服务器内存增高应急处理过程总结
一、服务器内存问题排查处理过程
服务器内存问题主要包括OOM、GC 和 堆外内存。
一般来讲,会先用free命令先来检查一发内存的各种情况。
使用内存最多的5个进程
ps -aux | sort -k4nr | head 5
或者
top (然后按下M,注意大写)
1.1 堆内内存
内存问题大多还都是堆内内存问题。
表象上主要分为OOM和StackOverflow。
1. OOM
JVM中的内存不足,OOM大致可以分为以下几种:
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
意思是没有足够的内存空间给线程分配java栈,通常是上还是线程池代码写的有问题,比如说忘记shutdown,所以说应该首先从代码层面来寻找问题,使用jstack或者jmap。
如果一切都正常,JVM方面可以通过指定Xss来减少单个thread stack的大小。
另外也可以在系统层面,可以通过修改/etc/security/limits.confnofile和nproc来增大os对线程的限制
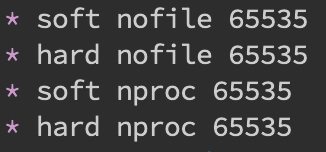
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
意思是堆的内存占用已经达到-Xmx设置的最大值,应该是最常见的OOM错误了。
解决思路:在代码中找,怀疑存在内存泄漏,通过jstack和jmap去定位问题。
如果说一切都正常,才需要通过调整Xmx的值来扩大内存。
Caused by: java.lang.OutOfMemoryError: Meta space
意思是元数据区的内存占用已经达到XX:MaxMetaspaceSize设置的最大值,排查思路和上面的一致,参数方面可以通过XX:MaxPermSize来进行调整。
2. Stack Overflow
栈内存溢出。
Exception in thread "main" java.lang.StackOverflowError
表示线程栈需要的内存大于Xss值,同样也是先进行排查,参数方面通过Xss来调整,但调整的太大可能又会引起OOM。
3. 使用JMAP定位代码内存泄漏
关于OOM和StackOverflow的代码排查方面,一般使用JMAP,jmap -dump:format=b,file=filename pid来导出dump文件

通过mat(Eclipse Memory Analysis Tools)导入dump文件进行分析,内存泄漏问题一般我们直接选Leak Suspects即可,mat给出了内存泄漏的建议。另外也可以选择Top Consumers来查看最大对象报告。和线程相关的问题可以选择thread overview进行分析。除此之外就是选择Histogram类概览来自己慢慢分析。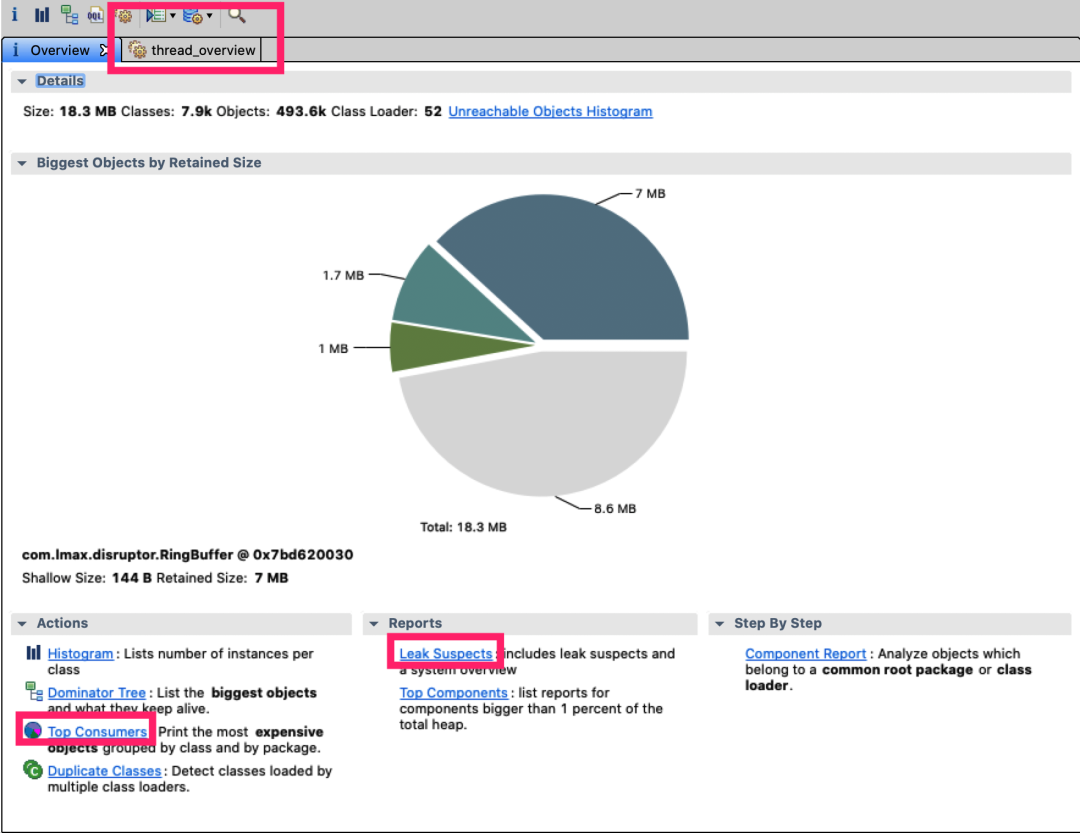
日常开发中,代码产生内存泄漏是比较常见的事,并且比较隐蔽,需要开发者更加关注细节。比如说每次请求都new对象,导致大量重复创建对象;进行文件流操作但未正确关闭;手动不当触发gc;ByteBuffer缓存分配不合理等都会造成代码OOM。
