spring batch 健壮性
github地址:
https://github.com/a18792721831/studybatch.git
文章列表:
批处理要求Job必须有较强的健壮性,通常Job是批量处理数据、无人值守的,这要求在Job执行期间能够应对各种发生的异常、错误,并对Job执行进行有效的跟踪。一个健壮的Job通常需要具备如下的几个特性。
-
容错性
在Job执行期间非致命的异常,Job执行框架应能够进行有效的容错处理,而不是让整个Job执行失败;通常只有致命的、导致业务不正确的异常才可以终止Job的执行。
-
可追踪性
Job 执行期间任何发生错误的地方都需要进行有效的记录,方便后期对错误点进行有效的处理。例如在Job执行期间任何被忽略处理的记录行需要被有效地记录下来,应用程序维护人员可以针对被忽略的记录后续做有效的处理。
-
可重启性
Job执行期间如果因为异常导致失败,应该能够在失败的点重新启动Job;而不是从头开始重新执行Job。
| 特性 | 功能 | 适用时机 | 适用场景 |
|---|---|---|---|
| Skip | 跳过错误的记录行,保证Job能够正确的执行 | 适用于非致命的异常 | 面向Chunk的Step |
| Retry | 重试给定的操作,比如短暂的网络异常,并发异常等等 | 适用于短暂的异常,经过重试之后该异常可能会不在重现 | 面向Chunk的step或者应用代码 |
| Restart | Job执行失败后,重新启动Job实例 | 因异常、错误导致Job失败后 | Job执行重新启动 |
跳过skip
Step执行期间read、process、write 发生的任何异常都会导致Step 执行失败,进而导致作业的失败。批处理作业的自动化、定时触发,有特定的执行时间窗口特性,决定了尽可能地减少Job的失败。设想信用卡对账单的处理的业务场景,银行每天需要处理海量的对账文件,如果对账文件中有少量的一行或者几行错误格式的记录,在真正进行作业处理的时候,不希望因为几行错误的记录而导致整个作业的失败;而是希望将这几行没有处理的记录跳过去,让整个Job正确执行,对于错误的记录则通过日志的方式记录下来后续进行单独的处理。
Spring Batch框架通过属性 skip-limit、skippable-exception-classes. skip-policy来完成异常跳过的能力。
| 属性/元素 | 功能说明 |
|---|---|
| skippable-exception-classes | 定语允许跳过的异常,配到该类型异常的时候,不会导致Job失败,而是跳过当前记录的处理,保证Job继续正确的执行。 |
| include | skippable-exception-classed的子元素,用于表示包括在内的异常 |
| exclude | skippable-exception-class的子元素,用以表示排除在内的异常,通常用来定义某一类型的子异常 |
| skip-limit | 跳过限制次数,当超过该次数后在发生异常会导致Job失败 |
| skip-policy | Job的跳过策略,根据该策略判断是否允许跳过异常 |
reader
比如
运行结果

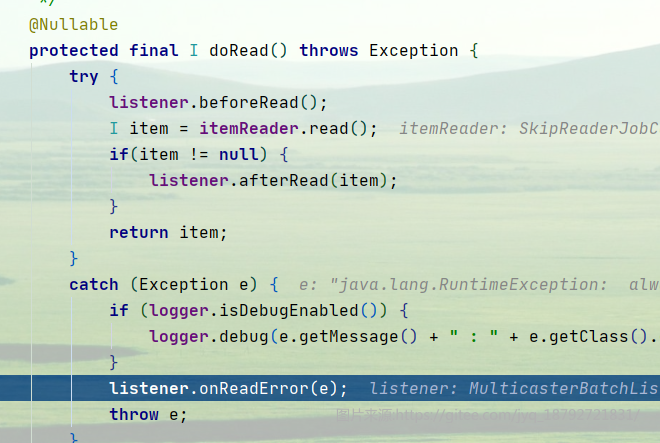
这里有一个问题,就是我们定义的onSkipInRead没有执行。
我们调试一下,看看原因

