Prometheus监控学习之路(一)
Prometheus监控学习之路
监控系统发展史
-
SNMP监控时代
第一代监控时代,主要以网络流量以及网络设备为主,但需要网络设备内置SNMP协议 -
当今的监控时代
zabbix、Prometheus、nagios等等 -
未来的监控时代
DataOps、AIOps
系统监控组件
- 指标数据采集
- 指标数据存储
- 指标数据趋势分析及可视化
- 告警
监控体系(自下向上)
- 系统层监控
系统监控:CPU、Load、Memory、Swap、DiskIO、KernelParameters等等;
网络监控:网络设备、工作负载、网络延迟、丢包率; - 中间件及基础设施类系统监控
消息中间件:kafka、RockerMQ和RabbitMQ等;
Web服务器:Tomcat、nginx和Jetty等;
数据库及缓存系统:MySQL、MongoDB、Elasticsearch和Redis等;
数据库连接池:ShardingSpere等;
存储系统:NFS、Ceph等; - 应用层监控系统
用于衡量应用程序代码的状态和性能; - 业务层监控
QPS、DAU日活、转化率;
业务接口:登录数、注册数、订单量、搜索和支付量等;
用于衡量应用程序的价值,例如电子商务网站上的销售数据;
云原生时代的可观测性
- 可观测性系统
指标监控(Metrics):随时间推移产生的一些与监控相关的可聚合数据点;
日志监控(Logging):离散式的日志或事件;
链路跟踪(Tracing):分布式应用调用链跟踪; - CNCF将可观测性和数据分析归类一个单独的类别
监控系统:以Prometheus等为代表;
日志系统:以ElasticStack和PLG Stack等为代表.;
分布式调用链跟踪系统:以ZipKin、Jaeger、SkyWalking、Pinpoint等为代表;
混沌工程系统:以ChaosMonkey和ChaosBlade等为代表;
著名的监控方法论
- Google的四个黄金指标
