判断题
2-1-1
For a sequentially stored linear list of length N, the time complexities for query and insertion are O(1) and O(N), respectively.
译文:对于长度为N的顺序存储线性列表,查询和插入的时间复杂度分别为O(1)和O(N)。
T F
顺序存储的线性表支持随机存取,所以查询的时间是常数时间,但插入需要把后面每一个元素的位置都进行调整,所以是线性时间。
可是课本P27-28说:顺序表按值查找算法的平均时间复杂度为O(n),顺序表插入算法的平均时间复杂度为O(n)
就疑惑…
2-1-2
If the most commonly used operations are to visit a random position and to insert and delete the last element in a linear list, then sequential storage works the fastest.
译文:如果最常用的操作是访问一个随机位置以及插入和删除线性列表中的最后一个元素,那么顺序存储的速度最快。
T F
频繁地对最后一个元素查删,顺序表完全可以胜任。
2-1-3
In a singly linked list of N nodes, the time complexities for query and insertion are O(1) and O(N), respectively.
译文:在N个节点的单链表中,查询和插入的时间复杂度分别为O(1)和O(N)。
T F
查找是O(N),因为需要沿着next指针找下去。而插入是O(1),只需要改变指针就行了。
但是课本P33-35:单链表按值查找算法的平均时间复杂度为O(n),单链表插入算法的平均时间复杂度为O(n);
就疑惑…
2-1-4
If a linear list is represented by a linked list, the addresses of the elements in the memory must be consecutive.
译文:如果线性链表由链表表示,则内存中元素的地址必须是连续的。
T F
如果一个线性列表用一个链表表示,那么内存中元素的地址:可能是连续的,也可能不是连续的;
课本P29:线性表链式存储结构的特点是:用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的);
课本P32:在单链表中,各个元素的存储位置都是随意的;
2-1-5
将N个数据按照从小到大顺序组织存放在一个单向链表中。如果采用二分查找,那么查找的平均时间复杂度是O(logN)。
T F
数组二分查找的平均复杂度是O(logN)没有错,但二分查找是不可以用链表存储的。这是由链表的特性决定的。链表是很典型的顺序存取结构,数据在链表中的位置只能通过从头到尾的顺序检索得到,即使是有序的,要操作其中的某个数据也必须从头开始。这和数组有本质的不同。数组中的元素是通过下标来确定的,只要你知道了下标,就可以直接存储整个元素,比如a[5],是直接的。链表没有这个,所以,折半查找只能在数组上进行。
课本P32:单链表是非随机存取的存储结构,要取得第 i 个数据元素必须从头指针出发顺链进行寻找,也称为顺序存取的存取结构;
单选题
2-2-1
对于顺序存储的长度为N的线性表,访问结点和增加结点的时间复杂度为:
A:O(1), O(1)
B:O(1), O(N)
C:O(N), O(1)
D:O(N), O(N)
顺序存储可以实现“随机存取”,因此访问结点的时间复杂度为O(1),而插入、删除结点由于涉及到大量移动元素,故其时间复杂度为O(n);
课本P26-28:顺序表取值算法的平均时间复杂度为O(1),顺序表按值查找算法的平均时间复杂度为O(n),顺序表插入算法的平均时间复杂度为O(n);
访问结点 == 取值?
2-2-2
链表不具有的特点是:
A:插入、删除不需要移动元素
B:方便随机访问任一元素
C:不必事先估计存储空间
D:所需空间与线性长度成正比
2-2-3
线性表L在什么情况下适用于使用链式结构实现?
A:需不断对L进行删除插入
B:需经常修改L中的结点值
C:L中含有大量的结点
D:L中结点结构复杂
2-2-4
线性表若采用链式存储结构时,要求内存中可用存储单元的地址
A:必须是连续的
B:连续或不连续都可以
C:部分地址必须是连续的
D:一定是不连续的
2-2-5
在N个结点的顺序表中,算法的时间复杂度为O(1)的操作是:
A:访问第i个结点(1≤i≤N)和求第i个结点的直接前驱(2≤i≤N)
B:在第i个结点后插入一个新结点(1≤i≤N)
C:删除第i个结点(1≤i≤N)
D:将N个结点从小到大排序
A.假设顺序表 L,长度为 n,求第 i 个节点 L[i],直接前驱 L[i-1],因此为 O(1) ;
B需要移动 n-i 个节点,因此为O(n);
C也需要移动 n-i 个节点 ;
D根据排序方法不同最慢 O(n^2),最快 O(nlogn);
2-2-6
将线性表La和Lb头尾连接,要求时间复杂度为O(1),且占用辅助空间尽量小。应该使用哪种结构?