只会调用onReadError,而不是OnSkipInRead
稍等,这个方法还有映像。

{kind=link}
调用的是ItemReader的异常拦截器。
而且,我从github的issus上也找到了蛛丝马迹
onSkipInProcess is not called if the exception is marked as no-rollback [BATCH-1383] #2198
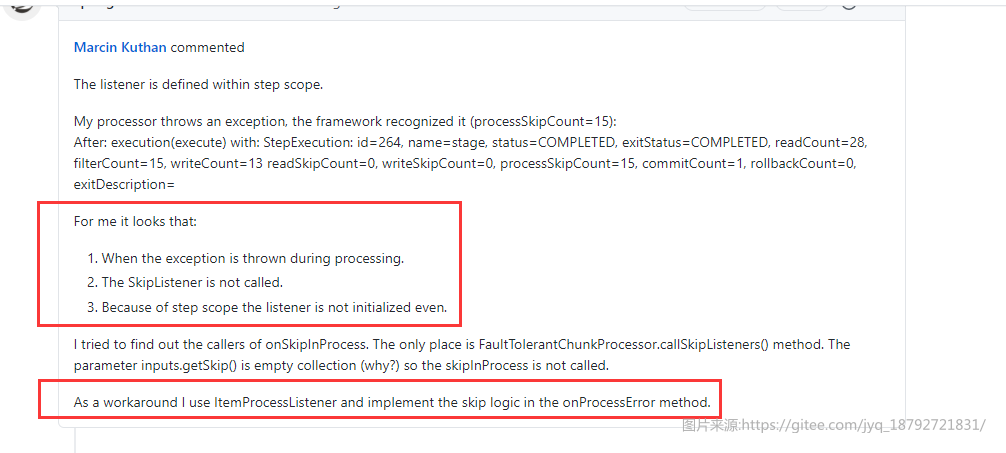
基于这个原因,我创建了一个ItemReader的onErrorRead的拦截器
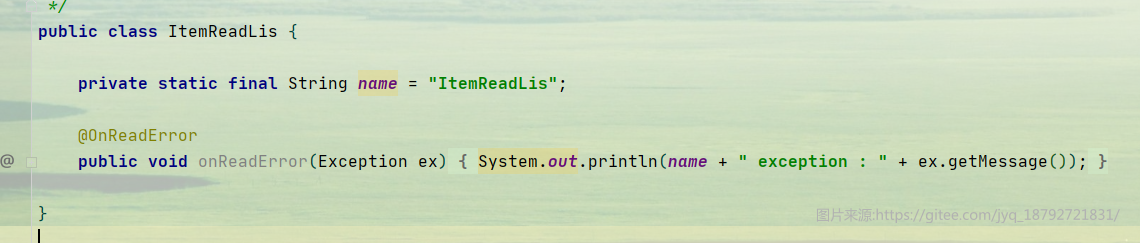
然后设置使用这个拦截器
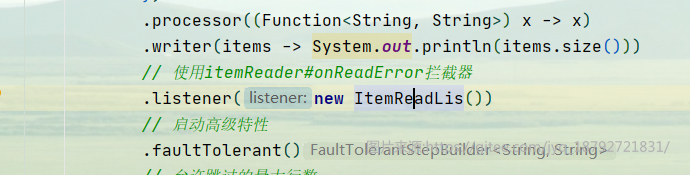
执行结果
如果同时配置Policy和limit,会将policy和limit进行合并(以最大的为主(如果异常相同,如果异常不同那么设置多少就是多少)):
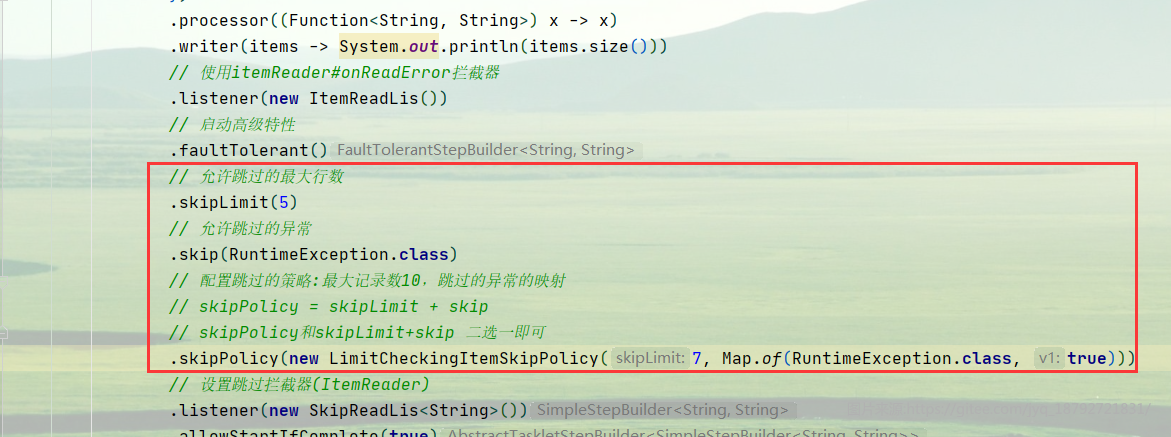
执行结果

完整代码
@Component
public class SkipReaderJobConf {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private JobLauncher jobLauncher;
@PostConstruct
public void runJob() throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job(), new JobParametersBuilder().addLong("id", 3L).toJobParameters());
}
private Job job() {
return jobBuilderFactory.get("skip-reader-job")
.start(step()).build();
}
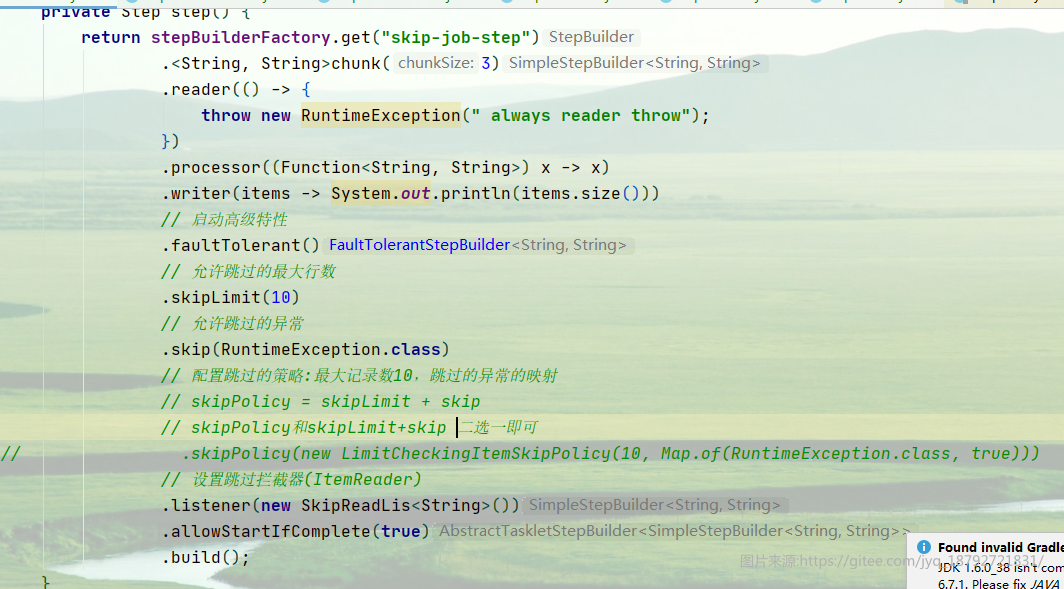
private Step step() {
return stepBuilderFactory.get("skip-job-step")
.<String, String>chunk(3)
.reader(() -> {
System.out.println(" reader ");
throw new RuntimeException(" always reader throw");
})
.processor((Function<String, String>) x -> x)
.writer(items -> System.out.println(items.size()))
// 使用itemReader#onReadError拦截器
.listener(new ItemReadLis())
// 启动高级特性
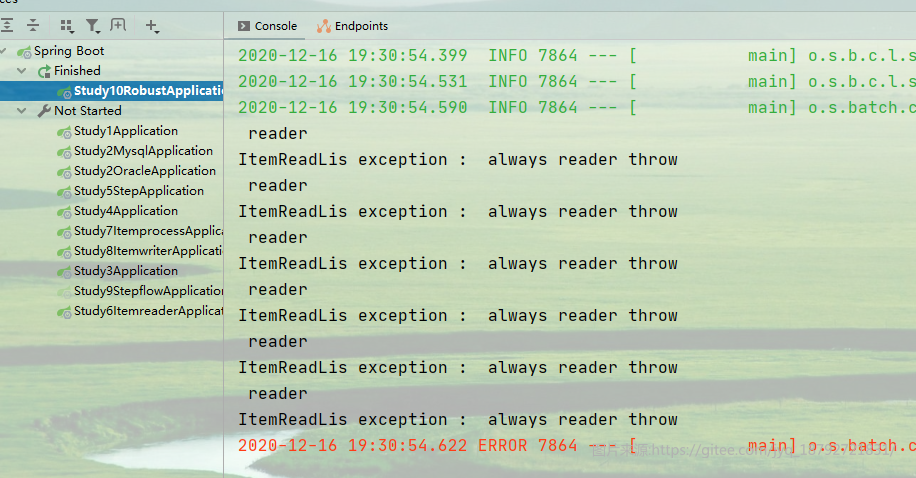
.faultTolerant()
// 允许跳过的最大行数
.skipLimit(5)
// 允许跳过的异常
.skip(MyException.class)
// 配置跳过的策略:最大记录数10,跳过的异常的映射
// skipPolicy = skipLimit + skip
// skipPolicy和skipLimit+skip 二选一即可
.skipPolicy(new LimitCheckingItemSkipPolicy(7, Map.of(RuntimeException.class, true)))
// 设置跳过拦截器(ItemReader)
.listener(new SkipReadLis<String>())
.allowStartIfComplete(true)
.build();
}
}
processor
ItemProcessor也是一样的,只会调用OnProcessError,而不会调用OnSkipInProcess