常用于在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题
适用于应用及服务监控 - Netflix的USE方法
全称为“Utilization Saturation and Errors Method”
主要用于分析系统性能问题,可以指导用户快速识别资源瓶颈以及错位的方法
应用与主机指标监控 - WeaveCloud的RED方法
WeaveCloud基于Google的四个黄金指标的原则下结合Prometheus以及kubernetes容器实践,细化和总结的方法论,特别适合于云原生应用以及微服务架构应用的监控和度量
黄金指标
四个黄金指标源自Google的SRE一书
- 延迟(Latency)
服务请求所需要的的时长,例如HTTP请求平均延迟;
需要区分失败请求和成功请求; - 流量(Traffic)
衡量服务的内容量需求,例如每秒处理的HTTP请求数或者数据库系统的事务数量; - 错误(Errors)
请求失败的速率,用于衡量错误发生的情况。例如HTTP500错误数等显示失败,返回错误内容或无效内容等隐式失败,以及由策略原因导致的失败(例如强制要求相应时间超过30毫秒的请求视为错误); - 饱和度(Saturation)
衡量资源的使用情况,用于表达应用程序有多“满”,例如内存、CPU、I/O、磁盘等资源的使用量
USE方法
UES方法由Netflix的内核和性能工程师RenDan Gregg提出,主要用于分析系统性能问题
- 使用率(Utilization)
关注系统资源的使用情况。这里的资源主要包括但不限于:CPU、内存、网络、磁盘等;
100%的使用率通常是系统性能瓶颈的标志; - 饱和度(Saturation)
例如CPU的平均运行排队长度,这里主要是针对资源的饱和度(注意,不同于4大黄金信号);
任何资源在某种程度上的饱和都可能导致系统性能的下降; - 错误(Errors)
错误计数,例如:网卡在数据包传输过程中检测到的以太网网络冲突了14次
RED方法