A:单链表
B:单循环链表
C:带尾指针的单循环链表
D:带头结点的双循环链表
选项C和D的时间复杂度都为 O(1),但C的指针少,占用的辅助空间更小;
课本P38:
循环单链表:
在某些情况下,若在循环链表中设立尾指针而不设立头指针,可使一些操作简化;
2-2-7
采用多项式的非零项链式存储表示法,如果两个多项式的非零项分别为N1
和N2个,最高项指数分别为M1和M2,则实现两个多项式相加的时间复杂度是:
A:O(N1+N2)
B:O(M1+M2)
C:O(N1×N2)
D:O(M1×M2)
课本P49:假设两个多项式的项数分别为m和n,多项式相加算法的时间复杂度为O(m+n),空间复杂度为O(1);
这里不设考点;
2-2-8
In a singly linked list, if the node pointed by p is not the last node, then to insert a node pointed by s after p, we must do:
译文:在单链表中,如果p指向的节点不是最后一个节点,那么要在p后面插入一个s指向的节点,必须做到:
A:s->next=p; p->next=s;
B:s->next=p->next; p=s;
C:s->next=p->next; p->next=s;
D:p->next=s; s->next=p;
课本P37:将新结点* s插入到结点* p之后;
2-2-9
For a non-empty singly linked circular list, with h and p pointing to its head and tail nodes, respectively, the TRUE statement is:
译文:对于一个非空单链循环链表,其中 h 和 p 分别指向其头节点和尾节点,则真命题为:
A:p->next == h
B:p->next == NULL
C:p == NULL
D:p == h
答案不确定?
2-2-10
The following table shows how a linked list is stored in memory space with the head node c:
译文:下表显示了以 c 为头节点的链表是如何存储在内存空间中的:

Now f is stored at 1014H and is inserted into the linked list between a and e. Then the “Link” fields of a, e, and f are __, respectively.
译文:现在 f 存储在 1014H ,并插入到 a 和 e 之间的链表中。然后, a 、 e 和 f 的“链接”字段分别为__。
A:1010H, 1014H, 1004H
B:1010H, 1004H, 1014H
C:1014H, 1010H, 1004H
D:1014H, 1004H, 1010H

编程题
2-7-1 顺序表的建立及遍历 (20分)
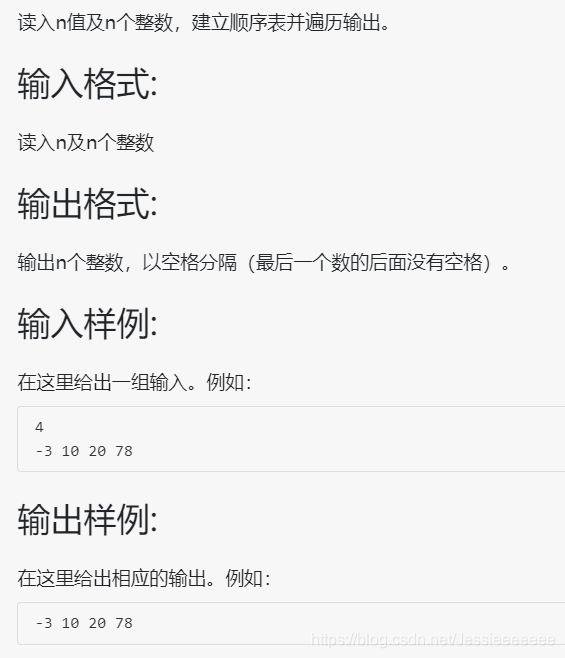
#include <stdio.h>
#include <stdlib.h>
#include<algorithm>
using namespace std;
#define MAXSIZE 100
typedef int ElemType;/*宏定义int型*/
typedef struct
{
ElemType *elem;
int length;
} SqList;
int n;
void InitList(SqList &L,int n)
{
L.elem=(ElemType*)malloc(sizeof(MAXSIZE));/*开辟空间:(数据类型*)malloc(长度)*/
L.length=0;
ElemType q;
for(int i=0; i<n; i++)
{
scanf("%d",&q);
L.elem[L.length++]=q;
}
for(int i=0; i<L.length; i++)
printf("%d%c",L.elem[i],i==L.length-1?'\n':' ');
return;
}
int main()
{
scanf("%d",&n);
SqList L;
InitList(L,n);
return 0;
}
2-7-2 单链表的创建及遍历 (20分)