另一方面,我们可以在启动参数中指定-XX:+HeapDumpOnOutOfMemoryError来保存OOM时的dump文件。
1.2 GC
gc问题和线程
堆内内存泄漏总是和GC异常相伴。不过GC问题不只是和内存问题相关,还有可能引起CPU负载、网络问题等系列并发症。
一般先使用jstat来查看分代变化情况,比如youngGC或者fullGC次数是不是太多;EU、OU等指标增长是不是异常呀等。
而更多时候,我们是通过GC日志来排查问题的,在启动参数中加上-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps来开启GC日志。
线程的话太多而且不被及时gc也会引发oom,大部分就是之前说的unable to create new native thread。
除了jstack细细分析dump文件外,我们一般先会看下总体线程,通过pstreee -p pid |wc -l。

或者直接通过查看/proc/pid/task的数量即为线程数量。

youngGC过频繁
youngGC频繁一般是短周期小对象较多,先考虑是不是Eden区/新生代设置的太小了,看能否通过调整-Xmn、-XX:SurvivorRatio等参数设置来解决问题。
如果参数正常,但是young gc频率还是太高,就需要使用Jmap和MAT对dump文件进行进一步排查了。
youngGC耗时过长
耗时过长问题就要看GC日志里耗时耗在哪一块了。以G1日志为例,可以关注Root Scanning、Object Copy、Ref Proc等阶段。
-
Ref Proc耗时长,就要注意引用相关的对象。
-
Root Scanning耗时长,就要注意线程数、跨代引用。
-
Object Copy则需要关注对象生存周期。
而且耗时分析它需要横向比较,就是和其他项目或者正常时间段的耗时比较。
触发fullGC
G1中更多的还是mixedGC,但mixedGC可以和youngGC思路一样去排查。
触发fullGC了一般都会有问题,G1会退化使用Serial收集器来完成垃圾的清理工作,暂停时长达到秒级别,可以说是半跪了。
fullGC的原因可能包括以下这些,以及参数调整方面的一些思路:
- 并发阶段失败:在并发标记阶段,MixGC之前老年代就被填满了,那么这时候G1就会放弃标记周期。这种情况,可能就需要增加堆大小,或者调整并发标记线程数
-XX:ConcGCThreads。 - 晋升失败:在GC的时候没有足够的内存供存活/晋升对象使用,所以触发了Full GC。这时候可以通过
-XX:G1ReservePercent来增加预留内存百分比,减少-XX:InitiatingHeapOccupancyPercent来提前启动标记,-XX:ConcGCThreads来增加标记线程数也是可以的。 - 大对象分配失败:大对象找不到合适的region空间进行分配,就会进行fullGC,这种情况下可以增大内存或者增大
-XX:G1HeapRegionSize。 - 程序主动执行
System.gc():不要随便写就对了。
另外,我们可以在启动参数中配置-XX:HeapDumpPath=/xxx/dump.hprof来dump fullGC相关的文件,并通过jinfo来进行gc前后的dump