RED方法是WeaveCloud在基于Googl的4个黄金指标的原则下结合Prometheus以及kubernetes容器实践细化和总结的方法论,特别适合于云原生应用以及微服务架构应用的监控和度量。
在四大黄金指标的原则下,RED方法可以有效地帮助用户衡量云原生以及微服务应用下的用户体验问题。
RED方法主要关注一下3种关键指标:
- (Request)Rate:每秒接收的请求数;
- (Request)Errors:每秒失败的请求数;
- (Request)Duration:每个请求所花费的时长;
Prometheus快速入门
What is Prometheus Monitoring
首先,Prometheus是一款时序(time series)数据库;但他的功能却并非止步于TSDB,而是一款设计用于进行目标(Target)监控的关键组件;结合生态系统内的其它组件,例如Pushgateway、Altermanager和Grafana等,可构成一个完整的IT监控系统。
时序数据简介
时序数据,是在一段时间内通过重复测量(measurement)而获得的观测值的集合;将这些观测值绘制于图形之上,他会有一个数据轴和一个时间轴;
服务器指标数据、应用程序性能监控数据、网络数据等也都是时序数据库;
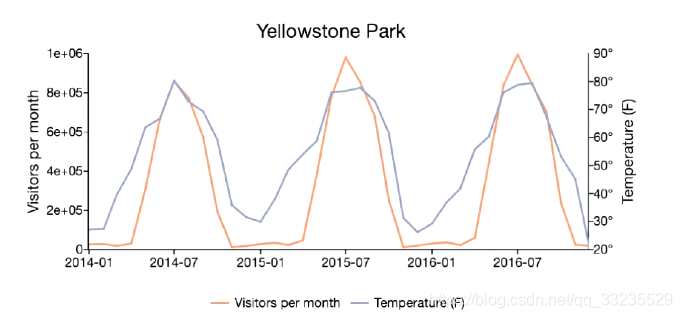
Prometheus能做什么
基于HTTP call,从配置文件中指定的网路端点(endpoint)上周期性后去指标数据
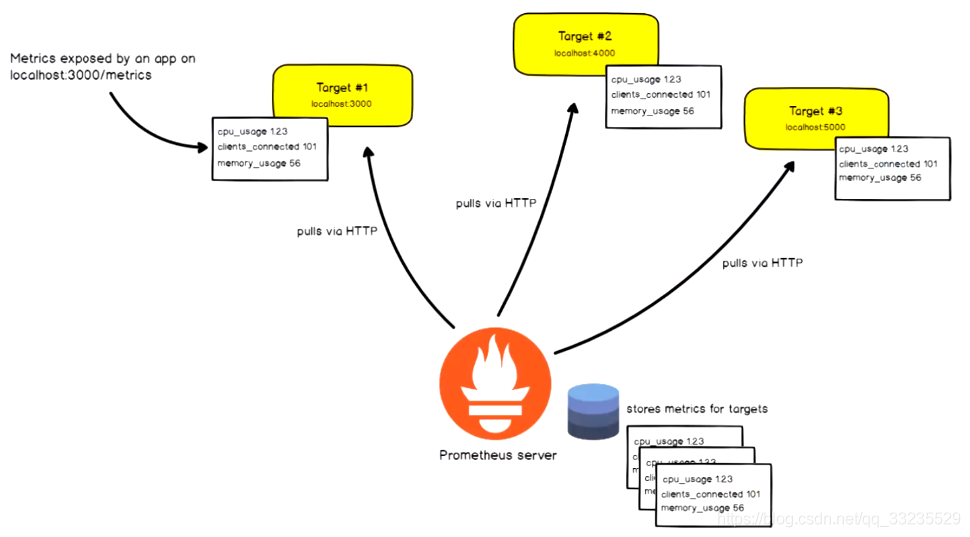

Prometheus工作原理
Prometheus支持通过三种类型的途径从目标上“抓取(Scrape)”指标数据;
- Exporters:获取指标数据的获取器(收集客户端服务数据)
- Instrumentation:测量系统(系统内嵌了符合Prometheus指标数据格式的数据)
- Pushgateway:客户端将数据推送给Pushgateway,然后Prometheus获取Pushgateway中的数据
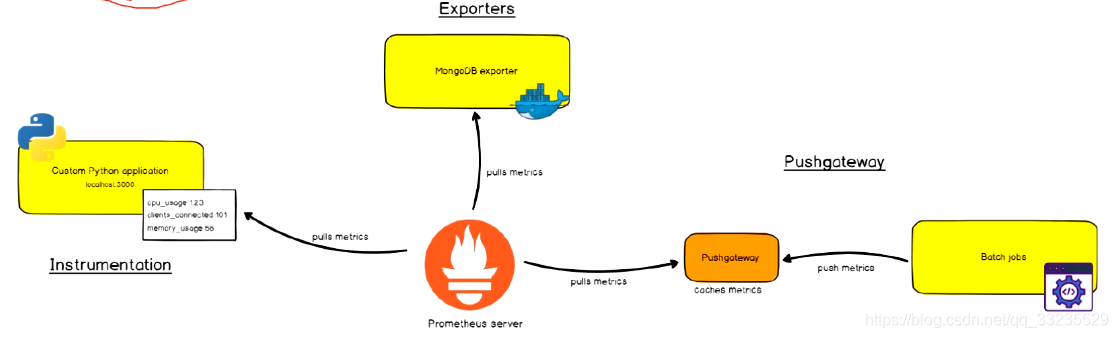