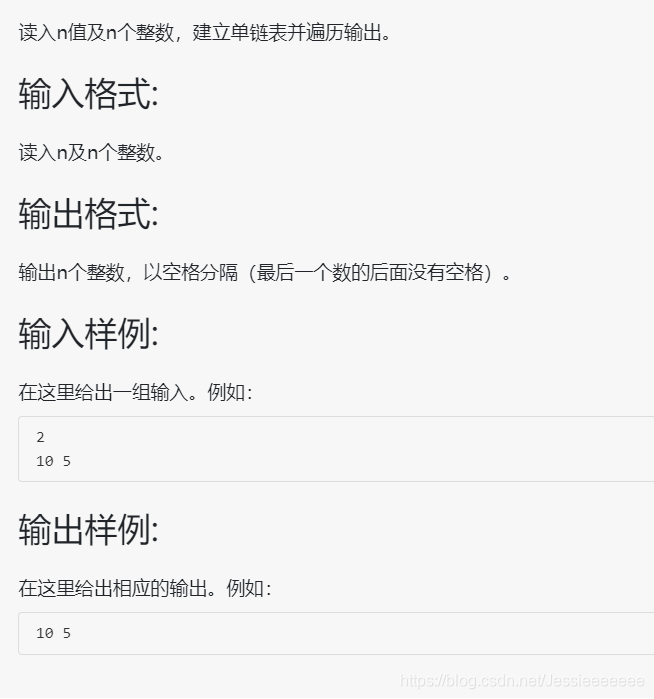
#include<iostream>
using namespace std;
#define OK 1
#define ERROR 0
typedef int Status;
typedef int ElemType;
typedef struct LNode{
ElemType data; //数据域
struct LNode *next; //指针域
} LNode, *LinkList;
Status InitList(LinkList &L); //函数声明
void CreateList( LinkList &L,int n); //函数声明
void DisplayList( LinkList ); //函数声明
void DestroyList( LinkList ); //函数声明
int main()
{
LinkList L; //值传递
InitList( L ); //调用函数InitList
int n;
cin >> n;
CreateList( L, n );
DisplayList( L );
DestroyList( L );
return 0;
}
Status InitList(LinkList &L)
{
//构造一个空的单链表L
L = new LNode ; //生成新结点作为头结点,用头指针L指向头结点
L->next = NULL ; //头结点的指针域置空
return OK;
}
void CreateList( LinkList &L,int n )
//尾插法建立带头结点的有n个元素的链表
{
LNode *p, *r; //定义p与r指针
r = L ; //尾指针r指向头结点
for( int i=0; i<n; ++i ){
p = new LNode ; //生成新结点*p
cin >> p->data; //输入元素值赋给新结点*p的数据域
p->next= NULL;
r->next = p ; //将新结点*p插人尾结点*r之后
r = p; //r指向新的尾结点*p
}
}
void DisplayList( LinkList L )
//遍历带头结点的单链表
{
LNode *p =L->next ;
while ( p ){
if(p->next==NULL){
cout<<p->data;
}else{
cout <<p->data<<" ";
}
p=p->next;
}
}
void DestroyList( LinkList L )
{
//回收L的所有结点的空间
LNode *p = L, *q;
while ( p ){
//当p指向结点不为空
q = p->next; //q指向p的下一结点
delete p; //回收p指向的结点空间
p = q; //p指向q指向的结点
}
}
2-7-3 数组循环左移 (20分)

#include<stdio.h>
#include<stdlib.h>
typedef struct Node *NodePtr;
struct Node
{
int Val;
NodePtr Next;
};
int main()
{
int n,m;
int i;
NodePtr Head,Rear,Tmp,Pre;
Head=Rear=(NodePtr)malloc(sizeof(struct Node));
Head->Next=NULL;
scanf("%d %d",&n,&m);
for(i=0;i<n;i++)
{
Pre=(NodePtr)malloc(sizeof(struct Node));
Pre->Next=NULL;
scanf("%d",&Pre->Val);
Rear->Next=Pre;
Rear=Pre;
}
for(i=0;i<m;i++)
{
Tmp=(NodePtr)malloc(sizeof(struct Node));
Tmp->Val=Head->Next->Val;
Tmp->Next=NULL;
Rear->Next=Tmp;
Rear=Tmp;
Head=Head->Next;
}
Tmp=Head->Next;
printf("%d",Tmp->Val);
for(Tmp=Tmp->Next;Tmp!=NULL;Tmp=Tmp->Next)
printf(" %d",Tmp->Val);
return 0;
}