jinfo -flag +HeapDumpBeforeFullGC pid
jinfo -flag +HeapDumpAfterFullGC pid
这样得到2份dump文件,对比后主要关注被gc掉的问题对象来定位问题。
1.3 堆外内存
堆外内存溢出表现就是物理常驻内存增长快,报错的话视使用方式都不确定,如果由于使用Netty导致的,那错误日志里可能会出现OutOfDirectMemoryError错误,如果直接是DirectByteBuffer,那会报OutOfMemoryError: Direct buffer memory。
堆外内存溢出往往是和NIO的使用相关,一般先通过pmap来查看下进程占用的内存情况pmap -x pid | sort -rn -k3 | head -30,这段意思是查看对应pid倒序前30大的内存段。
这边可以再过一段时间后再跑一次命令看看内存增长情况,或者和正常机器比较可疑的内存差在哪里。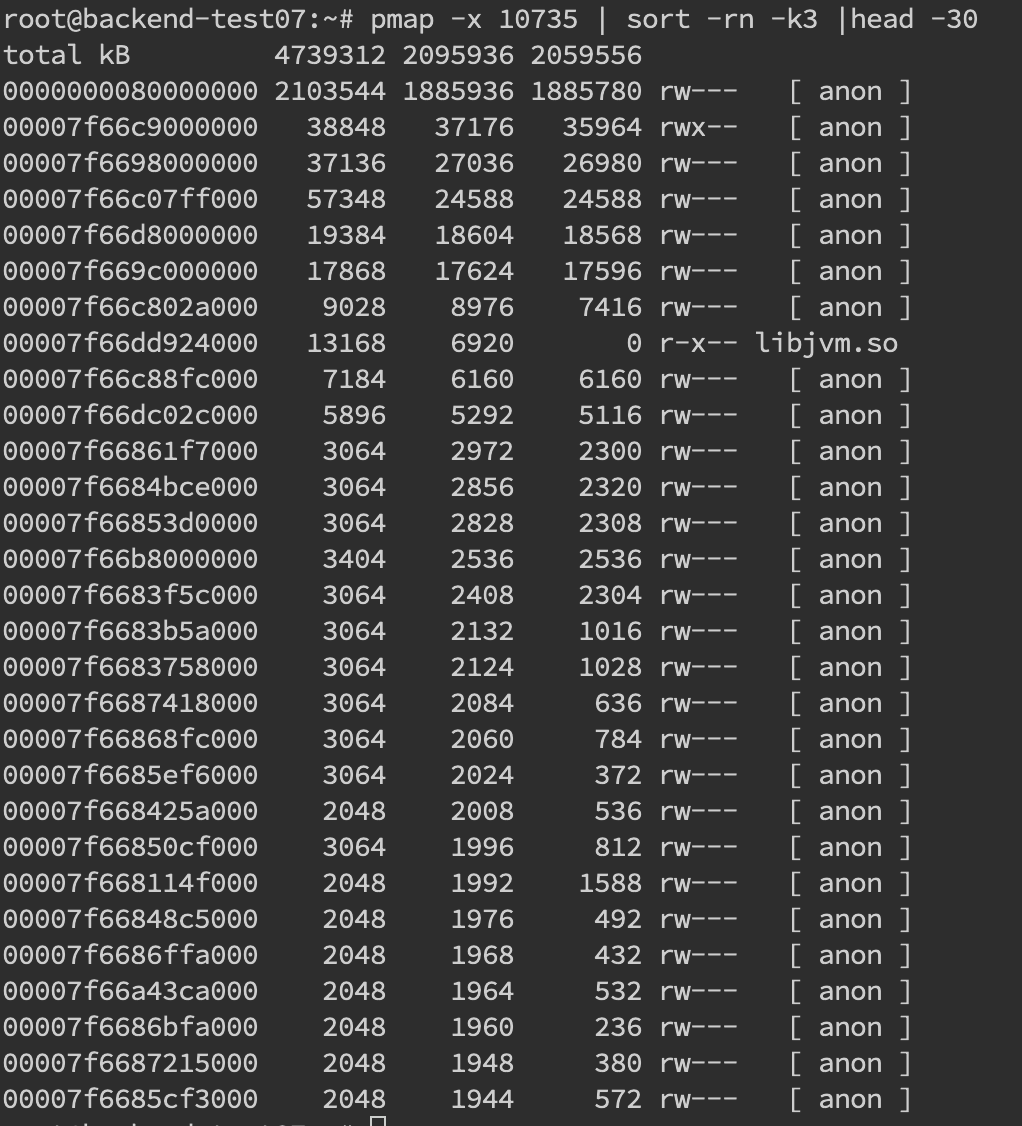 我们如果确定有可疑的内存端,需要通过gdb来分析
我们如果确定有可疑的内存端,需要通过gdb来分析gdb --batch --pid {pid} -ex "dump memory filename.dump {内存起始地址} {内存起始地址+内存块大小}"

获取dump文件后可用heaxdump进行查看hexdump -C filename | less,不过大多数看到的都是二进制乱码。
NMT是Java7U40引入的HotSpot新特性,配合jcmd命令我们就可以看到具体内存组成了。需要在启动参数中加入 -XX:NativeMemoryTracking=summary 或者 -XX:NativeMemoryTracking=detail,会有略微性能损耗。
一般对于堆外内存缓慢增长直到爆炸的情况来说,可以先设一个基线jcmd pid VM.native_memory baseline。 然后等放一段时间后再去看看内存增长的情况,通过
然后等放一段时间后再去看看内存增长的情况,通过jcmd pid VM.native_memory detail.diff(summary.diff)做一下summary或者detail级别的diff。
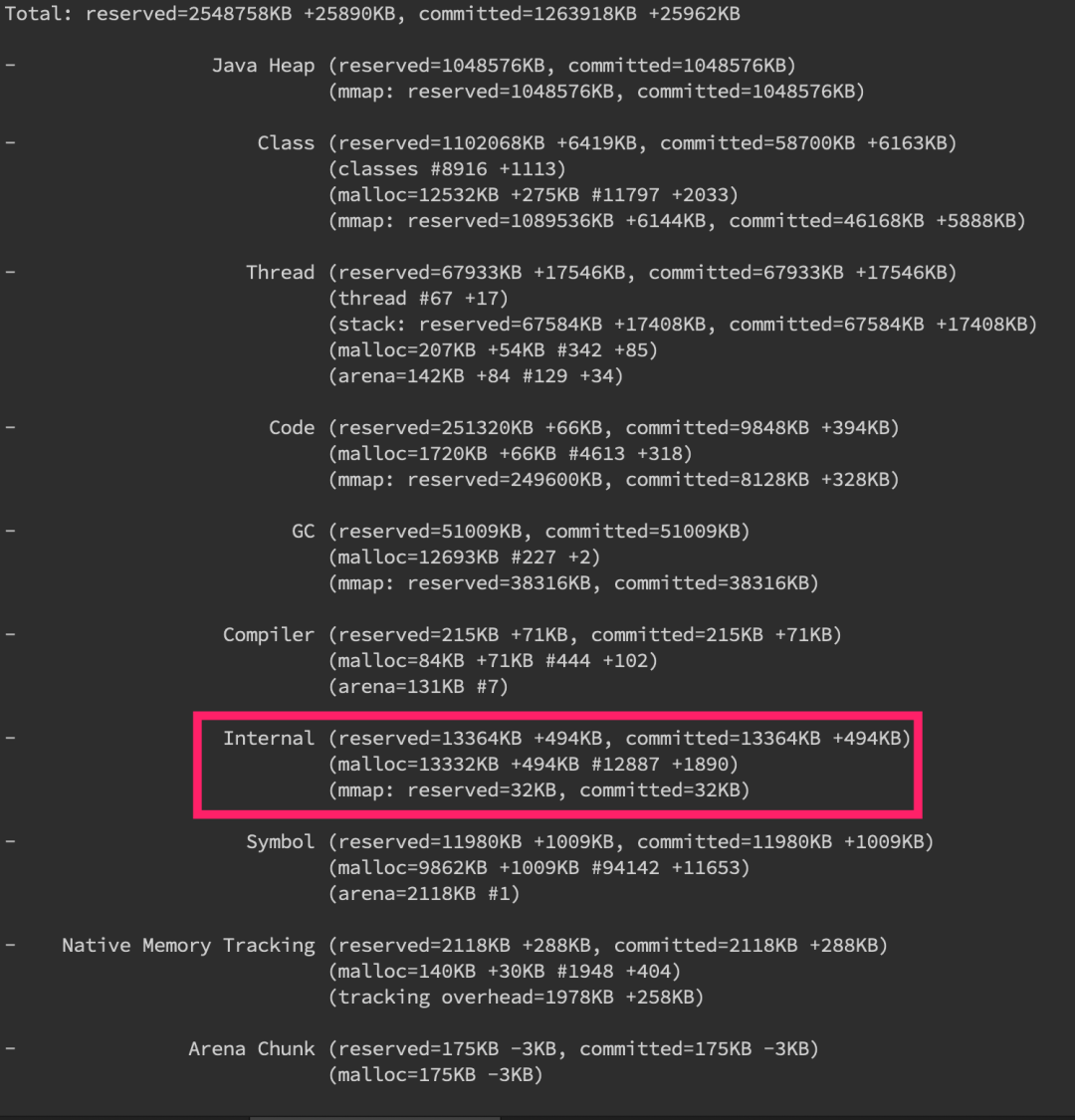 可以看到jcmd分析出来的内存十分详细,包括堆内、线程以及gc(所以上述其他内存异常其实都可以用nmt来分析),这边堆外内存我们重点关注Internal的内存增长,如果增长十分明显的话那就是有问题了。detail级别的话还会有具体内存段的增长情况,如下图。
可以看到jcmd分析出来的内存十分详细,包括堆内、线程以及gc(所以上述其他内存异常其实都可以用nmt来分析),这边堆外内存我们重点关注Internal的内存增长,如果增长十分明显的话那就是有问题了。detail级别的话还会有具体内存段的增长情况,如下图。
此外在系统层面,我们还可以使用strace命令来监控内存分配 strace -f -e "brk,mmap,munmap" -p pid这边内存分配信息主要包括了pid和内存地址。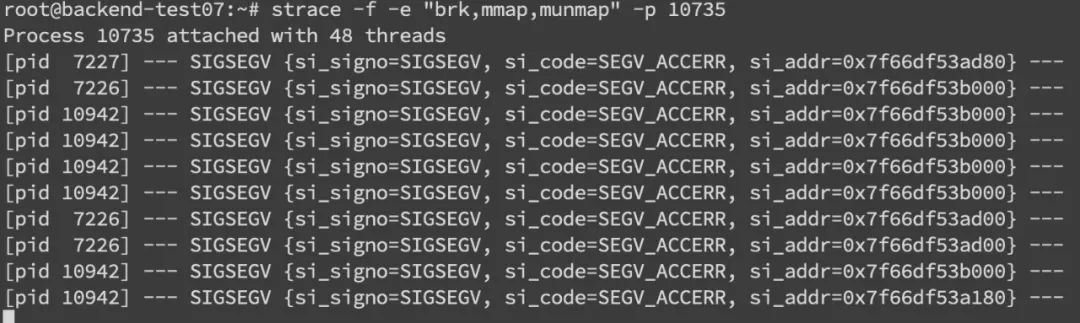
