Scrapy作为一个优秀的爬虫框架,尽管其体系已相当成熟,但实际操作中其实还是需要借助其他插件的力量来完成某些网站的爬取工作,今天记录一下博主爬虫路上的一些坑及解决方案,避免大家走太多弯路。
一、DEBUG: Filtered duplicate request: GET xxx - no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates)
对网站全站爬取数据时,遇到了这个报错。
Scrapy会对request的URL去重(RFPDupeFilter),需要在scrapy.Request方法中传递多一个参数,dont_filter=True。
# 示例
yield scrapy.Request(url=self.urlList[self.urlIndex], callback=self.parse, dont_filter=True)
二、多个爬虫集成selenium
如果你看过我上一篇Scrapy博文,就知道我是如何将selenium集成到Scrapy中。
其实,正确的做法,是需要将ChromeDriver的配置,转移到middlewares中,不然如果按照我上一篇博文那么去写,将其配置写在具体的各个蜘蛛里的话,先是会导致代码冗余,关键是还会导致启动一个蜘蛛的时候,会启动多个ChromeDriver。
三、关于ChromeDriver的配置细则
直接上代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") # 无头(静默)模式
chrome_options.add_argument("--disable-gpu") # 禁用GPU加速
chrome_options.add_experimental_option('prefs', {
"profile.managed_default_content_settings.images": 2}) # 非headless模式下不加载图片
chrome_options.add_argument('blink-settings=imagesEnabled=false') # headless模式下不加载图片
driver = webdriver.Chrome(chrome_options=chrome_options)
# 浏览器静默模式下,最大化窗口是无效的 driver.maximize_window()
driver.set_window_size(1920, 1080) # 设置浏览器窗口大小
某些网站对不同的分辨率所展示的内容不一,所以最好在同一的分辨率下去抓取网页,设置driver浏览器窗口的方法有两个driver.maximize_window()和driver.set_window_size(1920, 1080),需要注意的是maximize_window在headless模式下无效,所以推荐使用set_window_size。
四、反爬虫进阶
往往某些网站,会配置反爬虫机制,诸如换USER_AGENTS换IP这些已经烂大街的操作我在这里就不提及了。
使用过selenium爬虫的人,都知道其实就算使用了模拟浏览器去访问某些网站,还是会被认定为爬虫做验证码拦截,而往往这个时候,你就算人工去做验证操作,网页往往还是一动不动,为什么?这里先推荐一个B站的视频给大家稍微科普一下。
被拦截的示例如下:

这是因为你所启动的浏览器,仍有太多你看不见的爬虫特征。这里给大家推荐一个冷门的插件selenium-stealth,这款插件可以集成selenium抹去ChromeDriver上的蜘蛛痕迹。
至于插件的原理,建议感兴趣的再自行研究stealth.min.js这个东西。
示例使用代码如下:
from selenium_stealth import stealth
chrome_options = Options()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(chrome_options=chrome_options)
stealth(driver,
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
可以结合上边的代码添加Options配置。
顺带提一点,使用headless模式跟stealth插件后,会导致ajax异步加载数据的网站,load不出来数据,原因不详,建议爬取这种网站的时候,如果该网站没有什么验证,可以将stealth关闭,或者关闭无头模式爬取。
五、绕过CloudFlare
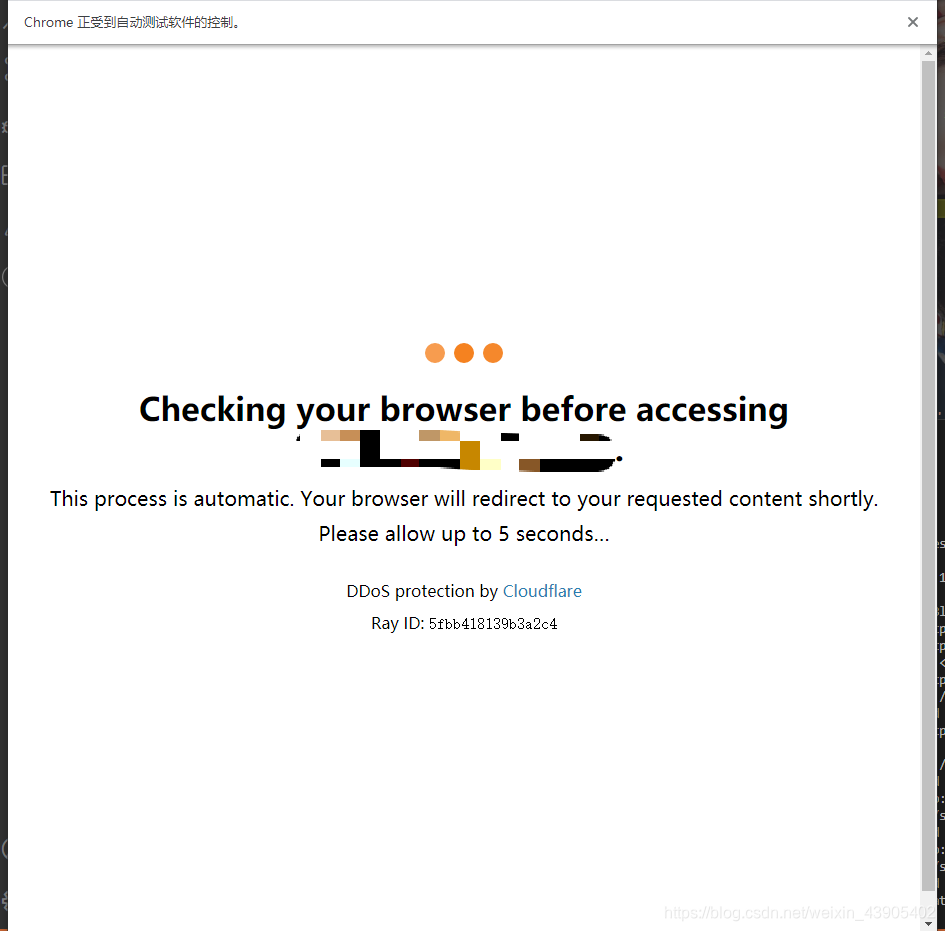
相信大家做爬虫的,对五秒盾CloudFlare并不陌生,至于如何去绕过五秒盾的检测,推荐大伙一个插件cloudflare-scrape,专门用于绕过CloudFlare。
实际操作流程请自行查看文档,可以拿这个网站练练手wallhere。
不过实际操作中,有些网站就算用了这个插件也绕不过,比如博主想要爬取的网站就绕不过五秒盾,作为爬虫菜鸡,博主也不深究当场放弃(其他绕行方式不会)。
总结
这个世界上奇葩的网站多得是,遇到过令人作呕的商品具有六种格式的价格形式的;也遇到过网站禁用了js,用不了xpath的;还遇到过无限滚动加载,一个页面几千个DOM导致ChromeDriver假死的…
不扯淡了,路还很长,Keep learning…