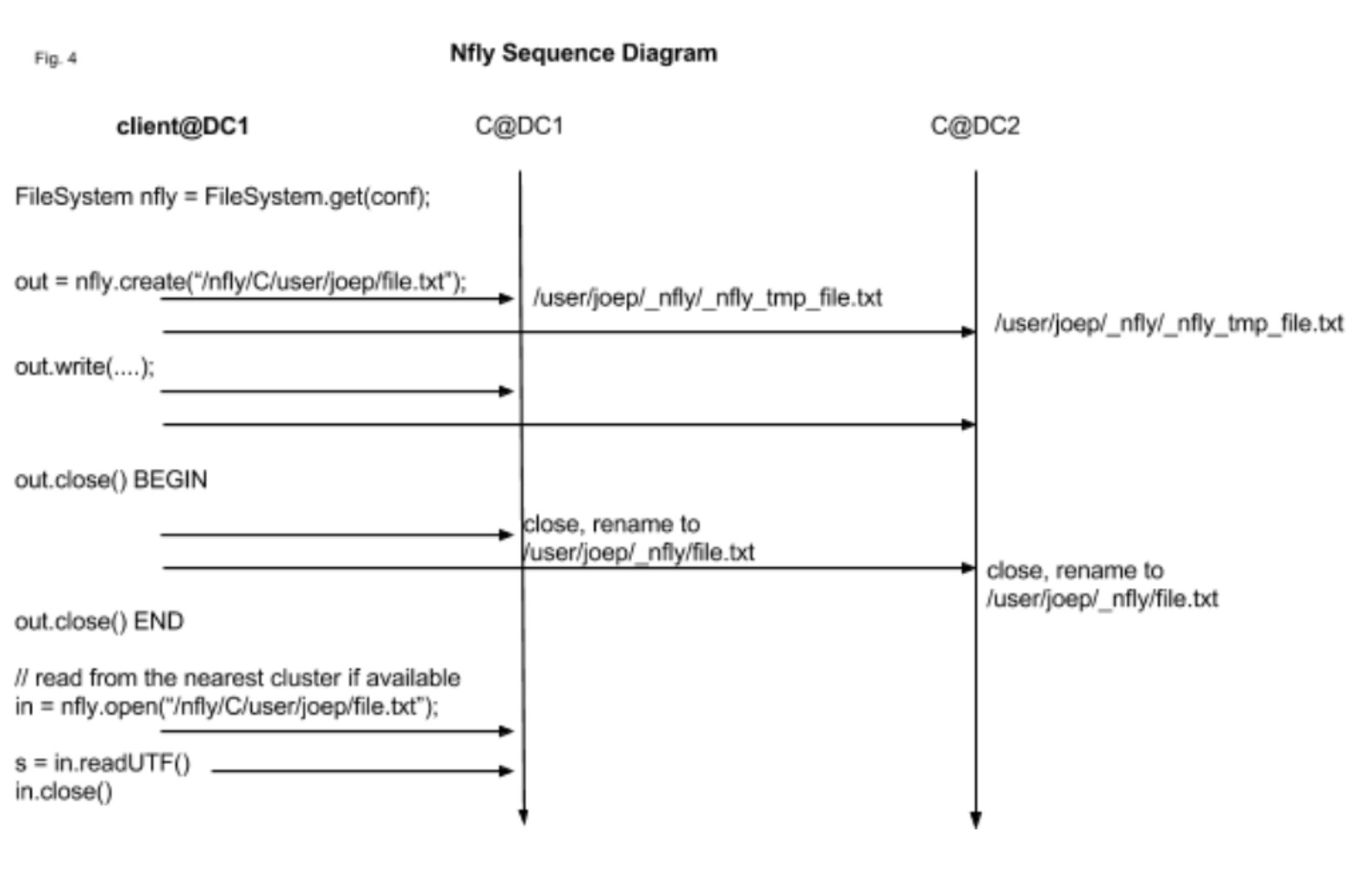
上述C@DC1和C@DC2代表不同集群地址。

1)第一步,会创建对应不同集群的FSOutputStream实例对象,创建BitSet来记录每个FSOutputStream的数据写出情况,为了做后面minReplication判断用。
2)创建nfly tmp文件路径为临时写出路径,后续的数据写出都是先写到这个带有nfly tmp标识的路径下。
3)每次执行数据写出操作时,依次遍历写出数据到上述FSOutputStream中去,如果失败了则标记BitSet对应为false。
4) 关闭文件时,如果发现BitSet中记录的成功数达到minReplication时,则进行nfly tmp路径的rename操作,rename成最后的原目录路径名称。随后统一这些replication file的last modified time。否则,删除nfly tmp临时文件,意为这次写过程失败了。这个阶段为Nfly写过程的commit阶段。
相关代码如下:
private final class NflyOutputStream extends OutputStream {
// 实际路径,最终需要rename成的路径
private final Path nflyPath;
// 临时路径
private final Path tmpPath;
// broadcast set
private final FSDataOutputStream[] outputStreams;
// status set: 1 working, 0 problem
private final BitSet opSet;
private final boolean useOverwrite;
private NflyOutputStream(Path f, FsPermission permission, boolean overwrite,
int bufferSize, short replication, long blockSize,
Progressable progress) throws IOException {
nflyPath = f;
tmpPath = getNflyTmpPath(f);
// 初始化多个FSDataOutputStream,每个FSDataOutputStream对应所属独立的集群地址
outputStreams = new FSDataOutputStream[nodes.length];
for (int i = 0; i < outputStreams.length; i++) {
outputStreams[i] = nodes[i].fs.create(tmpPath, permission, true,
bufferSize, replication, blockSize, progress);
}
// BitSet用来标记写数据是否写成功的标记位
opSet = new BitSet(outputStreams.length);
opSet.set(0, outputStreams.length);
useOverwrite = false;
}
其中的write方法如下所示:
@Override
public void write(byte[] bytes, int offset, int len) throws IOException {
final List<IOException> ioExceptions = new ArrayList<IOException>();
// 遍历outputStreams,进行数据的写出
for (int i = opSet.nextSetBit(0);
i >= 0;
i = opSet.nextSetBit(i + 1)) {
try {
outputStreams[i].write(bytes, offset, len);
} catch (Throwable t) {
// 写第i个outputStreams过程出错,则进行此位置下标BitSet的重置
osException(i, "write", t, ioExceptions);
}
}
// 这期间如果已经达不到最小副本数要求,则抛出IO异常
mayThrow(ioExceptions);
}
close/commit阶段过程的代码:
@Override
public void close() throws IOException {
final List<IOException> ioExceptions = new ArrayList<IOException>();
for (int i = opSet.nextSetBit(0);
i >= 0;
i = opSet.nextSetBit(i + 1)) {
try {
outputStreams[i].close();
} catch (Throwable t) {
osException(i, "close", t, ioExceptions);
}
}
// 如果close后,没有达到最小副本数要求,则清理nfly tmp文件
if (opSet.cardinality() < minReplication) {
cleanupAllTmpFiles();