不过其实上面那些操作也很难定位到具体的问题点,关键还是要看错误日志栈,找到可疑的对象,搞清楚它的回收机制,然后去分析对应的对象。比如DirectByteBuffer分配内存的话,是需要full GC或者手动system.gc来进行回收的(所以最好不要使用-XX:+DisableExplicitGC)。那么其实我们可以跟踪一下DirectByteBuffer对象的内存情况,通过jmap -histo:live pid手动触发fullGC来看看堆外内存有没有被回收。如果被回收了,那么大概率是堆外内存本身分配的太小了,通过-XX:MaxDirectMemorySize进行调整。如果没有什么变化,那就要使用jmap去分析那些不能被gc的对象,以及和DirectByteBuffer之间的引用关系了。
二、常见OOM异常分析
2.1 Java 堆溢出-java.lang.OutOfMemoryError: Java heap space
Java堆用于存储对象实例,只要不断地创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,那么在对象数量到达最大堆的容量限制后就会产生内存溢出异常。
堆内对象不能进行回收了,堆内存持续增大,这样达到了堆内存的最大值,数据满了,所以就出来了。
1. Java 堆溢出原因
- 无法在 Java 堆中分配对象
- 应用程序保存了无法被GC回收的对象。
- 应用程序过度使用 finalizer。
- 代码中可能存在大对象分配
- 可能存在内存泄露,导致在多次GC之后,还是无法找到一块足够大的内存容纳当前对象。
2. Java 堆溢出排查解决思路
- 查找关键报错信息,如
java.lang.OutOfMemoryError: Java heap space
- 使用内存映像分析工具(如Eclipsc Memory Analyzer或者Jprofiler)对Dump出来的堆储存快照进行分析,分析清楚是内存泄漏还是内存溢出。
- 如果是内存泄漏,可进一步通过工具查看泄漏对象到GC Roots的引用链,修复应用程序中的内存泄漏。
- 如果不存在泄漏,先检查代码是否有死循环,递归等,再考虑用 -Xmx 增加堆大小。
1、检查是否存在大对象的分配,最有可能的是大数组分配
2、通过jmap命令,把堆内存dump下来,使用mat工具分析一下,检查是否存在内存泄露的问题
3、如果没有找到明显的内存泄露,使用 -Xmx 加大堆内存
4、还有一点容易被忽略,检查是否有大量的自定义的 Finalizable 对象,也有可能是框架内部提供的,考虑其存在的必要性
3. demo代码
import java.util.ArrayList;
import java.util.List;
/**
* JVM配置参数
* -Xms20m JVM初始分配的内存20m
* -Xmx20m JVM最大可用内存为20m
* -XX:+HeapDumpOnOutOfMemoryError 当JVM发生OOM时,自动生成DUMP文件
* -XX:HeapDumpPath=/Users/weihuaxiao/Desktop/dump/ 生成DUMP文件的路径
*/
public class HeapOOM {
