非原创
本文转自https://github.com/a415432669/-front_end_notebook/tree/master/Node/day6/%E6%96%87%E6%A1%A3
(随机生成,随机值根据时间+加密后生成编码)-------woff结尾文件(知道什么编码对应什么图片,存放密钥)---->9
用卷积公式判断两个文件重复率超过百分之多少就算两个相同
示例表数据
假设有一个名为employee的员工表,它有九个属性:id(员工编号)、name(员工名称)、mobile(电话)、zip(邮编)、province(省份)、city(城市)、district(区县)、deptNo(所属部门编号)、deptName(所属部门名称)、表总数据如下:
| id | name | mobile | zip | province | city | district | deptNo | deptName |
|---|---|---|---|---|---|---|---|---|
| 101 | 张三 | 13910000001 13910000002 |
100001 | 北京 | 北京 | 海淀区 | D1 | 部门1 |
| 101 | 张三 | 13910000001 13910000002 |
100001 | 北京 | 北京 | 海淀区 | D2 | 部门2 |
| 102 | 李四 | 13910000003 | 200001 | 上海 | 上海 | 静安区 | D3 | 部门3 |
| 103 | 王五 | 13910000004 | 510001 | 广东省 | 广州 | 白云区 | D4 | 部门4 |
| 103 | 王五 | 13910000004 | 510001 | 广东省 | 广州 | 白云区 | D5 | 部门 5 |
由于此员工表是非规范化的,我们将面对如下的问题。
- 修改异常:上表中张三有两条记录,因为他隶属于两个部门。如果我们要修改张三的地址,必修修改两行记录。假如一个部门得到了张三的新地址并进行了更新,而另一个部门没有,那么此时张三在表中会存在两个不同的地址,导致了数据不一致
- 新增异常:假如一个新员工假如公司,他正处于入职培训阶段,还没有被正式分配到某个部门,如果
deptNo字段不允许为空,我们就无法向employee表中新增该员工的数据。- 删除异常:假设公司撤销了D3部门,那么在删除
deptNo为D3的行时,会将李四的信息也一并删除。因为他隶属于D3这一部门。
范式主要是将每个表功能独立化,简洁,更好表达他们之间的关系
第一范式(1NF)
表中的列只能含有原子性(不可再分)的值。
表中的张三有两个手机号存储在mobile列中,违反了 1NF 规则。为了使表满足 1NF,数据应该修改如下:
| id | name | mobile | zip | province | city | district | deptNo | deptName |
|---|---|---|---|---|---|---|---|---|
| 101 | 张三 | 13910000001 | 100001 | 北京 | 北京 | 海淀区 | D1 | 部门1 |
| 101 | 张三 | 13910000002 | 100001 | 北京 | 北京 | 海淀区 | D1 | 部门1 |
| 101 | 张三 | 13910000001 | 100001 | 北京 | 北京 | 海淀区 | D2 | 部门2 |
