spring batch 扩展性
github地址:
https://github.com/a18792721831/studybatch.git
文章列表:
可扩展性
可扩展性(可伸缩性)是一种对软件系统计算处理能力的设计指标,高可扩展性代表一种弹性,在系统扩展成长过程中,软件能够保证旺盛的生命力,通过很少的改动甚至只是硬件设备的添置,就能实现整个系统处理能力的线性增长,实现高吞吐量和低延迟高性能。
软件系统的扩展通常可以通过如下的两种方式实现,垂直扩展、水平扩展 。
垂直扩展是通过升级原有的服务器或者为当前的应用更换更强大的硬件来实现系统处理能力的增强。比如为当前的服务器增加更大的内存、存储、处理器资源等。垂直扩展通常要求提供更强大的服务器资源来达到增加软件处理的能力;通过更换更强的服务器可以方便地实现软件系统的可扩展性,但是这种便利性同时也有较大的局限性,毕竟这种处理能力的增加是有限的,因为单个服务器的处理能力毕竟最终是有限的。垂直扩展是通过升级原有的服务器或者为当前的应用更换更强大的硬件来实现系统处理能力的增强。比如为当前的服务器增加更大的内存、存储、处理器资源等。垂直扩展通常要求提供更强大的服务器资源来达到增加软件处理的能力;通过更换更强的服务器可以方便地实现软件系统的可扩展性,但是这种便利性同时也有较大的局限性,毕竟这种处理能力的增加是有限的,因为单个服务器的处理能力毕竟最终是有限的。
水平扩展指的是通过增加更多的服务器来分散负载,可以将多个服务器从逻辑上看成一个实体,从而实现存储能力和计算能力的扩展。比如,可以简单地通过聚类或负载平衡策略,通过增加多个服务器来加快整个逻辑实体的运行速度及性能。
Spring Batch框架提供了多种提高Job并行处理、扩展性的方式。通常情况下只需要调整Job的配置就可以达到扩展处理Job的目的。需要注意的是框架提供了在Step级别进行任务的扩展能力。
spring batch提供的扩展能力
| 扩展模式 | Local/Remote | 说明 |
|---|---|---|
| MultithreadedStep多线程作业步 | Local | Step可以使用多线程执行(通常一个Step是由一个线程执行的) |
| ParallelStep并行作业步 | Local | Job执行期间,不同的Step并行处理,由不同的线程执行(通常job的step是顺序执行,且由一个线程执行) |
| PartitioningStep分区作业步 | Local/Remote | 通过将任务进行分区,不同的Step处理不同的任务数据达到提高Job效率的功能 |
| RemoteChunking远程任务 | Remote | 将任务分发到远程不同的节点进行并行处理,提高Job的处理速度和效率 |
多线程Step
批处理框架在Job执行时默认使用单个线程完成任务的执行,同时框架提供了线程池的支持,可以在Step执行时候进行并行处理,这里的并行是指同一个Step使用线程池进行执行,同一个Step被并行地执行。使用tasklet 的属性 task-executor可以非常容易地将普通的Step变成多线程Step。
多线程step的关键属性
| 属性 | 说明 | 默认值 |
|---|---|---|
| task-executor | 任务执行处理器,定义后表示采用多线程执行任务,需要考虑多线程执行任务时候的安全性 | |
| throttle-limit | 最大使用线程池的数目 | 6 |
配置多线程Step
假设我们有一个Job,这个Job里面有1个step,这个stpe里面是tasklet,在tasklet中,需要循环20次,每次循环需要睡眠10秒
这样,整个step执行完成需要200秒,最少,加上spring batch框架自己调度等等需要的时候,最终需要的时间可能远远大于200秒。
比如这样的一个step

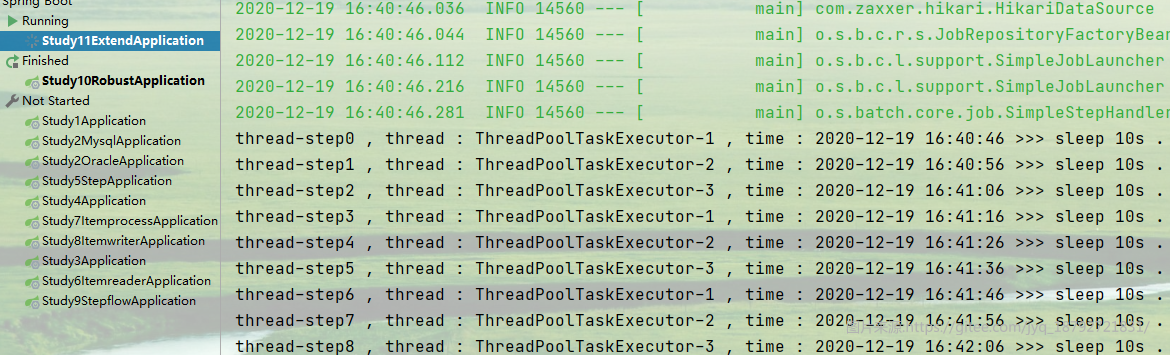
我首先使用默认的执行方式(单线程串行执行),看看需要多长时间
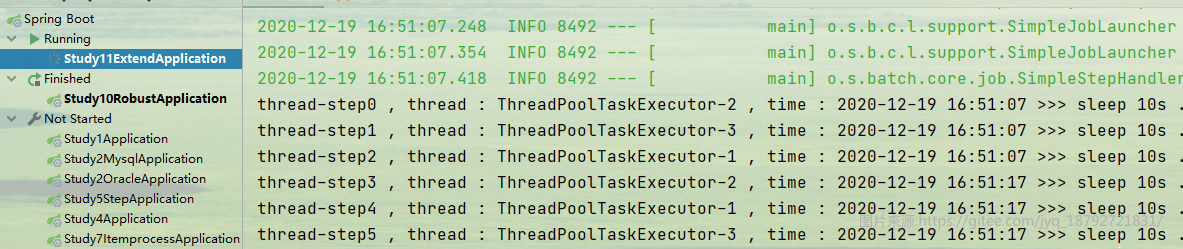
执行结果,第一个step开始
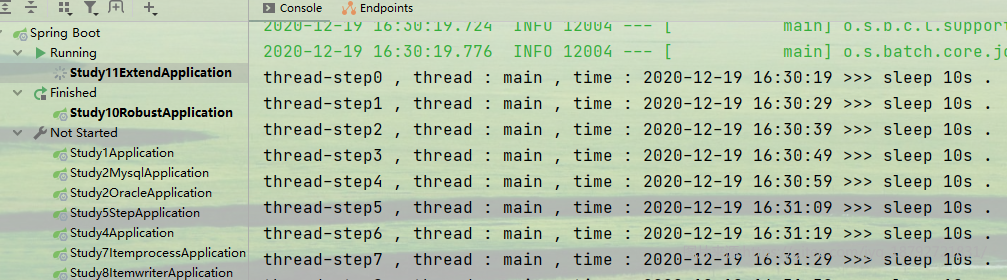
直到20次循环后结束
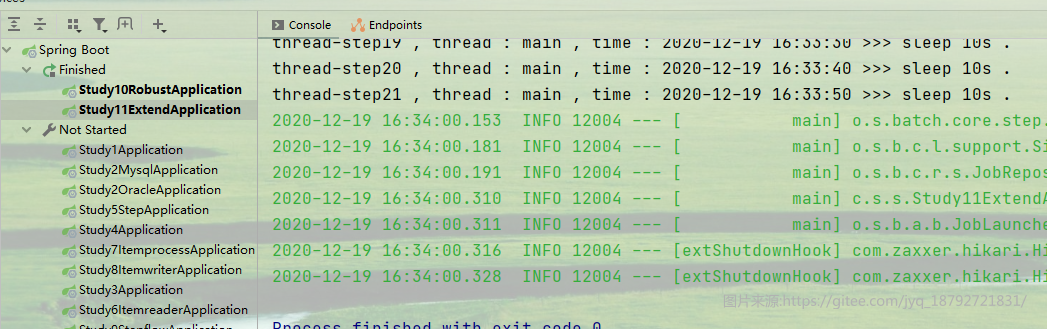
如果我们使用多线程呢?