static class OOMObject {
}
public static void main(String[] args) {
List<OOMObject> list = new ArrayList<OOMObject>();
//在堆中无限创建对象
while (true) {
list.add(new OOMObject());
}
}
}
4. 运行结果

-
查找报错关键信息
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space -
使用内存映像分析工具Jprofiler分析产生的堆储存快照

由图可得,OOMObject这个类创建了810326个实例,是属于内存溢出,这时候先定位到对应代码,发现死循环导致的,修复即可。
2.2 栈溢出
关于虚拟机栈和本地方法栈,在Java虚拟机规范中描述了两种异常:
- 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError 异常;
- 如果虚拟机栈可以动态扩展,当扩展时无法申请到足够的内存时会抛出 OutOfMemoryError 异常。
1. 栈溢出原因
- 在单个线程下,栈帧太大,或者虚拟机栈容量太小,当内存无法分配的时候,虚拟机抛出StackOverflowError 异常。
- 不断地建立线程的方式会导致内存溢出。
2. 栈溢出排查解决思路
- 查找关键报错信息,确定是StackOverflowError还是OutOfMemoryError
- 如果是StackOverflowError,检查代码是否递归调用方法等
- 如果是OutOfMemoryError,检查是否有死循环创建线程等,通过-Xss降低的每个线程栈大小的容量
3. demo代码
/**
* -Xss2M
*/
public class JavaVMStackOOM {
private void dontStop(){
while(true){
}
}
public void stackLeakByThread(){
while(true){
Thread thread = new Thread(new Runnable(){
public void run() {
dontStop();
}
});
thread.start();}
}
public static void main(String[] args) {
JavaVMStackOOM oom = new JavaVMStackOOM();
oom.stackLeakByThread();
}
}
4. 运行结果

-
查找报错关键信息
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread -
确定是创建线程导致的栈溢出OOM
Thread thread = new Thread(new Runnable(){
public void run() {
dontStop();
}
});
- 排查代码,确定是否显示使用死循环创建线程,或者隐式调用第三方接口创建线程
2.3 方法区溢出