| 101 | 张三 | 13910000002 | 100001 | 北京 | 北京 | 海淀区 | D2 | 部门2 |
| 102 | 李四 | 13910000003 | 200001 | 上海 | 上海 | 静安区 | D3 | 部门3 |
| 103 | 王五 | 13910000004 | 510001 | 广东省 | 广州 | 白云区 | D4 | 部门4 |
| 103 | 王五 | 13910000004 | 510001 | 广东省 | 广州 | 白云区 | D5 | 部门 5 |
第二范式(2NF)
第二范式要同时满足下面两个条件
- 满足第一范式
- 没有部分依赖
例如,员工表的一个候选键是{id,mobile,deptNo},而deptName依赖于deptNo,同样 name 依赖于 id,因此不是 2NF的。为了满足第二范式的条件,需要将这个表拆分成employee、dept、employee_dept、employee_mobile四个表。如下:
员工表 employee
| id | name | zip | province | city | district |
|---|---|---|---|---|---|
| 101 | 张三 | 100001 | 北京 | 北京 | 海淀区 |
| 102 | 李四 | 200001 | 上海 | 上海 | 静安区 |
| 103 | 王五 | 510001 | 广东省 | 广州 | 白云区 |
部门表 dept
| deptNo | deptName |
|---|---|
| D1 | 部门1 |
| D2 | 部门2 |
| D3 | 部门3 |
| D4 | 部门4 |
| D5 | 部门5 |
员工部门关系表 employee_dept
| id | deptNo |
|---|---|
| 101 | D1 |
| 101 | D2 |
| 102 | D3 |
| 103 | D4 |
| 104 | D5 |
员工电话表 employee_mobile
| id | mobile |
|---|---|
| 101 | 13910000001 |
| 101 | 13910000002 |
| 102 | 13910000003 |
| 103 | 13910000004 |
第三范式(3NF)
第三范式要同时满足下面两个条件
- 满足第二范式
- 没有传递依赖
例如,员工表的province、city、district依赖于zip,而zip依赖于id,换句话说,province、city、district传递依赖于id,违反了 3NF 规则。为了满足第三范式的条件,可以将这个表拆分成employee和zip两个表,如下
employee
| id | name | zip |
|---|---|---|
| 101 | 张三 | 100001 |
| 102 | 李四 | 200001 |
| 103 | 王五 | 510001 |
地区表area
| zip | province | city | district |
|---|---|---|---|
| 100001 | 北京 | 北京 | 海淀区 |
| 200001 | 上海 | 上海 | 静安区 |
| 51000 | 广东省 | 广州 | 白云区 |