首先创建一个线程池,最大线程数量是3,初始线程数量是3,等待队列初始化为15
接着配置step使用这个线程池
然后执行,我们期望的目标是并行执行,这样只需要70秒就搞定了

但是很明显,结果又一次出乎意料。

这样配置,线程是不安全的。主要是我们使用AtomicInteger的方式不对
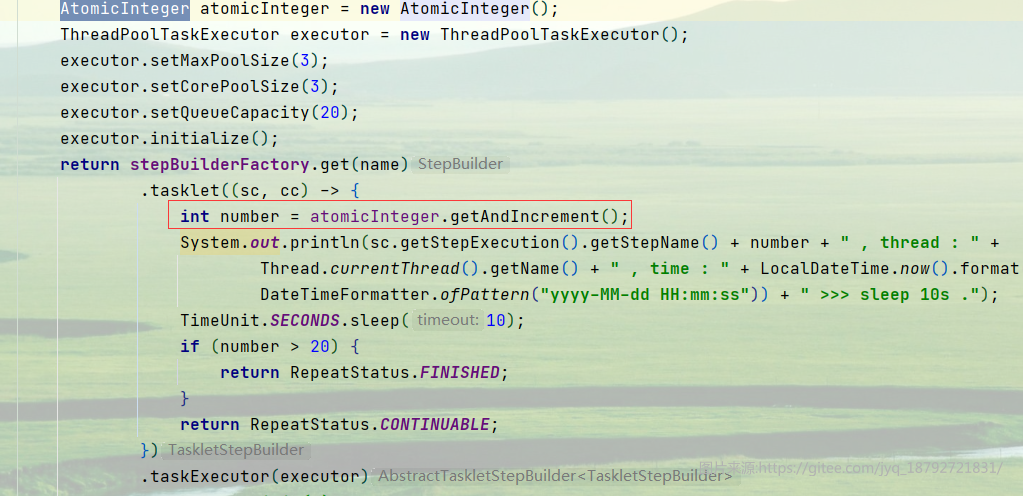
AtomicInteger应该只被调用一次。
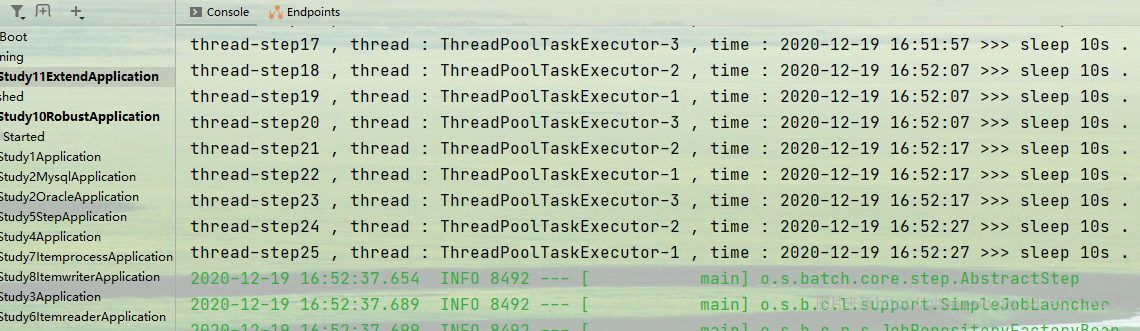
但是,即使这样,还是发现存在线程安全问题。
除此之外,我们还可以配置,在线程池的基础上,step中的tasklet允许的并发量
比如
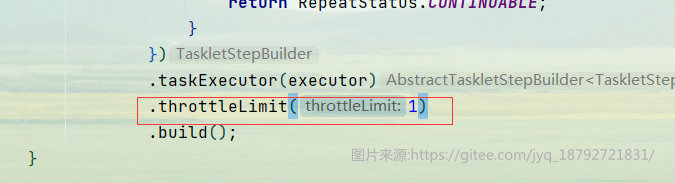
整个step中的tasklet执行又变成了单线程了
也可以指定并发量为2
这是并发量就是2个线程执行了
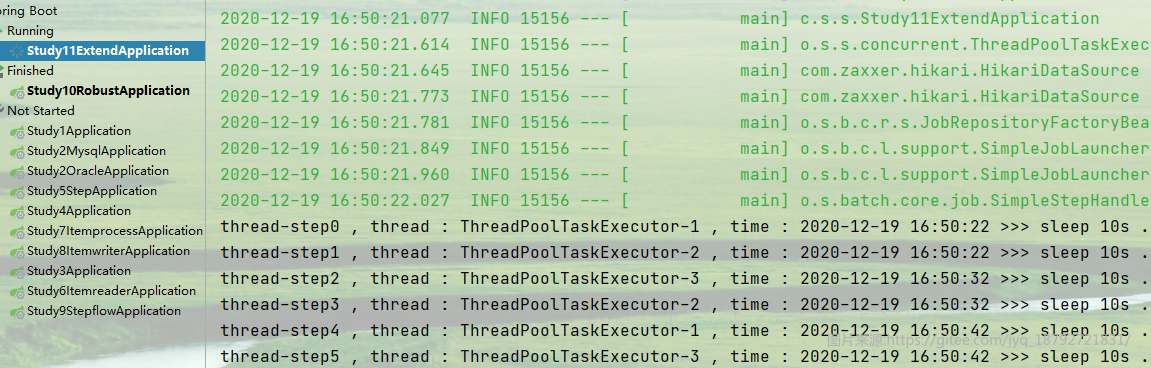
线程安全性
但是,我们从上面也看到了一个问题,即使我们使用了线程安全的对象,但是因为线程执行的速度还是有差异,就导致,即使其中一个线程发出了结束的信号,但是其他线程并不会收到影响。
必须全部的线程都自己达到结束的条件,整体才会结束。和预期结果还是有所不同的。
线程安全Step
目前为止,spring batch提供的ItemReader,ItemProcess和ItemWriter都不是线程安全的。只有SynchronizedItemStreamReader是线程安全的。
主要是在read方法上使用synchronized关键字来保证线程安全
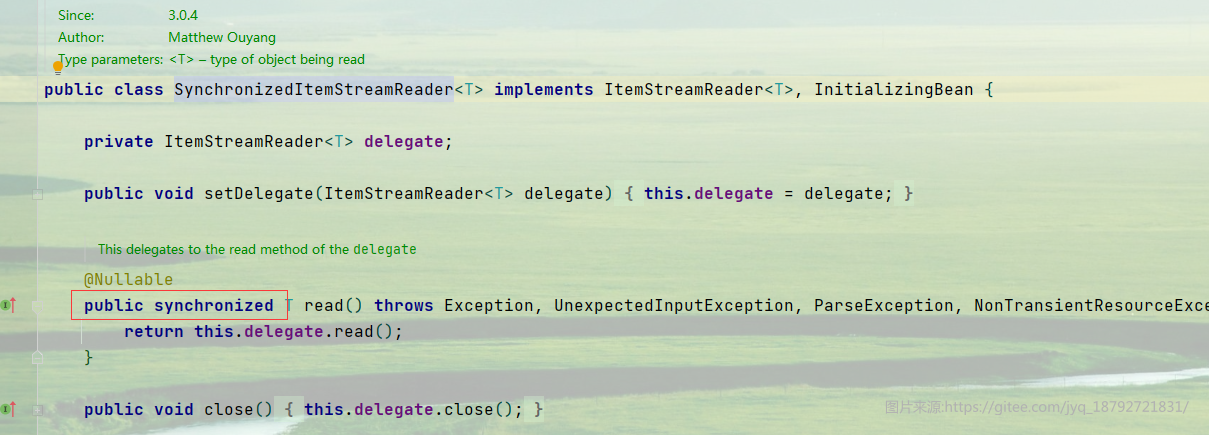
同样的ItemWriter有SynchronizedItemStreamWriter。
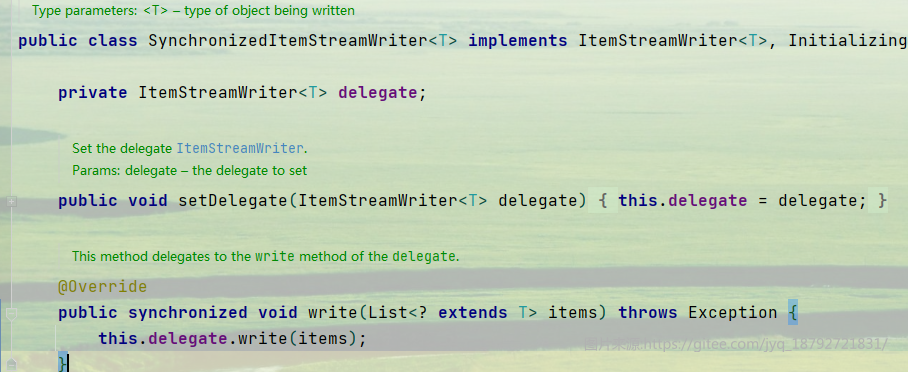
但是需要注意,ItemProcessor是没有的。
至于tasklet和ItemProcessor也想实现线程安全,那么只能自己实现接口了。
使用synchronized关键字实现线程安全。
比如上面的例子,我们用自定义的线程安全的方式执行

使用
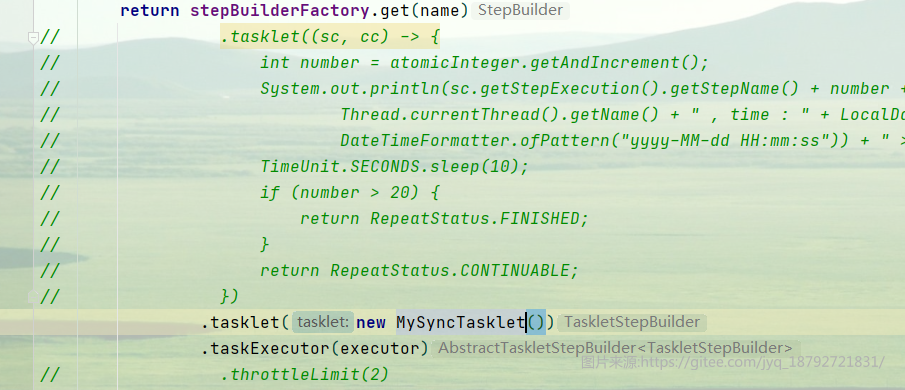
执行,很可惜,在方法级别上加上synchronized关键字,就又变成单线程的了

但是,加上synchronized也至少保证了线程安全。
并行Step
多线程步提供了多个线程执行一个Step 的能力,但这种场景在实际的业务中使用的并不是非常多。更多的业务场景是Job中不同的Step没有明确的先后顺序,可以在执行期间并行地执行。Spring Batch框架提供了并行Step 的能力。可以通过Split元素来定义并行的作业流,并制定使用的线程池。