方法区,(又叫永久代,JDK8后,元空间替换了永久代),用于存放Class的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。运行时产生大量的类,会填满方法区,造成溢出。
1. 方法区溢出原因
- 使用CGLib生成了大量的代理类,导致方法区被撑爆
- 在Java7之前,频繁的错误使用String.intern方法
- 大量jsp和动态产生jsp
- 应用长时间运行,没有重启
2. 方法区溢出排查解决思路
- 检查是否永久代空间设置得过小
- 检查代码是否频繁错误得使用String.intern方法
- 检查是否跟jsp有关。
- 检查是否使用CGLib生成了大量的代理类
- 重启大法,重启JVM
3. demo代码
import org.springframework.cglib.proxy.Enhancer;
import org.springframework.cglib.proxy.MethodInterceptor;
import org.springframework.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
/**
* jdk8以上的话,
* 虚拟机参数:-XX:MetaspaceSize=10M -XX:MaxMetaspaceSize=10M
*/
public class JavaMethodAreaOOM {
public static void main(String[] args) {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
public Object intercept(Object obj, Method method,
Object[] args, MethodProxy proxy) throws Throwable {
return proxy.invokeSuper(obj, args);
}
});
enhancer.create();
}
}
static class OOMObject {
}
}
4. 运行结果

-
查找报错关键信息
Caused by: java.lang.OutOfMemoryError: Metaspace -
检查JVM元空间设置参数是否过小
-XX:MetaspaceSize=10M -XX:MaxMetaspaceSize=10M -
检查对应代码,是否使用CGLib生成了大量的代理类
while (true) {
...
enhancer.setCallback(new MethodInterceptor() {
public Object intercept(Object obj, Method method,
Object[] args, MethodProxy proxy) throws Throwable {
return proxy.invokeSuper(obj, args);
}
});
enhancer.create();
}
2.4 本机直接内存溢出
直接内存并不是虚拟机运行时数据区的一部分,也不是Java 虚拟机规范中定义的内存区域。但是,这部分内存也被频繁地使用,而且也可能导致OOM。