在关系数据库模型设计中,一般需要满足第三范式的要求。如果一个表具有良好的主外键设计,就应该是满足3NF的表。规范化带来的好处是通过减少数据冗余提高更新数据的效率,同时保证数据完整性。然而,我们在实际应用中也要防止过度规范化的问题。规范化程度越高,划分的表就越多,在查询数据时越有可能使用表连接操作。而如果连接的表过多,会影响查询性能。关键的问题是要依据业务需求,仔细权衡数据查询和数据更新关系,指定最合适的规范化程度。不要为了遵循严格的规范化规则而修改业务需求
数据库一对一、一对多、多对多设计
数据库实体间有三种对应关系:一对一、一对多、多对多
一对一关系示例:
一个学生对应一个学生档案材料 每个人都有唯一的身份证号
一对多关系示例:(两张表可以建立关系)
一个学生只属于一个班,但这个班有多名学生
多对多关系示例:(三张表)
一个学生可以选择多门课,一门课也可以有多名学生
一个人可以有多个角色,一个角色可以有多个人
一、一对多关系处理

设计数据库表:只需在 学生表 中多添加一个班级号的ID即可
二、多对多关系处理

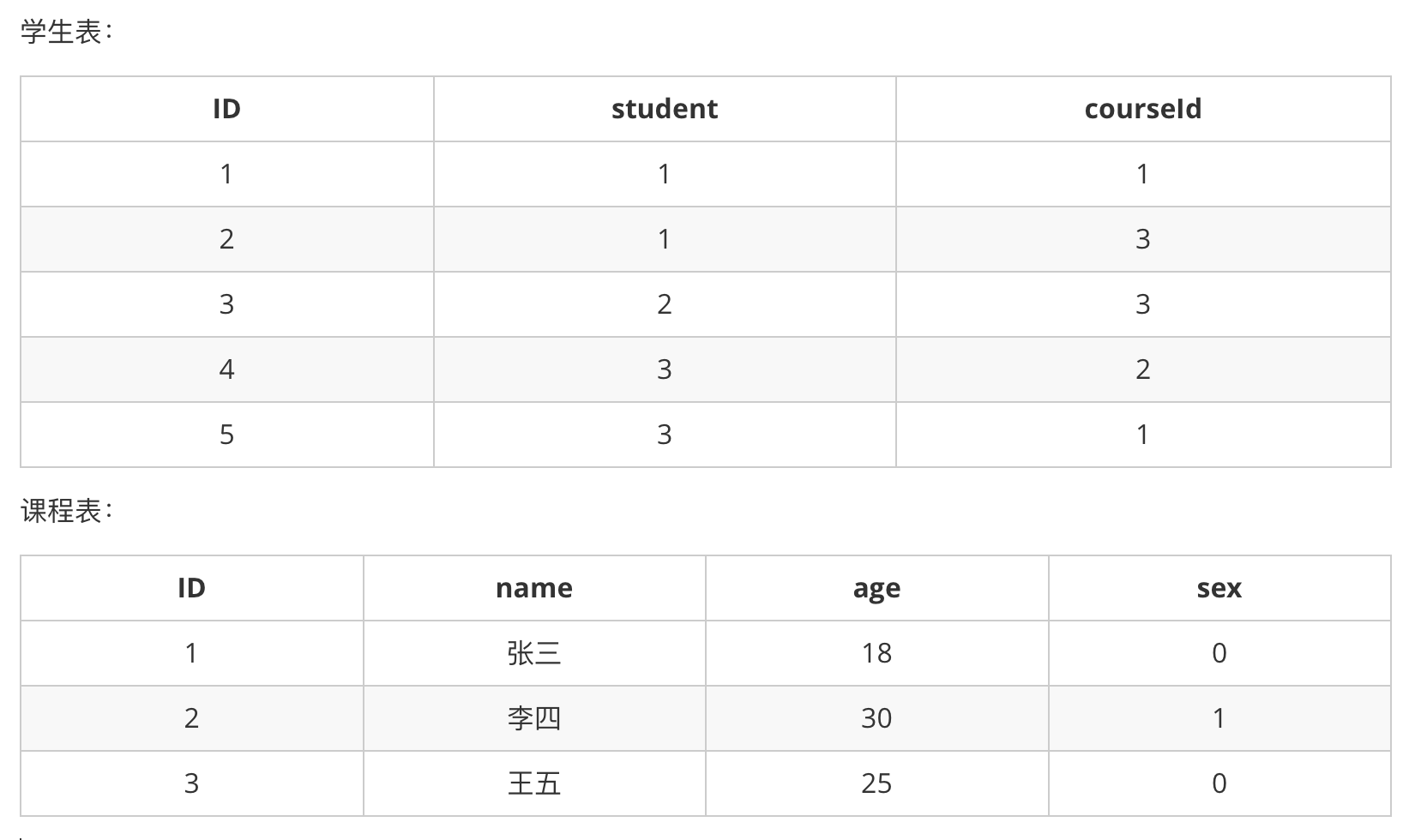
关系
-
创建成绩表scores,结构如下
- id
- 学生
- 科目
- 成绩
-
思考:学生列应该存什么信息呢?
-
答:学生列的数据不是在这里新建的,而应该从学生表引用过来,关系也是一条数据;根据范式要求应该存储学生的编号,而不是学生的姓名等其它信息
-
同理,科目表也是关系列,引用科目表中的数据
关系
- 创建表的语句如下
create table scores(id int primary key auto_increment,stuid int,subid int,score decimal(5,2));
外键
- 思考:怎么保证关系列数据的有效性呢?任何整数都可以吗?
- 答:必须是学生表中id列存在的数据,可以通过外键约束进行数据的有效性验证
- 为stuid添加外键约束
alter table scores add constraint stu_sco foreign key(stuid) references students(id);
- 此时插入或者修改数据时,如果stuid的值在students表中不存在则会报错
- 在创建表时可以直接创建约束
create table scores(id int primary key auto_increment,stuid int,subid int,score decimal(5,2),foreign key(stuid) references students(id),foreign key(subid) references subjects(id));
- 在删除students表的数据时,如果这个id值在scores中已经存在,则会抛异常
- 推荐使用逻辑删除,还可以解决这个问题
- 可以创建表时指定级联操作,也可以在创建表后再修改外键的级联操作
- 语法
alter table scores add constraint stu_sco foreign key(stuid) references students(id) on delete cascade;-
级联操作的类型包括:
- restrict(限制):默认值,抛异常
- cascade(级联):如果主表的记录删掉,则从表中相关联的记录都将被删除
- set null:将外键设置为空
- no action:什么都不做
外键越多,性能越低,为了提升性能不要外键,可以在代码逻辑中做限定