批处理任务中有些任务有先后的执行顺序,还有些Step没有先后执行顺序的要求,可以在同一时刻并行作业,批处理框架提供了并行处理Step 的能力,通过Split元素可以定义并行的作业流,为split定义执行的线程池,从而提高Job的执行效率。
Spring Batch框架提供了split元素来执行并行作业的能力。
split元素关键属性
| 属性 | 说明 | 默认值 |
|---|---|---|
| id | 定义split的唯一ID,全局需要保证 id 唯一 | |
| task-executor | 任务执行处理器,定义后表示采用多线程执行任务,需要考虑多线程执行任务时候的安全性 | 如果不定义的话,默认使用同步线程执行器:SyncTaskExecutor |
| next | 当前split中所有的flow执行完毕后,接下来执行的Step |
split元素
| 属性 | 说明 |
|---|---|
| flow | 用来定义并行处理的作业,并列的flow表示可以并行处理的任务; split元素下面可以定义多个flow节点 |
| next | 根据退出状态定义下一步需要执行的Step |
| stop | 根据退出状态决定是否退出当前的任务,同时Job也会停止,作业状态为"“STOPPED” |
| fail | 根据退出状态决定是否失败当前的任务,同时Job也会停止,作业状态为"FAILED" |
| end | 根据退出状态决定是否结束当前的任务,同时Job也会停止,作业状态为"COMPLETED" |
我们用一个例子体验。有两组step需要执行,每组step有3个step,每个step需要睡眠10秒钟。
这两组step并行执行。组内的step串行执行。
换句话说,我们有两个Flow,每个Flow包含3个step。每个step睡眠10秒。
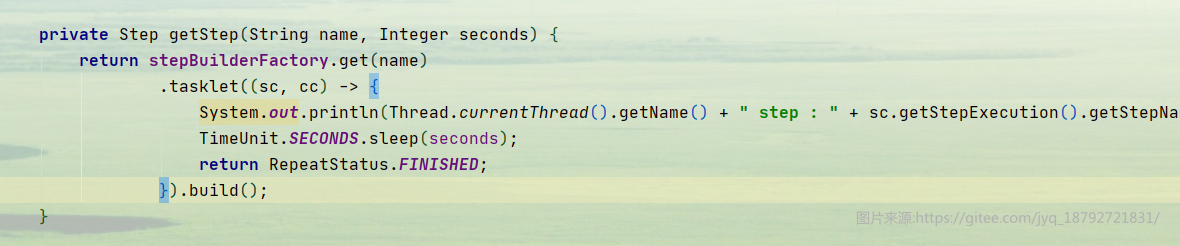
首先我们创建一个睡眠step的创建方法
接着创建一个线程池(并行执行,肯定需要线程池)

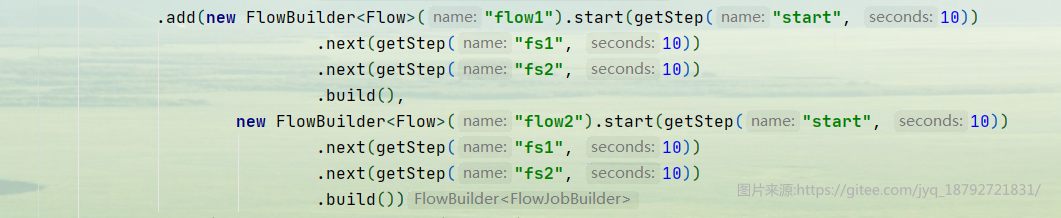
然后我们创建两个flow
为了保证服务正确的被停止,我们增加一个step,当并行任务执行完毕后,用于关闭线程池
所以,完整的定义如下

完整的代码
@Component
public class SplitFlowStepJobConf {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private JobLauncher jobLauncher;
@PostConstruct