这里有一个比较坑的点:在ItemProcess中,如果使用lambda写逻辑,可能会造成死循环。

即使我在prcoess中抛出异常

而将lambda换为匿名内部类,就可以
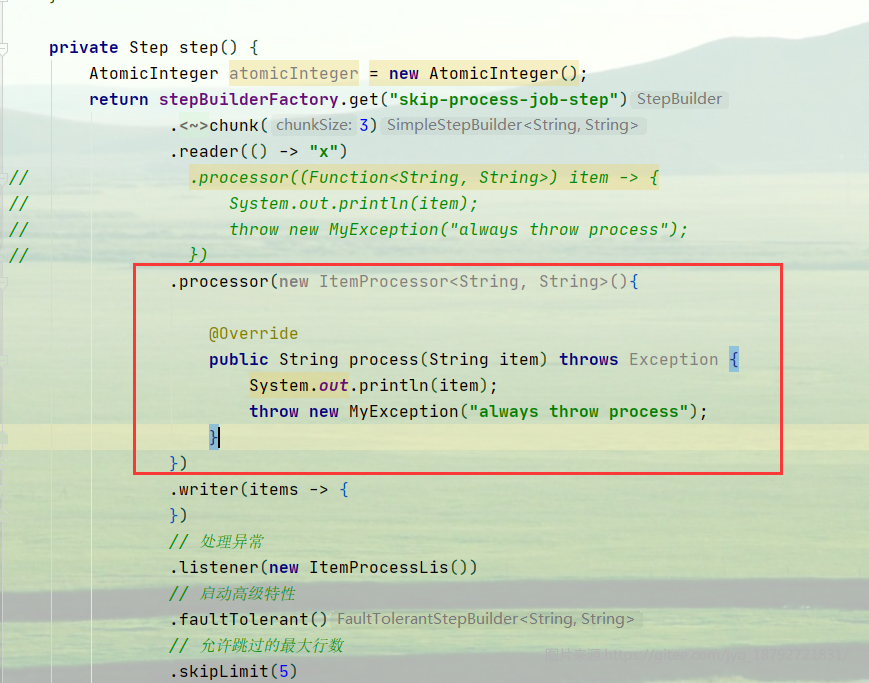
执行结果

哎,发现这里的skipInProcess又执行了。
嗯~,调试一下吧
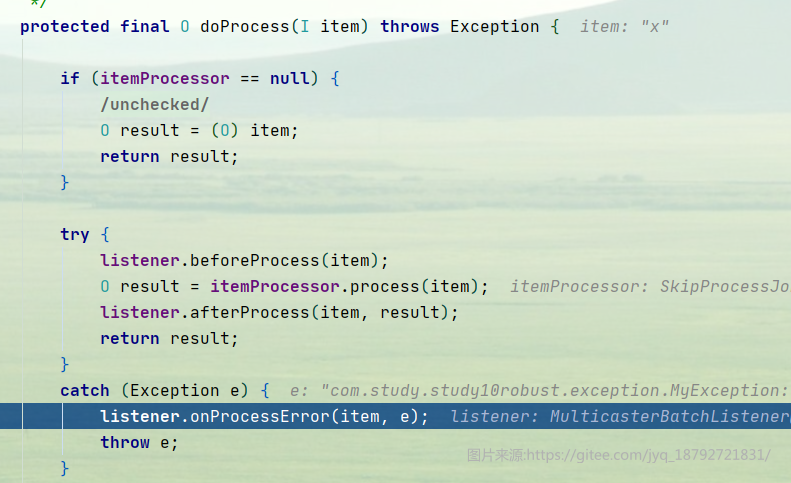
这里是ItemProcess的异常拦截器,这个异常拦截器每次都会执行。
那么,skipInProcess什么时候执行呢?

