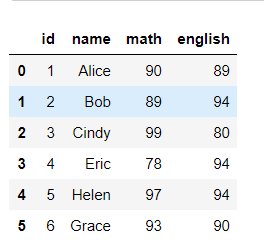
首先写一dataframe吧
import pandas as pd
import numpy as np
test_dict = {
'id':[1,2,3,4,5,6],'name':['Alice','Bob','Cindy','Eric','Helen','Grace '],'math':[90,89,99,78,97,93],'english':[89,94,80,94,94,90]}
df = pd.DataFrame(test_dict)
df
现在记住它的样子,接下来就完全对它进行操作了
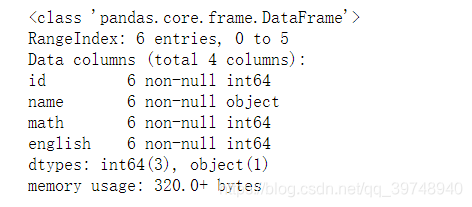
1.查看数据
#显示 dataframe 的简明摘要,包括每列非空值的数量
df.info()
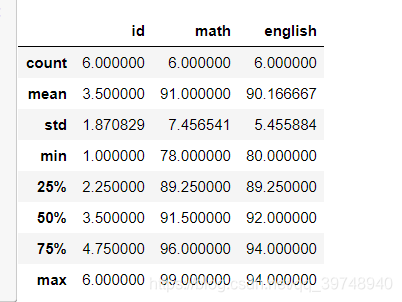
# 返回每列数据的有效描述性统计
df.describe()
# 查看每列的索引号和标签
for i, v in enumerate(df.columns):
print(i, v)

loc[]和iloc[]
这两个函数都是用来找数据框里数据的函数,简单来说是他们的区别
loc[]传入的是行、列的名字:如loc[‘第几行’,'那一列’]
iloc[]传入的是行、列的索引:如iloc[1,1]就是第二行第二列
ps: ':'表示所有的行或列
# 选择从 'id' 到'math.间所有列
df_means = df.loc[:,'id':'math'] #也可用索引号来实现iloc[:,:12]
df_means.head(3)
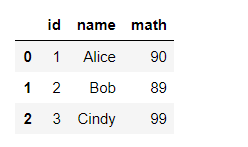
#若要选取不连续多个列还要Import numpy as np
df_max = df.iloc[:,np.r_[0:1,3:4]]
df_max
2.缺失数据的处理
我们对这张表稍微改一改,看,出现了一个空值

查看缺失数据
df.isnull().sum()

处理缺失值
1.直接删除
#axis=0表示删除这一行,=1表示删除这一列
df.dropna(axis=0,inplace=True)
2.填充
- 填充为0
df.fillna(0, inplace=True) # 填充 0
填充均值、众数、种数
df.fillna(df.mean(),inplace=True) # 对每一列的缺失值,填充当列的均值
df.fillna(value={
'edu_deg_cd': train_tag['edu_deg_cd'].mode()[0], # 对多列来说使用众数替换缺失
'deg_cd':train_tag['deg_cd'].mode()[0],
'atdd_type': train_tag['atdd_type'].mode()[0]},inplace = True)
3.数据冗余
df.duplicated() #来查看冗余行,
df.drop_duplicates(inplace=True) #删除冗余
4.脏数据的处理
如果表格里有一些不对的数据,或者填写有误的数据,我姑且把这种称为脏数据,那么对于脏数据应该怎么处理呢?我们来看下面这个数据框:
import pandas as pd
import numpy as np
test_dict = {
'id':[1,2,3,4,5,6],'name':['Alice','Bob','Cindy','Eric','Helen','Grace '],'math':[90,'\\N',99,78,97,93],'english':[89,94,80,94,94,90]}
df = pd.DataFrame(test_dict)
df
首先我们找到脏数据所在行:
df.loc[df['math']=='\\N']
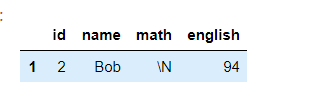
然后我们想用平均分来替代这个脏数据
df.loc[df['math']=='\\N','math'] = df.drop(1).math.mean()
df