public void runJob() throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job(), new JobParametersBuilder().addDate("date", new Date()).toJobParameters());
}
private Job job() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setMaxPoolSize(3);
executor.setCorePoolSize(3);
executor.initialize();
return jobBuilderFactory.get("split-flow-step-job")
.start(getStep("init", 5))
.split(executor)
.add(new FlowBuilder<Flow>("flow1").start(getStep("start", 10))
.next(getStep("fs1", 10))
.next(getStep("fs2", 10))
.build(),
new FlowBuilder<Flow>("flow2").start(getStep("start", 10))
.next(getStep("fs1", 10))
.next(getStep("fs2", 10))
.build())
.next(stepBuilderFactory.get("clean")
.tasklet((sc, cc) -> {
executor.shutdown();
return RepeatStatus.FINISHED;
}).build())
.on("x").stop()
.on("xx").fail()
.on("xxx").end()
.build().build();
}
private Step getStep(String name, Integer seconds) {
return stepBuilderFactory.get(name)
.tasklet((sc, cc) -> {
System.out.println(Thread.currentThread().getName() + " step : " + sc.getStepExecution().getStepName() + " time : " + LocalDateTime.now().format(DateTimeFormatter.ofPattern("YYYY-MM-dd HH:MM:SS")) + " run >>>>> sleep : " + seconds);
TimeUnit.SECONDS.sleep(seconds);
return RepeatStatus.FINISHED;
}).build();
}
}
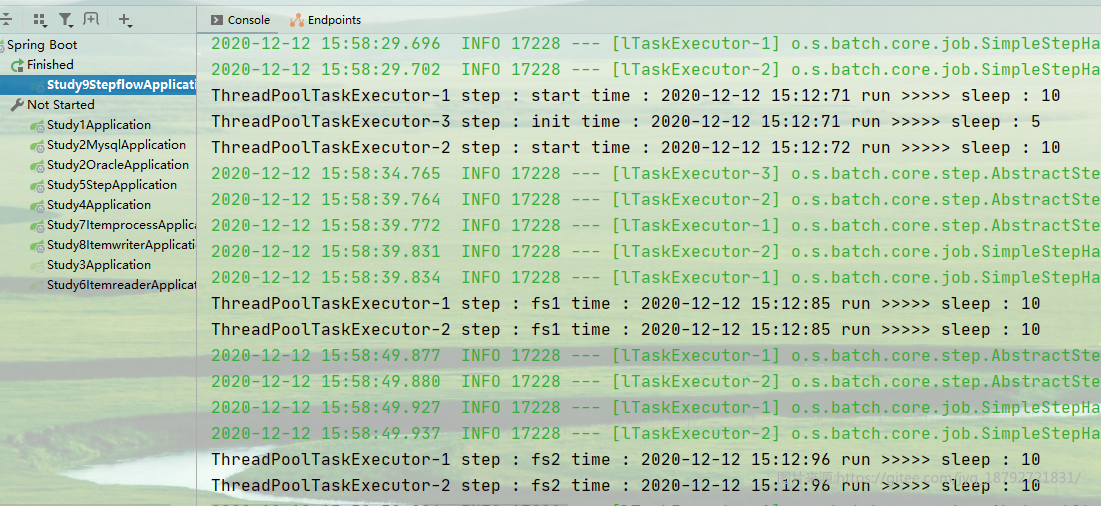