在write里面会调用skipInProcess

也就是说,如果我们在write中进行操作,那么skipInProcess和onProcessError谁会执行呢
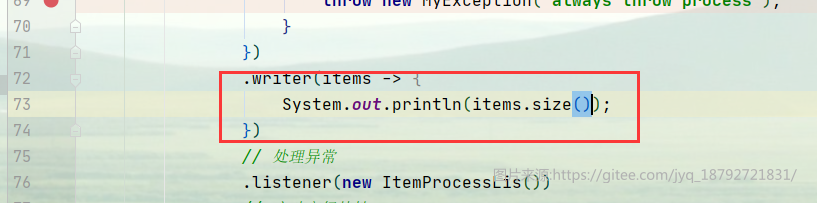
经过验证,发现write里面的数据先执行,然后才是skipInProcess

从这里和github上找到的资料,我们基本上可以得到结论:
拦截器的优先级:
ItemError > skip
process > write
writer
我们基于process中的代码,加上writer的拦截器,然后看看当process中发生了异常, 其执行结果是怎样的?
比如

我们发现首先是读、处理、写(异常(批量))、处理、写(异常(单个))
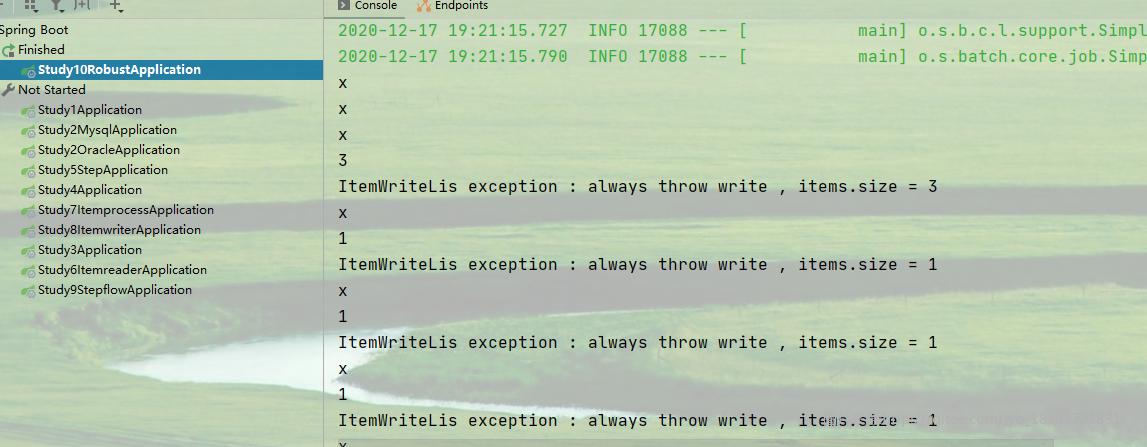
当出现写异常的时候,spring batch将会将每一个都write一次,目的是为了找出出现异常的那一个。
当找到异常的那一个,那一个将会被跳过。其他的,并不会计入被跳过的数量中。
那,如果process异常呢
如果process异常,那么就不会走到write,也就不存在先后关系

综上所述,我们基本上可以得出如下结论。
- 当reader出现异常,并且异常允许跳过,那么skipInRead不会执行,而是执行onReadError的方法。
- 当process出现异常,那么每一个数据(单个)都会执行onProcessError方法,当达到chunk数量时,会将reader的数据传输给write,并执行write方法,然后执行skipInProcess(批量)
- 当write出现异常,那么首先会执行一次onWriteError(批量),接着会将单个数据(单个)在重复执行process和write,找出异常的数据,并计算入skipCount中。并不会执行skipInWrite
这个顺序一定要注意。
SkipPolicy
接口定义

可以自定义实现跳过判断的接口,来决定是否跳过。
SkipPolicy实现
跳过策略

见名知义。
| SkipPolicy默认实现 | 功能说明 |
|---|---|
| AlwaysSkipItemSkipPolicy | 发生任何异常都会导致跳过记录处理 |
| CompositeSkipPolicy | 组合跳过策略,可以将多个跳过策略组合在一起使用,按照顺序判断是否应该跳过该记录;多个组合策略中只要有一个允许跳过,则组合策略允许跳过该记录的处理。 |
| ExceptionClassifierSkipPolicy | 为不同的异常定义不同的跳过策略 |
| LimitCheckingItemSkipPolicy | 根据设置的次数决定异常是否能被跳过处理 |
| NeverSkipItemSkipPolicy | 发生任何异常都不会被跳过 |
重试Retry
Step执行期间read、process、write发生的任何异常都会导致Step执行失败,进而导致作业的失败。批处理作业的自动化、定时触发,有特定的执行时间窗口特性,决定了尽可能地减少Job的失败。处理任务阶段发生的异常可以让业务失败,也可以通过Skip 的设置,跳过部分异常;但是另外还有部分异常,例如并发对数据库的操作导致的数据库锁的异常(DeadlockLoserDataAccessException)、网络不稳定导致的网络连接异常(java.net.ConnectException)。这类异常的出现可能在下次重新操作的时候消失,数据库锁的异常在下次操作可能正确恢复,网络不能连接的异常可能在重试几次后恢复正常。因此,这些异常出现的时候,不期望作业发生异常,而是希望通过几次重试操作,尽可能让Job成功执行。
Retry属性
| 属性 | 功能说明 |
|---|---|
| retryable-exception-classes | 定义允许重试的异常,碰到该类型异常的时候,不会导致Job失败;而是重试当前的操作,保证Job继续正确地执行 |
| include | 表示包含在内的异常 |
| exclude | 表示排除的异常 |
| retry-limit | 任务最大重试次数,当超过该次数会进行跳过,或者Job失败 |
| retry-policy | Job的重试策略,根据该策略判断是否允许重试该次失败的操作 |
| cache-capacity | 存放RetryContext的缓存大小,当超过该值时,会发生异常 |
| retry-listeners | 定义重试拦截器 |
reader
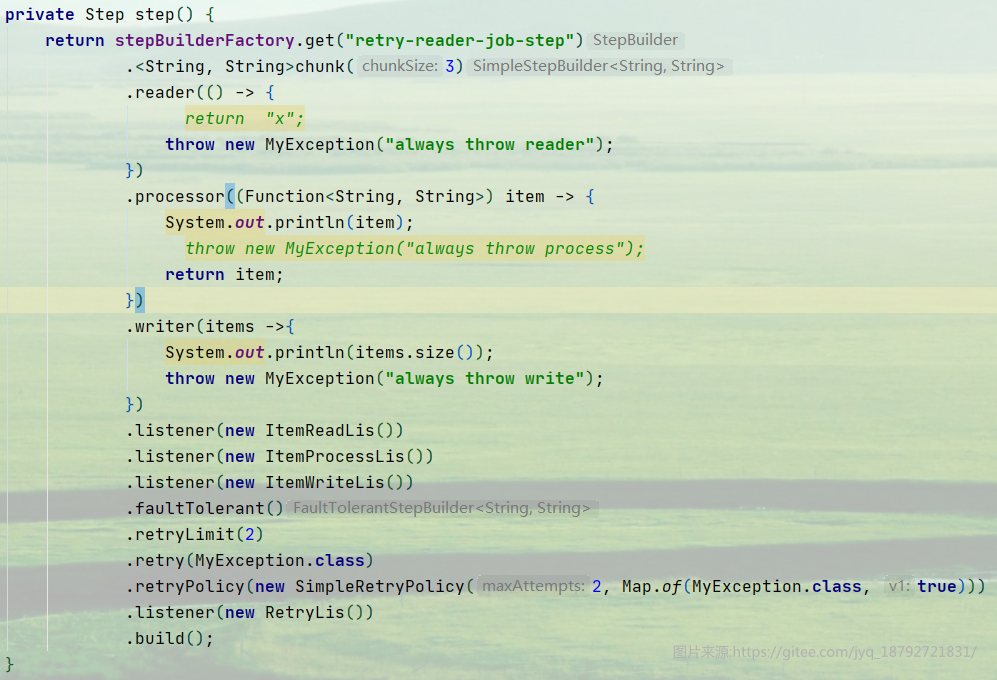
执行结果