5.画图工具
1.箱线图
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10,4))
plt.xlim(-0,120)
sns.boxplot(x = df['math'])
print('Sale volume outliers:',df['math'][df['math']>100].unique())
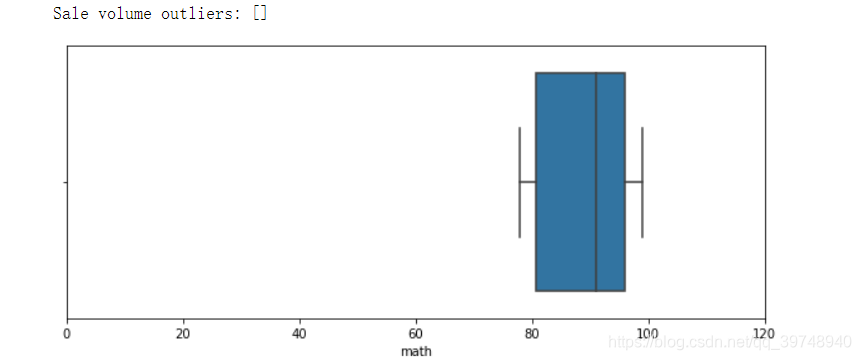
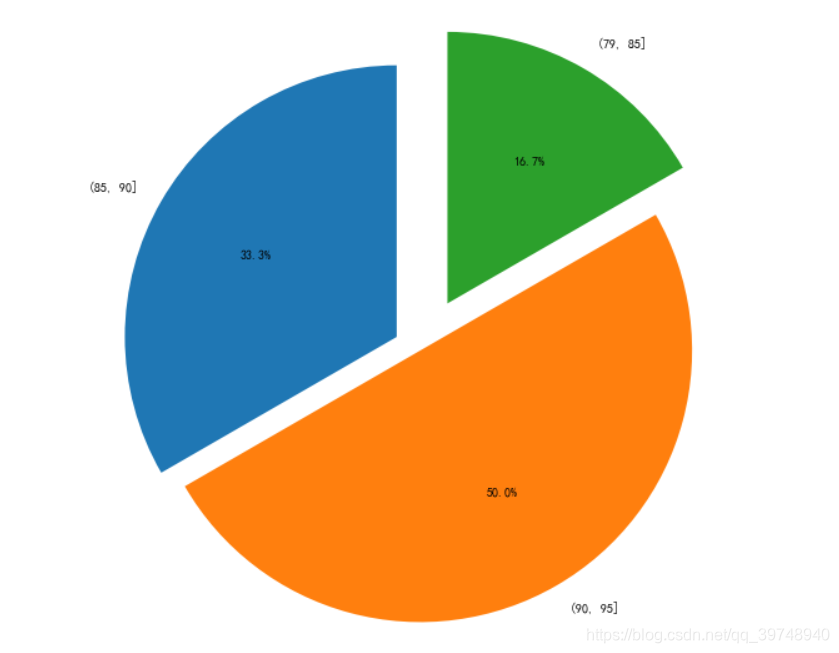
2.饼图
import matplotlib.pyplot as plt
english = list(df['english'])
bins =[79,85,90,95]
english_cut = pd.cut(english, bins)
english_cut = list(english_cut)
english_list = []
count_list = []
for english in english_cut:
if english not in english_list:
count = english_cut.count(english)
english_list.append(english)
count_list.append(count)
print(english_list)
print(count_list)
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(15,10))
plt.axis('equal') #该行代码使饼图长宽相等
plt.pie(count_list, labels=english_list, explode=(0.1,0,0.2),autopct='%1.1f%%', startangle=90)
6.表与表的连接
这里介绍几个函数merge、concat和append
同样我们先来建立两张数据框
test_dict1 = {
'id':[1,2,3,4,5,6],'name':['Alice','Bob','Cindy','Eric','Helen','Grace '],'math':[88,89,99,78,97,93],'english':[89,94,80,94,94,90]}
df1 = pd.DataFrame(test_dict)
df1
test_dict2 = {
'id':[1,2,3,4,5,6],'name':['Alice','Bob','Cindy','Eric','Helen','Grace '],'sex':['female','male','female','female','female','female']}
df2 = pd.DataFrame(test_dict)
df2

- merge函数,默认情况下,会按照相同字段的进行连接,其他参数一般用不到,主要只能两两拼接

df1.merge(df2)

- concat()函数
pd.concat(objs, # 要合并对象
axis=0, # 选择合并轴,0按列,1按行
join='outer', # 连接方式,默认并集
join_axes=None, #参数 join_axes 可指定 index 来对齐数据。这样会切掉指定的 index 之外的数据
ignore_index=False, #当设为 ignore_index=True 时,新 df 将不会使用拼接成员 df 的 index,而是重新生成一个从 0 开始的 index 值
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True
)
pd.concat([df1,df2],axis=1)

pd.concat([df1,df2],axis=0)

- append函数将被 append 的对象添加到调用者的末尾(类似 list 的方法)。
DataFrame.append(other,
ignore_index=False,
verify_integrity=False,
sort=None
)
df1.append(df2)

7.分类变量改成数值变量
我们来看这样一张表,想要把性别变成数值变量
import pandas as pd
import numpy as np
test_dict = {
'id':[1,2,3,4,5,6],'name':['Alice','Bob','Cindy','Eric','Helen','Grace '],'math':[90,90,99,78,97,93],'sex':['F','M','F','M','M','M']}
df = pd.DataFrame(test_dict)
df

方法一:采用sklearn
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
df['sex'] = class_le.fit_transform(df['sex'].values)
df

2, 映射字典将类标转换为整数
import numpy as np
# class_mapping = {label: idx for idx, label in enumerate(np.unique(df['sex']))}
class_mapping = {
label: idx for idx, label in [[1,'M'],[0,'F']]}
df['sex'] = df['sex'].map(class_mapping)
df
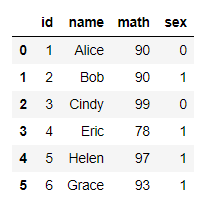
3.使用one-hot编码创建一个新的虚拟特征
#3,使用one-hot编码创建一个新的虚拟特征
from sklearn.preprocessing import OneHotEncoder
pf = pd.get_dummies(df[['sex']]) #生成两列数据sex_F和sex_M,对应性别的行为1,否则为0
df = pd.concat([df, pf], axis=1)
df.drop(['sex'], axis=1, inplace=True)
df

8.改变数据类型
这里提供一个函数,大家自行融会贯通
def downcast_dtypes(df):
cols_float = [c for c in df if df[c].dtype == 'float66']
cols_object = [c for c in df if df[c].dtype == 'object']
cols_int64_32 = [c for c in df if df[c].dtype in ['int64', 'int32']]
df[cols_float] = df[cols_object].astype(np.float32)
df[cols_object] = df[cols_object].astype(np.float32)
df[cols_int64_32] = df[cols_int64_32].astype(np.int16)
return df