执行结果
远程Step
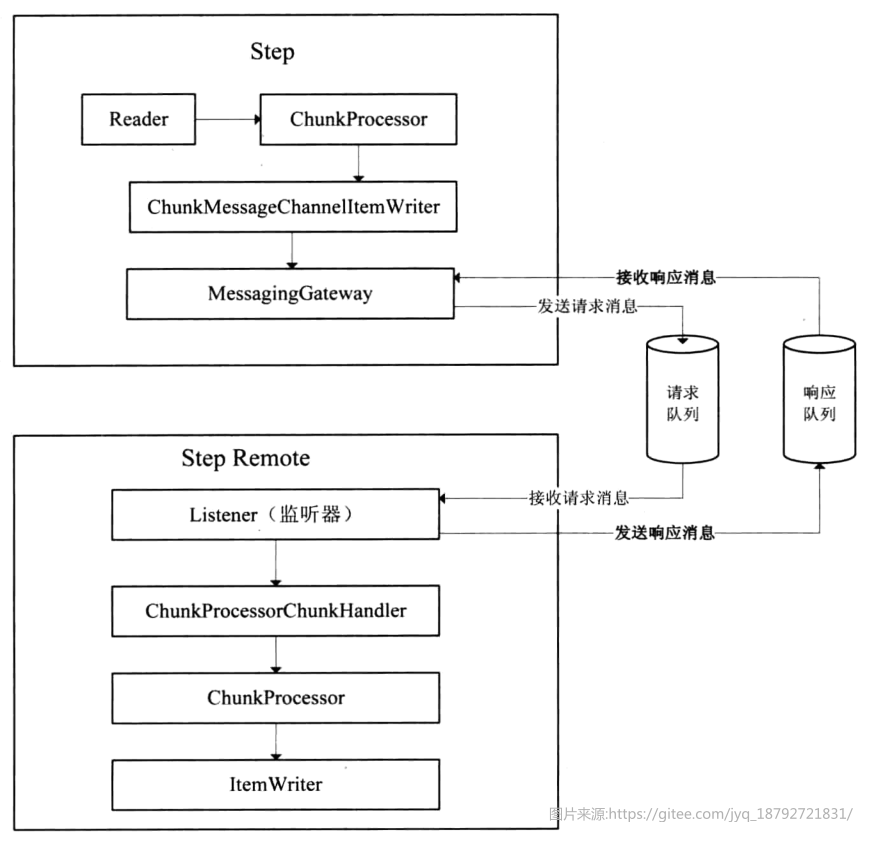
远程分块是一个把 step进行技术分割的工作,不需要对处理数据的结构有明确了解。任何输入源都能够使用单进程读取并在动态分割后作为"块"发送给远程的工作进程。远程进程实现了监听者模式,反馈请求、处理数据,最终将处理结果异步返回。请求和返回之间的传输会被确保在发送者和单个消费者之间。Spring Batch在 Spring Integration 顶部实现了远程分块的特性。
远程Step框架
在Spring Batch中对远程Step没有默认的实现,但是提供了远程Step 的框架,通过框架可以方便地扩展出远程Step的实现。
远程Step技术本质上是将对ltem读、写的处理逻辑进行分离;通常情况下读的逻辑放在一个节点进行操作,将写操作分发到另外的节点执行。
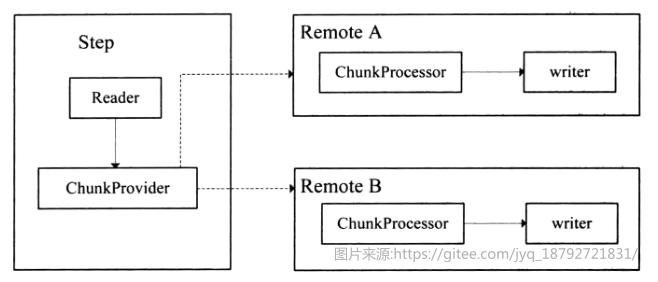
在Master节点,作业步负责读取数据,并将读取的数据通过远程技术发送到指定的远端节点上,进行处理,处理完毕后Master 负责回收Remote端执行的情况。在Spring Batch框架中通过两个核心的接口来完成远程 Step的任务,分别是ChunkProvider 与 ChunkProcessor。
ChunkProvider:根据给定的ItemReader 操作产生批量的Chunk操作。
ChunkProvider接口定义

其中的provide就是将数据进行分组,然后返回将被发送给远程端的处理。
ChunkProcessor接口定义

chunkProcessor处理的方法中,会接收到一个Chunk对象。
在Spring Batch中对远程Step没有默认地实现,但Spring 中提供了另外一个项目,SpringBatch Integration项目,将Spring Batch框架和Spring Integration做了集成,可以通过SpringIntegration提供的远程能力实现远程 Step。
基于SI实现远程Step
SI就是spring batch Integration。
Si的核心思想,就是利用消息队列实现远程Step的一个思想。
分区Step
通过将任务进行分区,不同的Step 处理不同的任务数据达到提高Job效率的功能。分区模式需要对数据的结构有一定的了解,如主键的范围、待处理的文件的名字等。这种模式的优点在于分区中每一个元素的处理器都能够像一个普通Spring Batch任务的单步一样运行,也不必去实现任何特殊的或是新的模式,来让他们能够更容易配置与测试。分区理论上比远程更有扩展性,因为分区并不存在从一个地方读取所有输入数据并进行序列化的瓶颈。
分区作业典型的可以分成两个处理阶段,数据分区、分区处理.