提示没有配置跳过异常,我们配上,然后将拦截器配置上

执行结果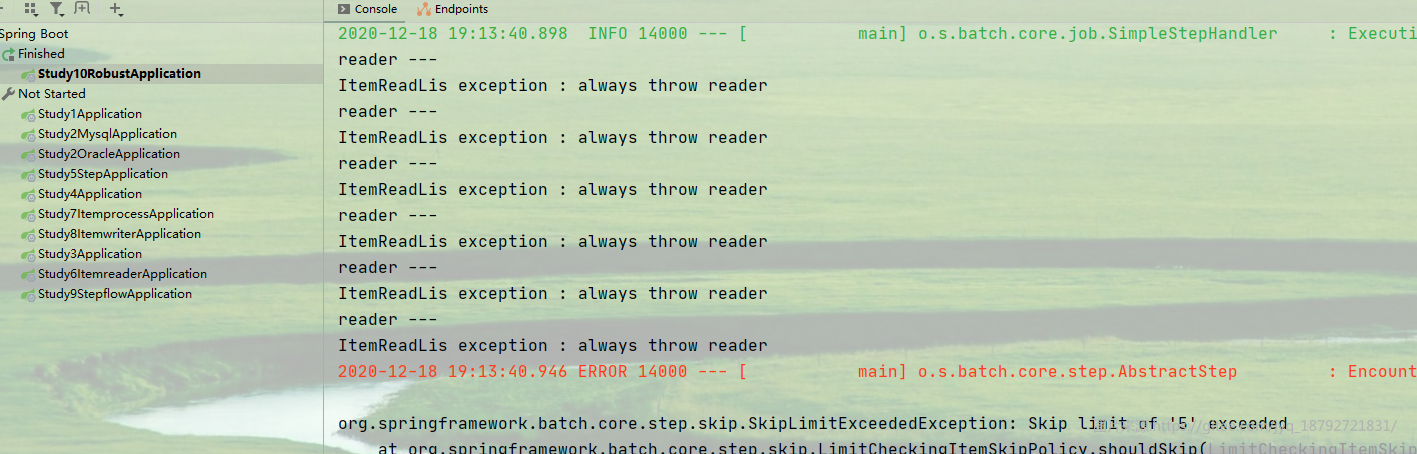
发现reader并不会进行重试,也就是说,reader出现异常了,不会进行重试。
processor
我们在reader中返回数字,在process中抛出异常。(这里需要注意,使用lambda表达式,会在某种场景下造成死循环)
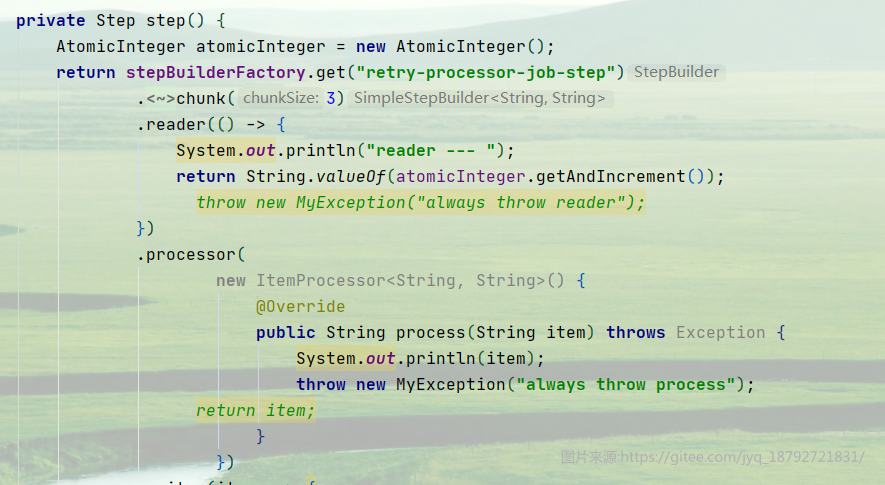
然后配置重试2次,跳过5次,然后添加对应的拦截器