拉取数据与推送数据(Pull and Push)
Prometheus同其他TSDB相比有一个非常典型的特性:他主动从个Target上“拉取(Pull)”数据,而非等待被监控端“推送(Push)”。
这两个方式各有优劣,其中Pull模型的优势在于:
- 集中控制:有利于将配置集中在Prometheus上完成,包括指标及采取速率等
- Prometheus的根本目标在于收集在Target上预先完成聚合的聚合型数据,而非一款由事件驱动的存储系统
Prometheus的生态组件
Prometheus负责时序型指标数据的采集及存储,但数据的分析、集合及直观展示以及告警等功能并非由PrometheusServer所负责
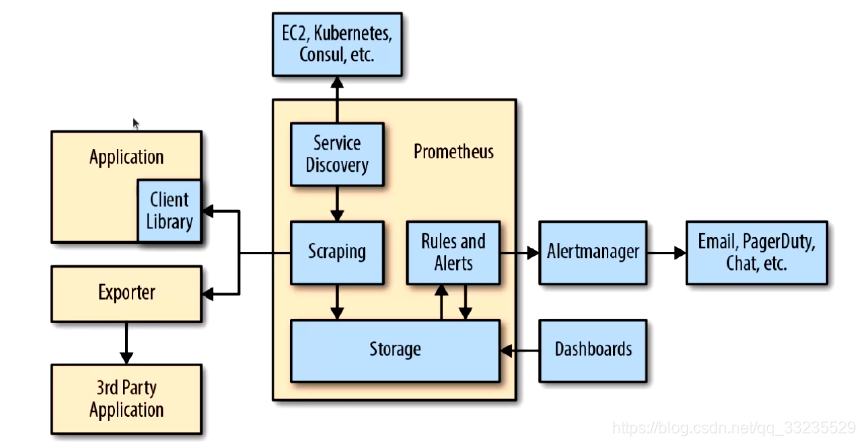
Prometheus生态圈中包含了多个组件,其中部分组件可选
- Prometheus Server:收集和存储时间序列数据
- Client Library:客户端库,目的在于为那些期望原生提供Instrumentation功能的应用程序提供便捷的开发途径
- PushGateway:接收那些通常由短期作业生成的指标数据的网关,并支持由PrometheusServer
- Alertmanager:从Prometheus接收到“告警通知”后,通过去重、分组、路由等预处理功能后以高效向用户完成告警信息发送
- DataVisualization:PrometheusWebUI(PrometheusServer内建),及Grafana等
- ServiceDiscovery:动态发现待监控的Target,从而完成监控配置的重要组件,在容器化环境中尤为有用,该组件目前由PrometheusServer内建支持
Prometheus数据模型
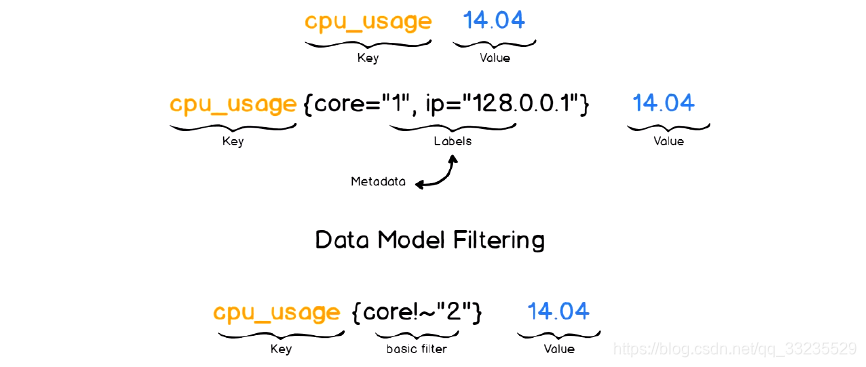
Prometheus仅用于以“键值”形式存储时序式的聚合数据,他并不支持存储文本信息
- 其中的“键”成为指标(Metric),他通常意味着CPU速率、内存使用率或分区空闲比例等