数据分区:根据特殊的规则(例如:根据文件名称,数据的唯一性标识,或者哈希算法)将数据进行合理地切片,为不同的切片生成数据执行上下文Execution Context、作业步执行器Step Execution。可以通过接口Partitioner生成自定义的分区逻辑,Spring Batch批处理框架默认对多文件实现 org.springframework.batch.core.partition.support.MultiResourcePartitioner。
分区处理:通过数据分区后,不同的数据已经被分配到不同的作业步执行器中,接下来需要交给分区处理器进行作业,分区处理器可以在本地执行也可以在远程执行被划分的作业。接口 PartitionHandler定义了分区处理的逻辑, Spring Batch批处理框架默认实现了本地多线程的分区处理org.springframework.batch.core.partition.support.TaskExecutorPartitionHandler。
关键接口
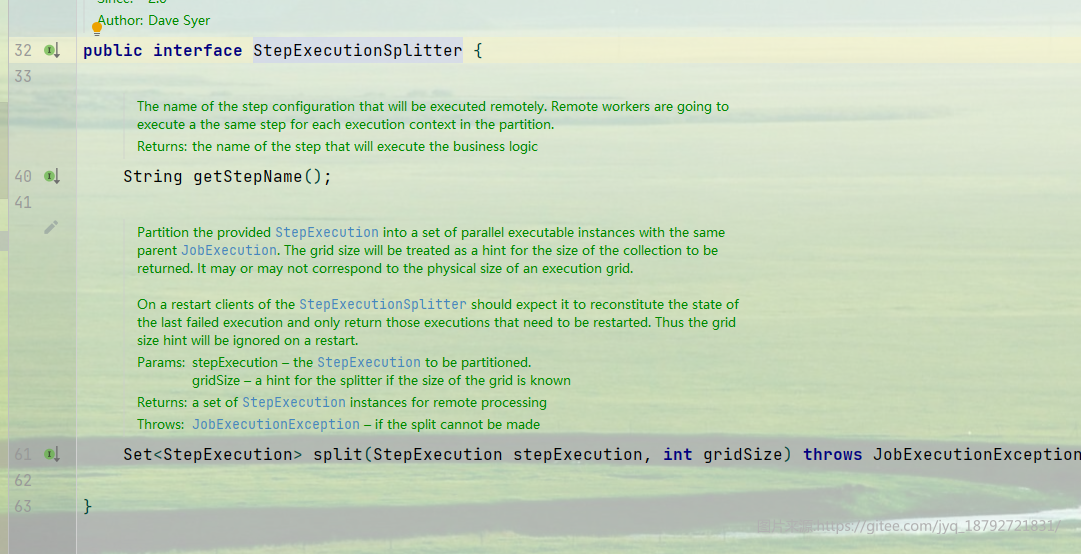
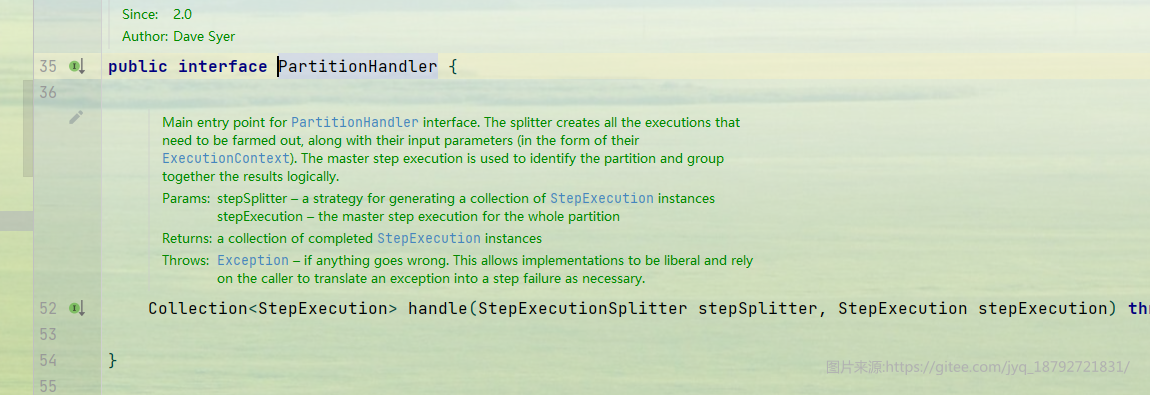
在Spring Batch 中有如下接口支持分区:PartitionHandler、StepExecutionSplitter 、Partitioner。
PartitionHandler 知道执行结构-它需要将请求发送到远程步骤并使用任何可以使用的远程技术收集计算结果,PartitionHandler是一个SPI,Spring Batch通过TaskExecutor为本地执行提供了一个默认实现,在需要进行有大量IO操作的并发处理时,这个功能是很有用的;Partitioner接口定义了根据数据结构将作业进行分区,生成执行上下文 Execution Context;StepExecutionSplitter 根据给定Partitioner产生的执行上下文生成作业步执行器,然后交给PartitionHandler来进行处理。
Partitioner
Partitioner接口定义了如何根据给定的分区规则进行创建作业步执行分区的上下文。每个分区的上下文需要根据对应的分区规则来计算当前分区的处理情况。

StepExecutionSplitter
StepExecutionSplitter 接口定义了如何根据给定的分区规则进行创建作业步执行分区的执行器。
PartitionHandler
PartitionHandler接口定义了分区处理的逻辑;根据给定的StepExecutionSplitter进行分区,并执行,最后将执行的结果进行收集,最终反馈到前端.