throw new IOException("Failed to sufficiently replicate: min="
+ minReplication + " actual=" + opSet.cardinality());
} else {
// 如果达到最小副本要求,则进行rename操作
commit();
}
}
private void cleanupAllTmpFiles() throws IOException {
for (int i = 0; i < outputStreams.length; i++) {
try {
nodes[i].fs.delete(tmpPath);
} catch (Throwable t) {
processThrowable(nodes[i], "delete", t, null, tmpPath);
}
}
}
private void commit() throws IOException {
final List<IOException> ioExceptions = new ArrayList<IOException>();
for (int i = opSet.nextSetBit(0);
i >= 0;
i = opSet.nextSetBit(i + 1)) {
final NflyNode nflyNode = nodes[i];
try {
// 是否需要overwrite
if (useOverwrite) {
nflyNode.fs.delete(nflyPath);
}
// 进行rename操作
nflyNode.fs.rename(tmpPath, nflyPath);
} catch (Throwable t) {
osException(i, "commit", t, ioExceptions);
}
}
if (opSet.cardinality() < minReplication) {
// cleanup should be done outside. If rename failed, it's unlikely that
// delete will work either. It's the same kind of metadata-only op
//
throw MultipleIOException.createIOException(ioExceptions);
}
// 获取当前时间作为这些 replication file的last modified time
final long commitTime = System.currentTimeMillis();
for (int i = opSet.nextSetBit(0);
i >= 0;
i = opSet.nextSetBit(i + 1)) {
try {
nodes[i].fs.setTimes(nflyPath, commitTime, commitTime);
} catch (Throwable t) {
LOG.info("Failed to set timestamp: " + nodes[i] + " " + nflyPath);
}
}
}
}
readMostRecent相关代码如下:
public FSDataInputStream open(Path f, int bufferSize) throws IOException {
// TODO proxy stream for reads
final List<IOException> ioExceptions =
new ArrayList<IOException>(nodes.length);
int numNotFounds = 0;
final MRNflyNode[] mrNodes = workSet();
// naively iterate until one can be opened
...
// 如果指定了readMostRecent,则会进行last modified time的排序
// 未指定则会按照topology distance排序,
if (nflyFlags.contains(NflyKey.readMostRecent)) {
// sort from most recent to least recent
Arrays.sort(mrNodes);
}
final FSDataInputStream fsdisAfterRepair = repairAndOpen(mrNodes, f,
bufferSize);
if (fsdisAfterRepair != null) {
return fsdisAfterRepair;
}
mayThrowFileNotFound(ioExceptions, numNotFounds);
throw MultipleIOException.createIOException(ioExceptions);
}
上述只是部分代码的细节,更多细节可以阅读源码相关类NflyFSystem。
引用
[1].https://issues.apache.org/jira/browse/HADOOP-12077
[2].https://blog.twitter.com/engineering/en_us/a/2015/hadoop-filesystem-at-twitter.html