- 同一指标可能会适配到多个目标或设备,因而他使用“标签”作为元数据,从而为Metric添加更多的信息描述围堵
- 这些标签还可以作为过滤器进行指标过滤及聚合运输
指标类型(MetricTypes)
Prometheus使用4种方法来描述监视的指标
- Counter:计数器,用于保存单调递增型的数据,例如站点访问次数等;不能为负值,也不支持减少,但可以重置回0
- Gauge:仪表盘,用于存储有着起伏特征的指标数据,例如内存空闲大小等
Gauge是Counter的超集,但存在指标数据丢失的可能性时,Counter能让用户确切了解指标随时间的变化状态,而Gauge则可能随时间流逝而精准度越来越低 - Histogram:直方图,他会在一段时间范围内对数据进行采样,并将其计入可配置的bucket之中。Histogram能够存储更多的信息,包裹样本值分布在每个bucket(bucket自身可配置)中的数量、所有样本值之和以及总的样本数量,从而Prometheus能够使用内置的函数进行如下操作:
1.计算样本均值:以值得总和除以值得数量
2.计算样本分位值:分位数有助于了解符合特定标注的数据个数。例如评估响应时长超过1秒钟的请求比例,若超过20%即发送告警 - Summary:摘要,Histogram的扩展类型,但他是直接由被检测端自行聚合计算出分位数,并将计算结果响应给PrometheusServer的样本采集请求。因而,其分位数计算是由监控端完成
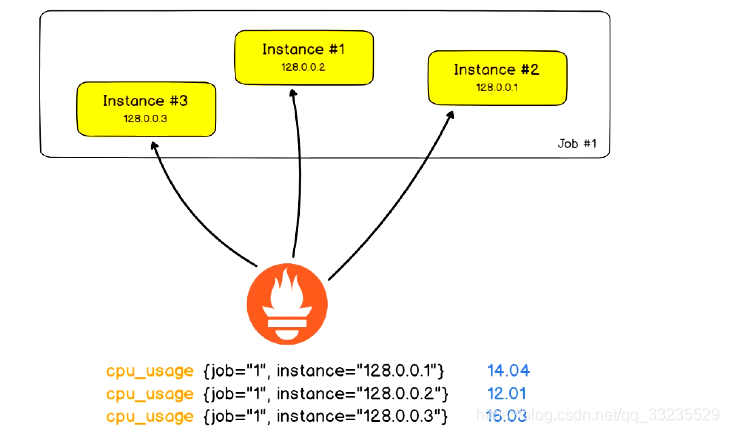
作业(Job)和实例(Instance)
Instance:能够接收PrometheusServer数据Scrape操作的每个网络端点(endpoint),即为一个Instance(实例)。通常,具有类似功能的Instance的集合称为一个Job,例如一个MySQL主从复制集群中的所有MySQL进程。
PromQL
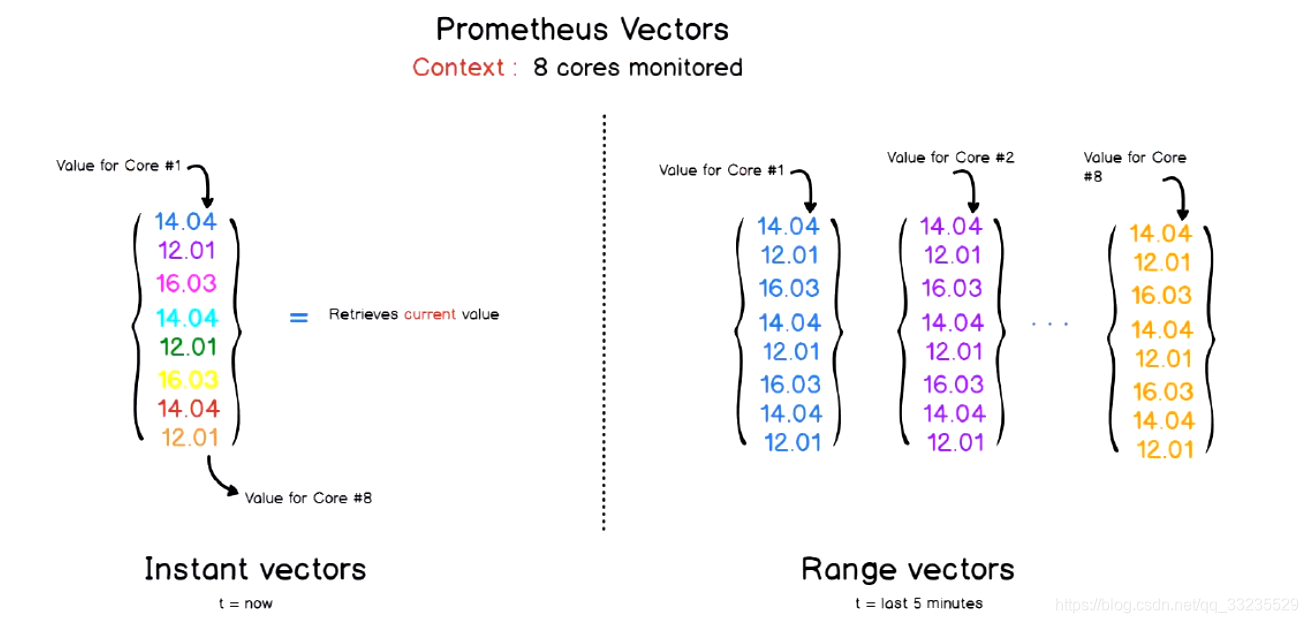