基本配置
配置
| 属性 | 说明 | 默认值 |
|---|---|---|
| name | 用于指定分区Step的名字 | |
| partitioner | 用于指定当前使用的分区逻辑,需要实现接口Partitioner | |
| aggregator | 用于指定需要使用的聚合器,该聚合器的作用是将各个分区执行器执行的结果汇总到主执行器中,用于统计最终的计算结果。 | 默认使用实现类DefaultStepExecutionAggregator |
| handler | 用于指定分区执行器 | |
| task-executor | 使用的线程池 | |
| gridSize | 声明分区的HashMap的初始值大小 | 6 |
实例
场景:
计算1~100的和。很简单是吧,5050。
但是还有一个额外的要求,每计算一次,需要睡眠2秒。
也就是说,如果我们用单线程计算,那么总共需要200秒才能执行完成。
那么,我们用多线程执行呢?假设是10个线程,那么需要20秒完成。
如果,我们还有一个需求呢?每个线程只能处理一个十位数。
换句话说,一个线程只能计算10次,而且从一开始就确定的。
比如第一个线程只能处理(0,10]的数字。
第二个线程处理(10,20]的数字。
。。。。。
这就是数据分区。
首先我们创建一个分区策略,将100个数字分成10份。

接着在tasklet中使用分区时传入的参数

接着设置分区处理操作

最终将每个线程的计算结果统计起来

执行结果
分区计算
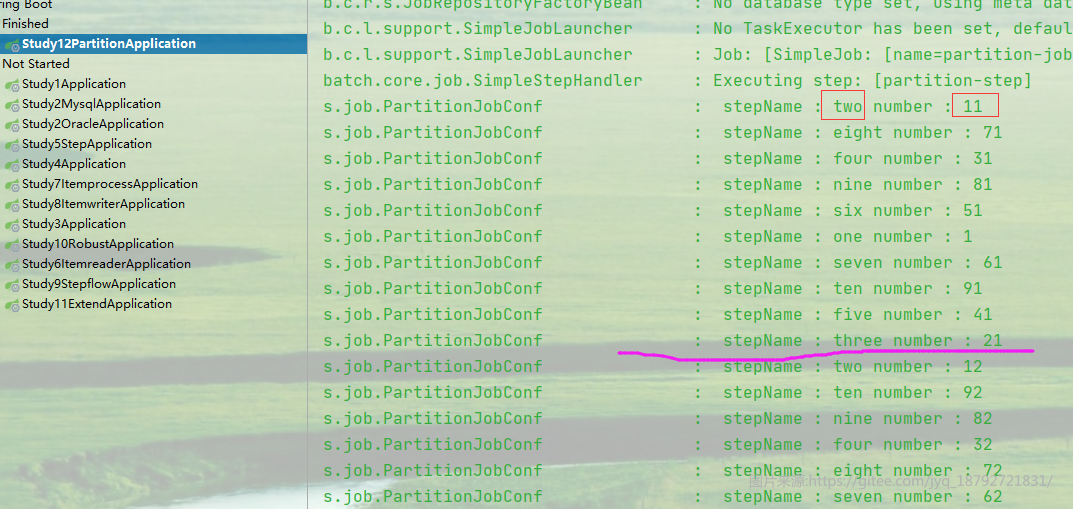
计算结束
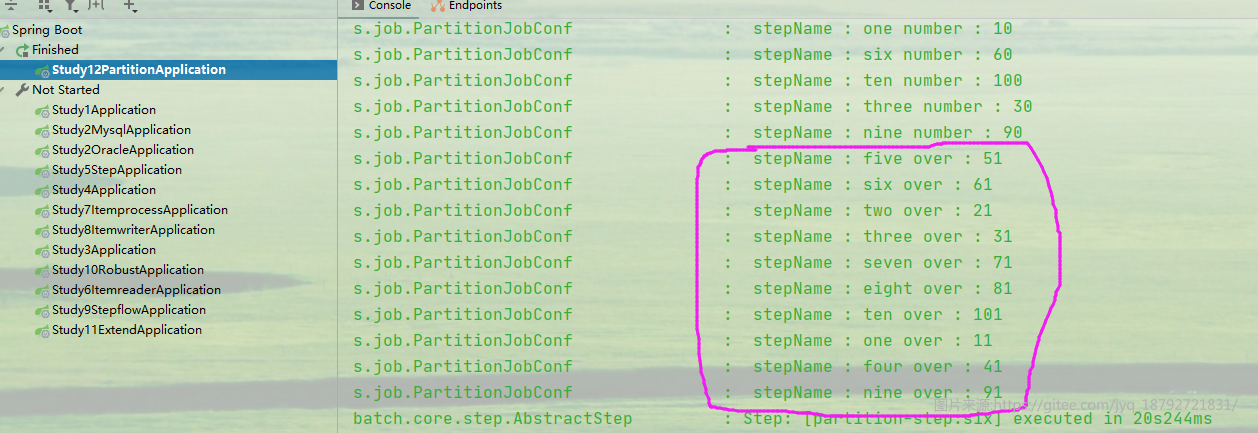
计算结果
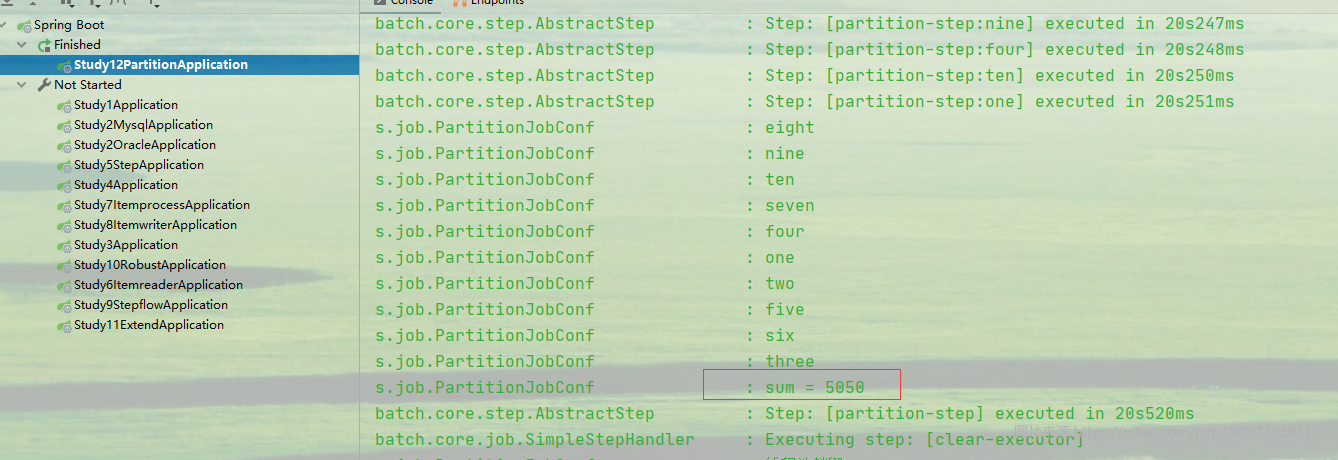
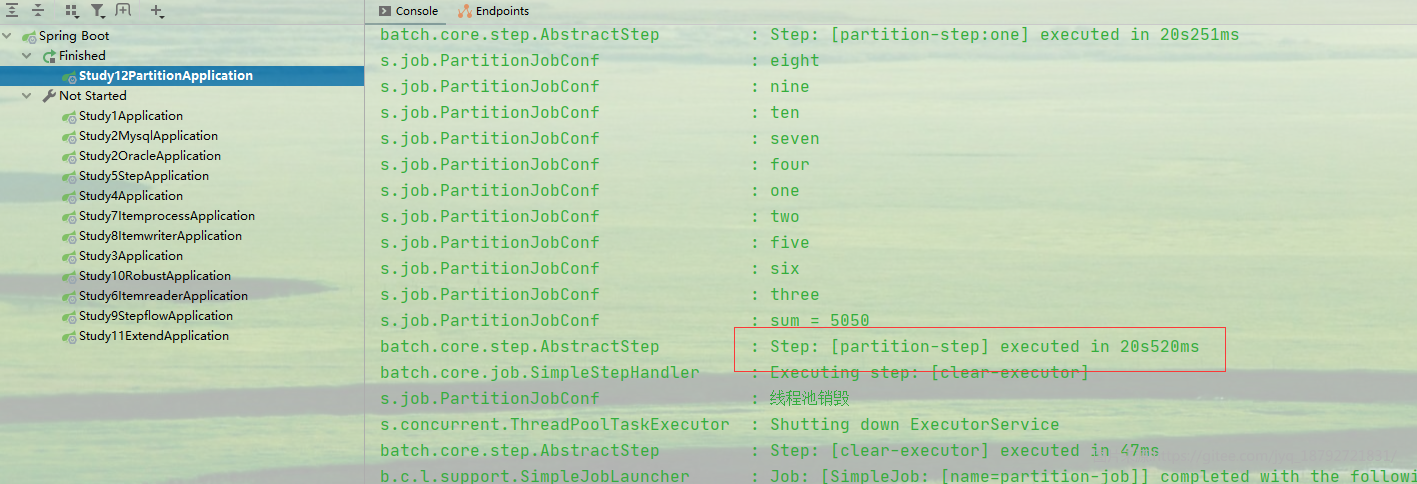
时间统计
完整代码
@Slf4j
@Component
public class PartitionJobConf {
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private JobLauncher jobLauncher;
@Autowired
private JobRepository jobRepository;
private ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
@PostConstruct
public void runJob() throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job(), new JobParametersBuilder().addDate("date", new Date()).toJobParameters());
}
private Job job() {
return jobBuilderFactory.get("partition-job")
// 分区操作执行
.start(step())
// 线程池销毁操作
.next(stepBuilderFactory.get("clear-executor")
.tasklet((sc, cc) -> {
log.info("线程池销毁");
executor.shutdown();
return RepeatStatus.FINISHED;
}).build())
.build();
}
private Step step() {
// 设置线程池最大的线程数量
executor.setMaxPoolSize(10);
// 设置核心线程数量
executor.setCorePoolSize(10);
// 线程池初始化
executor.initialize();
// 数据分区
Partitioner partitioner = gridSize -> {
HashMap<String, ExecutionContext> result = new HashMap<>();
result.put("one", new ExecutionContext(Map.of("key", "one", "begin", 1, "end", 10, "sum", 0)));
result.put("two", new ExecutionContext(Map.of("key", "two", "begin", 11, "end", 20, "sum", 0)));
result.put("three", new ExecutionContext(Map.of("key", "three", "begin", 21, "end", 30, "sum", 0)));
result.put("four", new ExecutionContext(Map.of("key", "four", "begin", 31, "end", 40, "sum", 0)));
result.put("five", new ExecutionContext(Map.of("key", "five", "begin", 41, "end", 50, "sum", 0)));
result.put("six", new ExecutionContext(Map.of("key", "six", "begin", 51, "end", 60, "sum", 0)));