执行结果

从这里我们看出,spring batch的执行过程大概是:
因为chunk配置的数量是3,所以首先会调用3次reader,然后将reader的结果放到一个list中。接着将list中的元素一个一个传输给process中。
在传输给process中之前,首先会调用RetryListener中的open方法,只有全部的open返回true,才会真正进入到prcoess中的方法。
在process中抛出异常时,会首先调用OnProcessError方法;接着是RetryListener中的error方法。
当执行完RetryListener的error方法后,下一个是RetryListener的close方法。
当第一个元素被执行完后,会再次调用RetryListener的open和close方法。

当这一组数据全部都这样处理之后,就会执行skipListener的skipOnProcess方法。
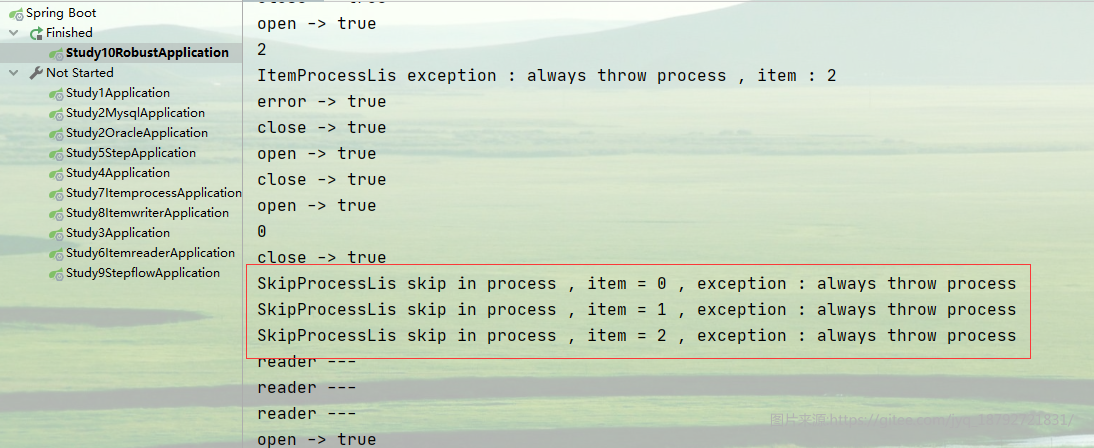
在超出skipLimit的限制之前,首先会将这一组数据全部执行一次
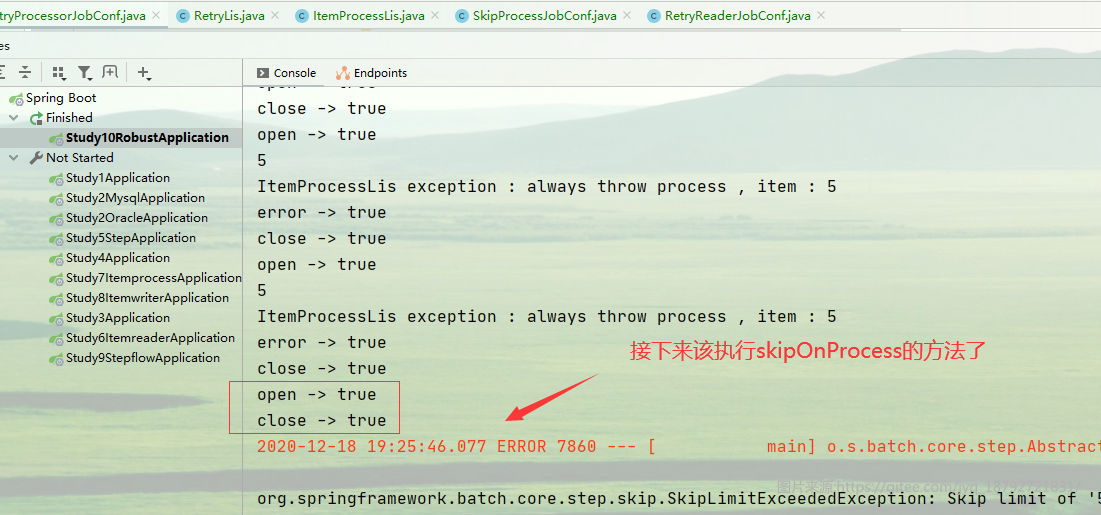
Writer
逻辑差不多,只不过将异常抛出的位置移动到了writer里面了

重试、跳过策略以及对应的拦截器不可少。

执行结果
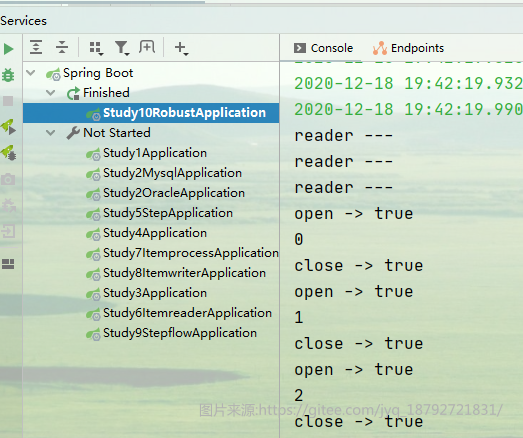
首先是3次reader调用,当达到chunk的次数后,将reader的结果放到一个list中,然后将list中的元素一个一个传输给processor。
在传输给process前后需要执行RetryListener的open和close方法。
接着就是将整个list传输给writer。
在传输给writer的前后也会调用RetryListener的open和close方法。
从这里,也侧面的说明了只有process和writer抛出异常能够触发重试。
图中红框框起来的就是writer的执行过程