Prometheus提供了内置的数据查询语言PromQL(全称为PrometheusQueryLanguage),支持用户进行实时的数据查询及聚合操作。
PromQL支持处理两种向量,并内置提供了一组用于数据处理的函数:
- 即时向量:最近一次的时间戳上跟踪的数据指标
- 时间范围向量:指定时间范围内的所有时间戳上的数据指标
Alerts
抓取到异常值后,Prometheus支持通过“告警(Alert)”机制向用户发送反馈或警示,以触发用户能够即时采取应对措施
PrometheusServer仅负责生产告警指示,具体的告警行为由另一个独立的应用程序AlertManager负责
- 告警指示由PrometheusServer基于用户提供的“告警规则”周期性计算生成
- Alertmanager接收到PrometheusServer发来的告警指示后基于用户定义的告警路由向告警接收人发送告警信息
部署Prometheus
获取软件包
- 获取PrometheusServer软件包
官方下载地址:https://prometheus.io/download/
下载后上传至服务器中解压至“/usr/local”下
tar xf prometheus-2.24.1.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/prometheus-2.24.1.linux-amd64 /usr/local/prometheus
启动服务
cd /usr/local/prometheus
./prometheus
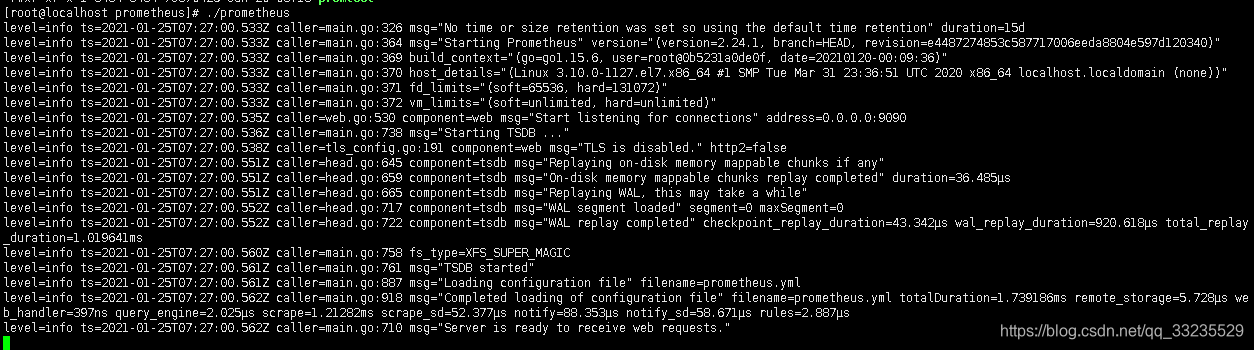
访问IP地址+9090
- 查看可收集指标数据
访问IP地址+9090/metrics

收集被监控端指标数据
- 获取node_exporter软件包

tar xf node_exporter-1.0.1.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/node_exporter-1.0.1.linux-amd64 /usr/local/node_exporter