result.put("seven", new ExecutionContext(Map.of("key", "seven", "begin", 61, "end", 70, "sum", 0)));
result.put("eight", new ExecutionContext(Map.of("key", "eight", "begin", 71, "end", 80, "sum", 0)));
result.put("nine", new ExecutionContext(Map.of("key", "nine", "begin", 81, "end", 90, "sum", 0)));
result.put("ten", new ExecutionContext(Map.of("key", "ten", "begin", 91, "end", 100, "sum", 0)));
return result;
};
String stepName = "partition-step";
// 分区内线程处理的操作
TaskletStep step = stepBuilderFactory.get("real-step")
.tasklet((sc, cc) -> {
// 获取参数传递上下文
ExecutionContext executionContext = sc.getStepExecution().getExecutionContext();
// 获取本次tasklet将要处理的数字
int begin = executionContext.getInt("begin");
// 将下次tasklet要处理的数字放入
executionContext.putInt("begin", begin + 1);
// 如果本次tasklet将要处理的数字达到了截止值
if (begin > sc.getStepExecution().getExecutionContext().getInt("end")) {
// 输出本次tasklet处理的数字
log.info(" stepName : " + sc.getStepExecution().getExecutionContext().get("key") + " over : " + begin);
// 结束本线程的tasklet
return RepeatStatus.FINISHED;
}
// 将本次tasklet的值,。汇总到本线程的tasklet的和里面
executionContext.putInt("sum", executionContext.getInt("sum") + begin);
// 计算完一个数字,需要睡眠2秒
TimeUnit.SECONDS.sleep(2);
// 输出本次tasklet处理的数字
log.info(" stepName : " + sc.getStepExecution().getExecutionContext().get("key") + " number : " + begin);
// 还未计算完成,继续下一次tasklet
return RepeatStatus.CONTINUABLE;
})
.build();
// 创建线程处理调度
TaskExecutorPartitionHandler handler = new TaskExecutorPartitionHandler();
// 总共10个线程
handler.setGridSize(10);
// 线程池中需要处理的操作
handler.setStep(step);
// 设置线程池
handler.setTaskExecutor(executor);
return stepBuilderFactory.get(stepName)
// 设置本step是一个分区step
.partitioner(stepName, partitioner)
// 传入简单的拆分器(随机拆分)
.splitter(new SimpleStepExecutionSplitter(jobRepository, true, stepName, partitioner))
// 设置分区数量(这里应该是重复了)
.gridSize(10)
// 设置线程处理调度
.partitionHandler(handler)
// 设置线程池(这里应该是重复了)
.taskExecutor(executor)
// 分区线程计算结果汇总
.aggregator(((result, executions) -> {
executions.forEach(x -> {
log.info(x.getExecutionContext().get("key").toString());
});
result.getExecutionContext().put("over", "over");
// 汇总结果
result.getExecutionContext().put("sum", executions.stream().map(x -> x.getExecutionContext().getInt("sum")).reduce((x1, x2) -> x1 + x2).get());
log.info("sum = " + result.getExecutionContext().getInt("sum"));
}))
.build();
}
}
关于远程Step和远程+分区Step,写的都是理论的东西。
先在这里挖个坑:
1.远程Step+SI;
2.远程Step+分区Step+多线程。