当在writer中出现异常时,首先会调用ItemWriter的拦截器的onWriteError方法。
接着是RetryListener的error和close方法。
因为writer出现了异常,而且出现的异常属于可重试的异常,所以进行异常,重新将list中的元素一个一个的传输给process。
传输前后需要执行RetryListener的open和close方法。
如果在writer中再次出现异常,而且,达到retry-limit的限制之后,就需要执行跳过了。
在上面的跳过中,我们知道,当writer出现异常的时候,需要一个一个的传输给writer,然后找到异常的记录。

当全部的数据都这样一个一个重新执行process和write方法后,就可以得到这一次list中全部的异常的数据了。
得到异常数据后,会额外调用一次RetryListener的open和close方法
接着对异常的数据,每一个调用SkipOnWriter方法
重试策略RetryPolicy
spring batch默认实现的重试策略
| RetryPolicy实现 | 功能说明 |
|---|---|
| AlwaysRetryPolicy | 发生任何异常都会导致重试操作 |
| NeverRetryPolicy | 发生任何异常都不会导致重试操作 |
| CompositeRetryPolicy | 组合重试策略,可以将多个重试策略组合在一起使用,按照顺序判断是否应该重试操作;多个组合操作中只要有一个不允许重试,则组合策略不允许重试操作 |
| ExceptionClassifierRetryPolicy | 为不同的异常定义不同的重试策略 |
| SimpleRetryPolicy | 根据设置的次数决定是否能进行重试 |
| TimeoutRetryPolicy | 在给定的时间内可以进行重试,超过给定的时间将不会进行重试操作 |
重试模板
Spring Batch框架为面向批的操作提供了自动重试的能力,如果作业步的实现是自定义的Tasklet,Spring Batch框架提供了一组方便易用的重试模板RetryTemplate,使用重试模板可以方便地完成重试功能。目前框架中面向Chunk的重试功能同样是使用RetryTemplate来完成的。
RetryOperations接口定义了重试操作的基本方法,重试模板实现该接口;RetryTemplte提供标准的重试操作;RetryCallback 接口定义了具体的需要重试的逻辑,当具体的重试逻辑发生错误时候,会导致该回调实现的操作按照给定的重试策略进行重试:RetryPolicy 接口定义重试策略,可以使用简单的重试策略或者超时策略;BackOffPolicy 接口定义了补偿策略,每次重试发生的时候可以都会调用该业务补偿;RecoveryCallback接口定义有状态的业务补偿策略,在所有的重试完成之后会调用该接口完成业务恢复功能;RetryState接口表示重试状态,用来完成有状态的重试。
重试模板的类图
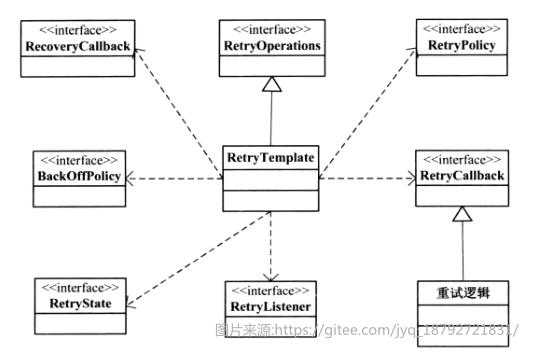
关键的接口和类
| 关键类 | 说明 |
|---|---|
| RetryOperations | 重试操作的接口类,定义了 如何调用重试的操作,包括无状态的重试、有状态的重试操作 |
| RetryTemplate | 重试模板类,实现RetryOperations接口组装其他接口完成重试功能 |
| RetryCallback | 重试回调接口,当发生重试的时候会多次调用该回调操作,用户可以实现该接口,完成需要重试的业务逻辑 |
| RetryPolicy | 重试策略,可以使用spring batch框架提供的简单次数重试策略、超时策略、或者自定义的重试策略 |
| BackOffPolicy | 业务补偿操作,每次重试都会触发该接口的backOff操作 |
| RetryListener | 重试拦截器,重试发生期间会触发拦截器的执行,可以定义多个拦截器 |
| RecoveryCallback | 重试执行完毕后,会触发恢复回调操作,通常用在有状态的重试中 |
| RetryState | 重试状态,用在有状态重试中,可以根据提供的key获取重试上下文 |
接口定义,里面分别是有状态重试和无状态重试。

真正重试执行的业务操作

业务补偿操作:start操作在重试过程中仅执行一次,backOff操作在每次重试发生后都会触发补偿操作。

在整个重试操作完成后会触发RecoveryCallback操作

重试状态的定义
重试Tasklet
我们创建一个tasklet,然后在里面定义retryCallback,retryPolicy和retryListener。最后用retryTemplate执行无状态的重试。