cd /usr/local/node_exporter/
./node_exporter

也可以通过“–help”查看收集那些指标
配置Prometheus搜集数据
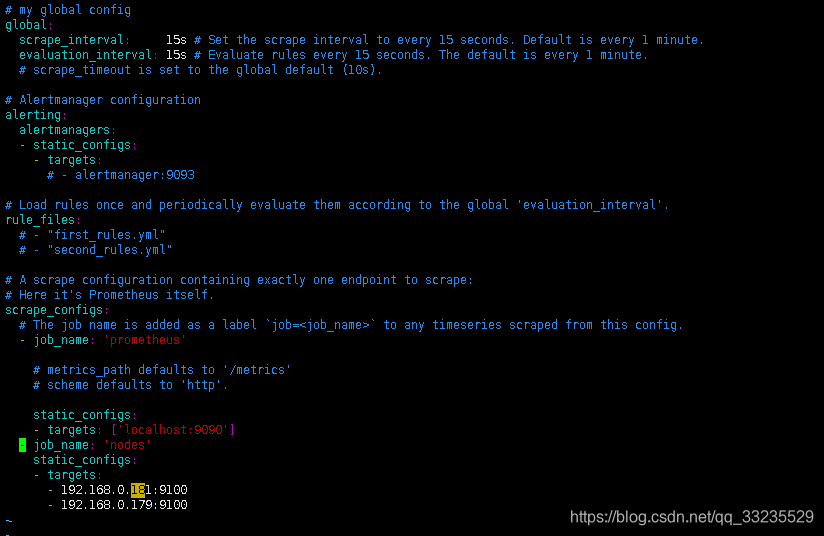
修改Prometheus配置文件,在行尾加入
vim /usr/local/prometheus/prometheus.yml
- job_name: 'nodes'
static_configs:
- targets:
- 192.168.0.181:9100
- 192.168.0.179:9100
重启Prometheus,并访问
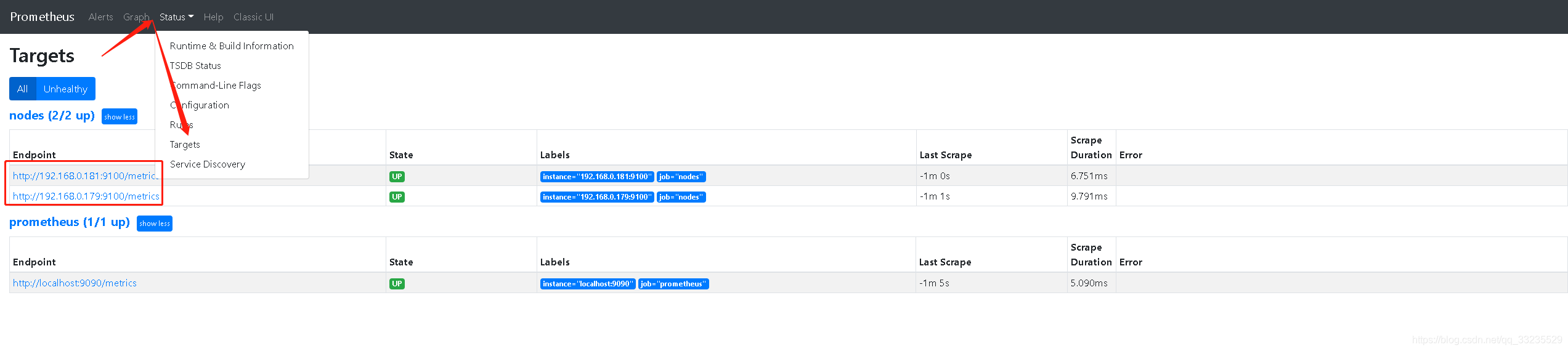
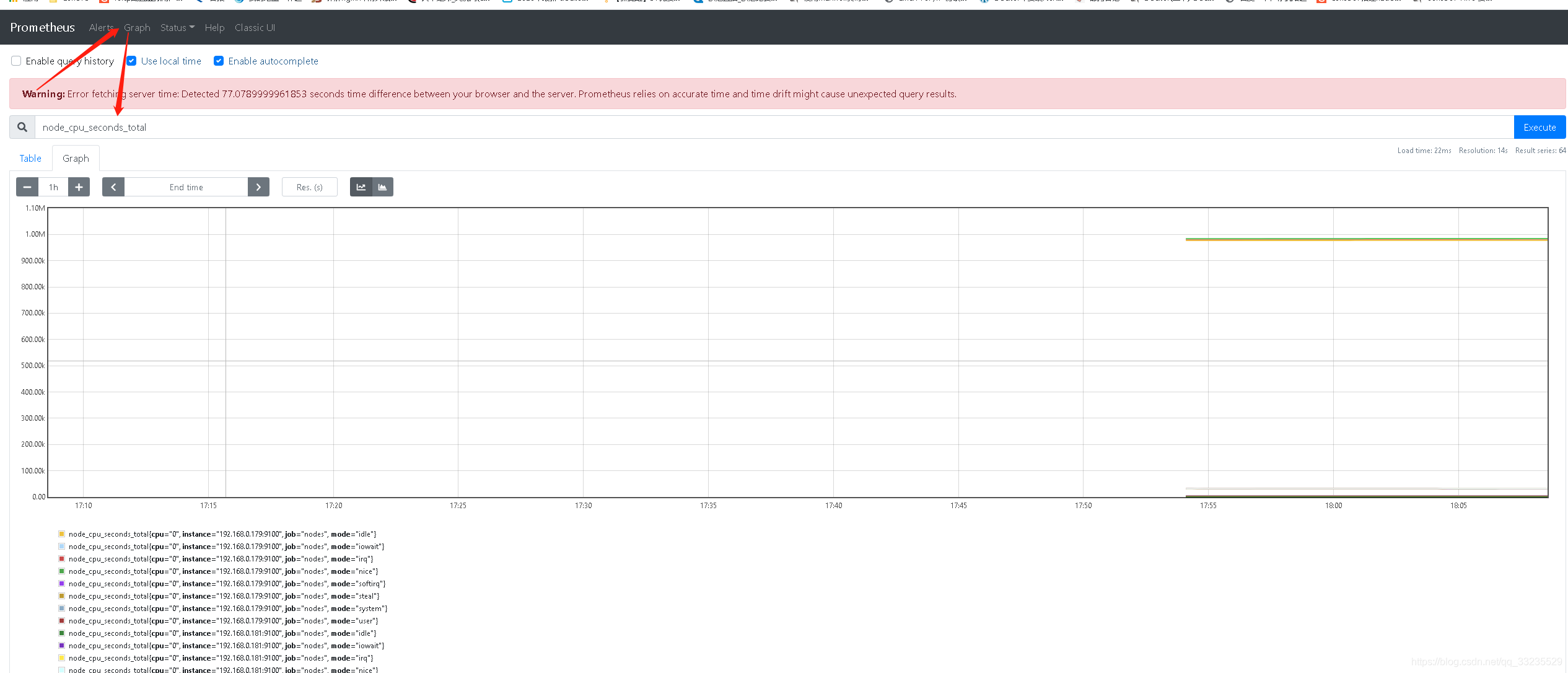
Prometheus的服务发现
Prometheus的服务发现有两种方式一是静态配置,另一种方式是动态发现
- 静态配置:静态配置如上文的直接在配置文件中添加target即可
- 基于配置文件动态发现:通过配置多个配置文件Prometheus自动刷新监听该目录下的配置文件。修改Prometheus主配置文件
vim /usr/local/prometheus/prometheus.yaml
- job_name: 'file-nodes'
file_sd_configs:
- files:
- /usr/local/prometheus/target/*.yaml
refresh_interval: 2m
然后创建target文件
vim /usr/local/prometheus/target/node.yaml
- targets:
- 192.168.0.181:9100
labels:
app: prometheus
job: node

再修改node.yaml添加新的节点主机ip