在JDK1.4 中新加入了NIO(New Input/Output)类,它可以使用 native 函数库直接分配堆外内存,然后通过一个存储在Java堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
1. 直接内存溢出原因
- 本机直接内存的分配虽然不会受到Java 堆大小的限制,但是受到本机总内存大小限制。
- 直接内存由 -XX:MaxDirectMemorySize 指定,如果不指定,则默认与Java堆最大值(-Xmx指定)一样。
- NIO程序中,使用ByteBuffer.allocteDirect(capability)分配的是直接内存,可能导致直接内存溢出。
2. 直接内存溢出
- 检查代码是否恰当
- 检查JVM参数-Xmx,-XX:MaxDirectMemorySize 是否合理。
3. demo代码
import java.nio.ByteBuffer;
import java.util.concurrent.TimeUnit;
/**
* -Xmx256m -XX:MaxDirectMemorySize=100M
*/
public class DirectByteBufferTest {
public static void main(String[] args) throws InterruptedException{
//分配128MB直接内存
ByteBuffer bb = ByteBuffer.allocateDirect(1024*1024*128);
TimeUnit.SECONDS.sleep(10);
System.out.println("ok");
}
}
4. 运行结果

ByteBuffer分配128MB直接内存,而JVM参数-XX:MaxDirectMemorySize=100M指定最大是100M,因此发生直接内存溢出。
ByteBuffer bb = ByteBuffer.allocateDirect(1024*1024*128);
2.5 GC overhead limit exceeded
- 这个是JDK6新加的错误类型,一般都是堆太小导致的。
- Sun 官方对此的定义:超过98%的时间用来做GC并且回收了不到2%的堆内存时会抛出此异常。
1. 解决方案
- 检查项目中是否有大量的死循环或有使用大内存的代码,优化代码。
- 检查JVM参数-Xmx -Xms是否合理
- dump内存,检查是否存在内存泄露,如果没有,加大内存。
2. demo代码
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* JVm参数 -Xmx8m -Xms8m
*/
public class GCoverheadTest {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executor.execute(() -> {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
//do nothing
}
});
}
}
}
3. 运行结果

实例代码使用了newFixedThreadPool线程池,它使用了无界队列,无限循环执行任务,会导致内存飙升。因为设置了堆比较小,所以出现此类型OOM。