写在前面的话
1、网络简介
Network In Network是2014年ICLR中一篇比较出众的论文,该论文在CNN的基础上,通过设计mlpConv以及利用全局Pooling替代全连接层的方式,不仅减少了参数的数量,同时减少了过拟合的发生。同时GoogleNet中也采用了Network In Network中的思想,下面对论文进行详细的总结。
2、Introduction
1、卷积层(convolution filter)是一种广义的线性模型(GLM),抽象层次较低。
2、GLM适用于线性可分的模型,所以卷积层也适用于线性可分的模型。
3、数据多是线性不可分的,利用更强的非线性单元代替GLM可以增强模型的抽象能力。
4、NIN利用Mlpconv替代CNN。
5、NIN主要创新点:
5.1、Mlpconv结构:
Mlpconv结构如下:
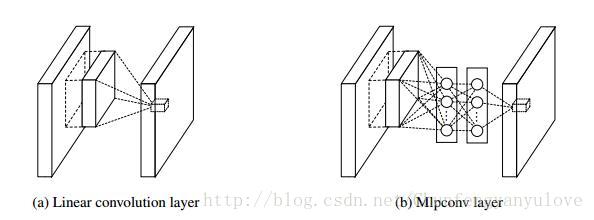
- Mlpconv与Conv均与局部感受野( local receptive field)连接,输出特征向量(feature vector)
- Mlpconv单元是包含多个全连接的MLP单元模块。
- Mlpconv的运算方式与Conv相同,均采用滑动窗口方式。
- NIN就是多个Mlpconv的堆叠
5.2、全局平均池化代替全连接层
相比较与全连接层,利用池化替代,对于损失的反向传播具有更好的可解释性。
减少过拟合。
3、CNN
1、CNN运算方式,ReLU为例:
其中i,j是像素位置,k是通道索引。
2、CNN对于线性可分实例具有很好的效果,但是好的抽象一般都是非线性的,CNN通过增加卷积核的个数达到该效果,但是这样容易产生过拟合现象。
3、CNN中越高层,抽象的区域越大。
Maxout
- maxout构建分段函数,适用于各类凸函数。
- maxout相比较于传统的conv layer, 可以较好的分割出凸集。
*
4、Network In Network
Network In Network结构
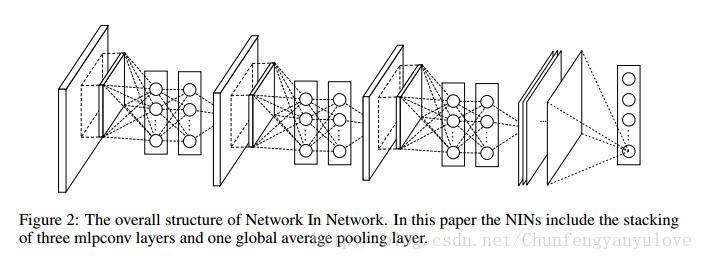
参数版
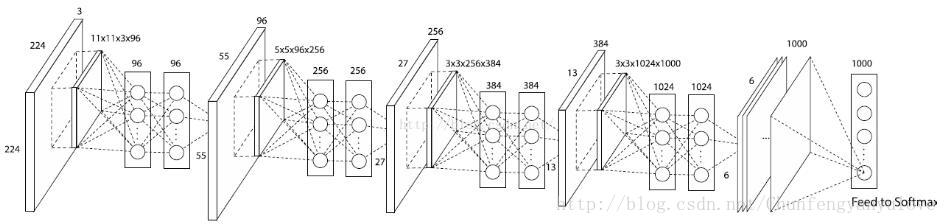
Mlpconv
1、why do we choose mlp?
- mpl 与conv是相似的,均利用反向传播训练。
- mpl本身也可以是深度模型。
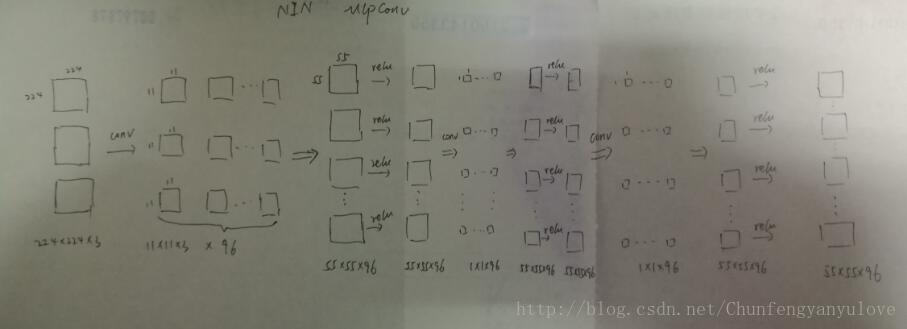
2、Mlpconv 计算方法
mlpconv实现结构图
Mlpconv对比maxout,maxout可以较好的分割凸函数集,而Mlpconv比maxout具有更好的拟合效果
Global average pooling
1、传统的卷积神经网络,首先利用卷积提特征,然后在卷积层后接全连接层,最后利用softmax进行分类。
2、全连接层容易过拟合,所以dropout被提出。
3、Global average pooling方法:
- 对特征图进行全局均值池化操作,结果向量利用softmax分类
- 利用全局池化,增强了卷积间的联系性
- 避免了过拟合的发生
- 每个特征图就是一个输出,所以在设计网络时,分类个数要与最后一层特征图个数保持一致。
5、实验分析
网络设计
- 3层Mlpconv
- 2倍的空间最大池化下采样
- dropout(除最后一个Mlpconv)
训练参数
- 手动设置参数
- batch size=128
- weight decay
- 精度不改善时,学习率更新为1/10,学习率最终为初始值的百分之一。
CIFAR10
1 、数据集介绍
- 10类
- 50000 训练集,10000测试集
- RGB图像,32*32大学
- ZCA白化处理[详细介绍,请参考最后参考博客1]
- 白化是一种重要的预处理过程,其目的就是降低输入数据的冗余性,使得经过白化处理的输入数据具有如下性质:
- 特征之间相关性较低;
- 所有特征具有相同的方差。
- 白化处理分PCA白化和ZCA白化,PCA白化保证数据各维度的方差为1,而ZCA白化保证数据各维度的方差相同。
- PCA白化可以用于降维也可以去相关性,而ZCA白化主要用于去相关性,且尽量使白化后的数据接近原始输入数据。
2、实验分析
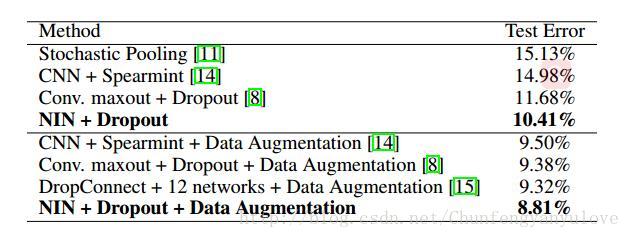
- 利用本文方法,可以达到较好的精度
- dropout对精度提升具有一定帮助
- translation and horizontal flipping augmentation数据集扩增,对精度提升有帮助
-
CIFAR100
相似与CIFAR10数据集,图像规模相同,不过包含100类。
作者使用CIFAR10相同的模型进行测试,结果如下图:

Street View House Numbers
SVHN数据库由630420个32x32的彩色图片组成。分成训练集、测试集和额外集。作者训练和测试的过程与Goodfellow相同。具体而言是,对于每一类,从训练集中选择400个样本,再从额外集中选择200个样本用于验证,训练集与和额外集中其余的样本用于训练,组成的验证集仅仅用于超参的选择,不会在训练过程中使用。

MNIST
MNIST测试结果如下,由于MNIST数据较少,效果没有达到最好。

6、全局平均池化正则化
1、全局平均池化与全连接相似,不同点在于变换矩阵。
全局平均池化来说,转换矩阵被置于前面(/前缀)并且其块对角元素是非零相同值,而全连接层可以有密集的转换矩阵并且其值易于反向传播优化
2、作者为验证全局平均池化的效果,作者利用全局平均池化替代全连接层,在CIFAR10数据集进行实验。实验说明,全连接层效果最差,增加dropout后效果有提升,利用全局平均池化效果最好。
3、作者实验验证全局平均池化是否与CNN同样具有正则化能力,实验结果表明,全局平均池化具有一定的正则化能力,但实验效果较CNN差了一些。
7、NIN的可视化
作者显示了用于CIFAR10上的模型中最后一层MLPconv的特征映射图,进一步说明了NIN的效果。
参考博客1:https://www.jianshu.com/p/96791a306ea5
参考博客2:http://blog.csdn.net/hjimce/article/details/50458190