vim /usr/local/prometheus/target/node.yaml
- targets:
- 192.168.0.181:9100
- 192.168.0.179:9100
labels:
app: prometheus
job: node
等待两分钟左右刷新Prometheusweb页面查看
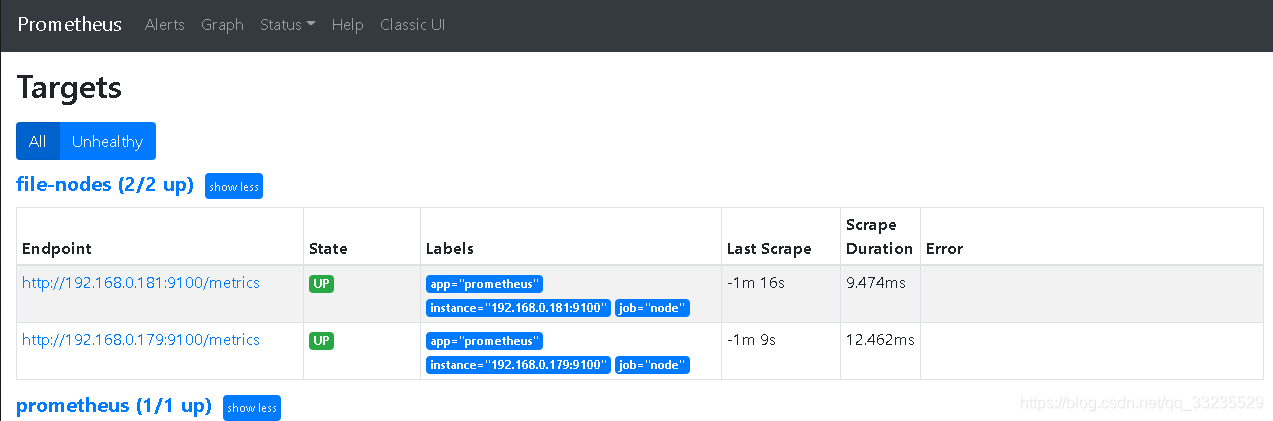
- 动态的服务发现还支持基于consul和DNS的服务发现
以consul为例Prometheus配置文件
vim /usr/local/prometheus/prometheus.yaml
- job_name: 'consul-node'
consul_sd_configs:
- server: "192.168.0.181:8500"
tags:
- "nodes"
refresh_interval: 2m
配置节点信息到consul配置文件中
vim /etc/consul/node.json
{
"services": {
{
"id": "node_181",
"name": "node181",
"address": "192.168.0.181",
"prot": "9100",
"tags": "nodes",
"checks": [{
"http": "http://192.168.0.181:9100/metrics",
"interval": "5s"
}]
},
{
"id": "node_179",
"name": "node179",
"address": "192.168.0.179",
"prot": "9100",
"tags": "nodes",
"checks": [{
"http": "http://192.168.0.179:9100/metrics",
"interval": "5s"
}]
}
}
}
启动consul
consul agent -dev -ui -data-dir=/consul/data -config-dir=/etc/consul/