执行结果
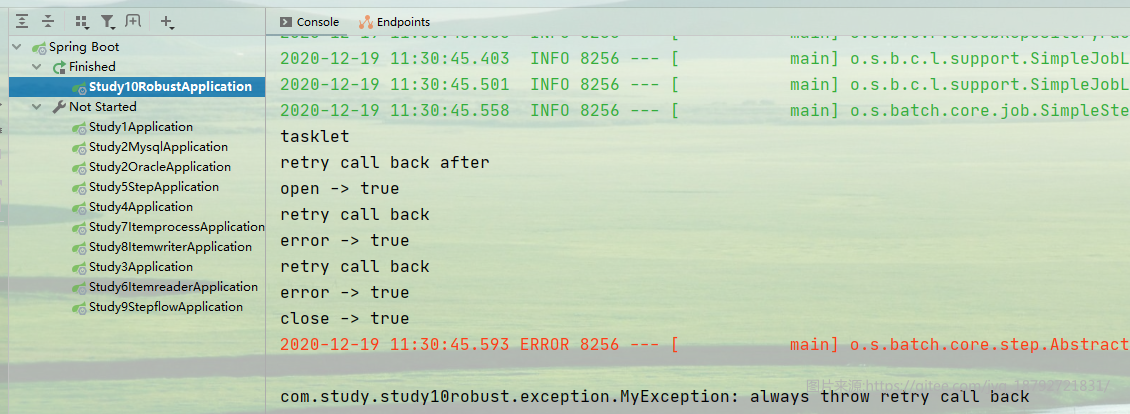
还有一个是有状态的重试,这个状态主要是传输一些值可以用到。

补偿Tasklet
在重试Tasklet的基础上,额外创建一个补偿策略

接着将补偿策略设置给重试模板
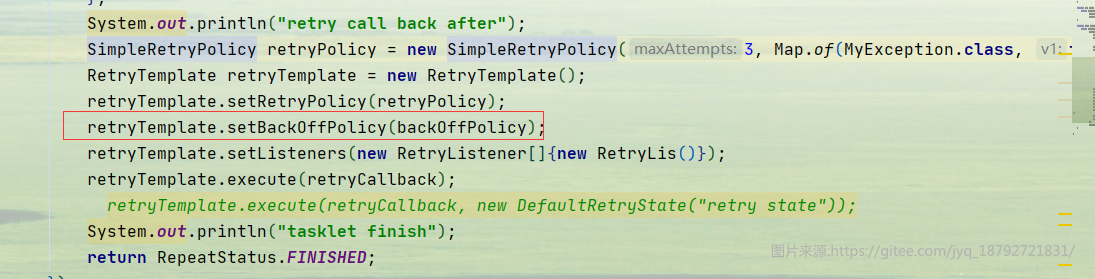
然后执行

第一次并不会直接调用补偿backOff,而是调用start。
在第一次调用过程中发生了异常,此时会调用补偿backOff,然后重新执行retryCallback方法。
知道达到最大次数后,close重试。
向jvm抛出异常。
重启Restart
即便再健壮的Job,解决了Skip、Retry 的问题,也有可能最终执行Job失败。在Job失败的场景下是让用户重头再次执行Job还是能够从上次Job 失败的地点重新执行Job? SpringBatch框架提供了重启Job的功能,包括重启Job、Step支持重启、重启已经完整的Step、禁止 Step重启、限制重启次数等功能。
即便再健壮的Job,解决了Skip、Retry 的问题,也有可能最终执行Job失败。在Job失败的场景下是让用户重头再次执行Job还是能够从上次Job 失败的地点重新执行Job? SpringBatch框架提供了重启Job的功能,包括重启Job、Step支持重启、重启已经完整的Step、禁止 Step重启、限制重启次数等功能。
第一次Job执行过程中校验Step出错,接下来重启Job会重上次失败的点进行重新启动Job。Job的两次执行过程中,对应同一个Job的实例,但是执行器是不同的两个执行器。
重启Job
spring batch框架对重启Job有如下限制
- 只能重启状态为失败的Job实例
- 任何Job失败的实例都可以被重新执行
- 重新执行Job的时候,会从上次执行失败的点重新开始执行,而不是从头开始执行
- 已经完成的Step,通过特殊的标识,也可以被重新执行
- 一个失败的Job可以被不断的执行,没有重启次数的限制。
正常情况下,如果我们的job执行失败,那么是可以无限次进行重启的
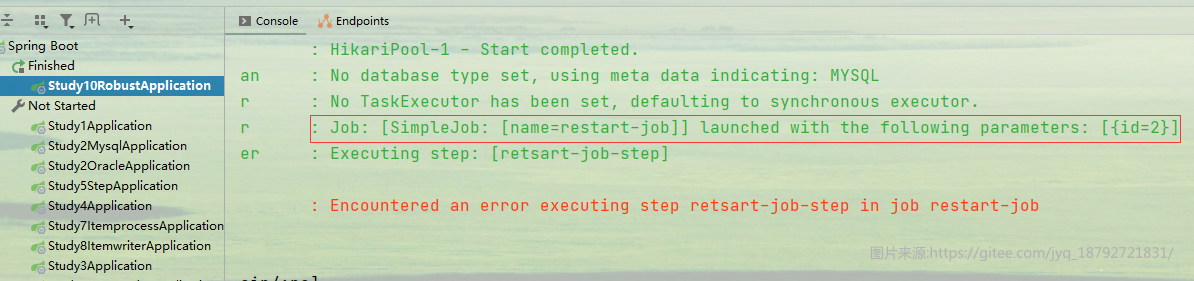
第二次重启
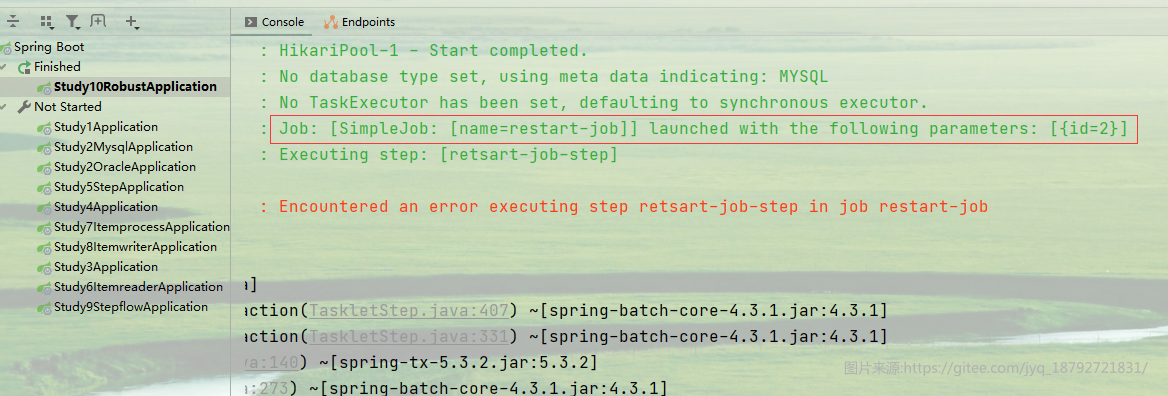
如果需要设置不能重启,那么可以在创建Job的时候,设置不允许重启,即使Job失败,也是不允许重启的

如果非要进行重启,那么是什么都不会执行,而是直接抛出异常

重启已完成的任务
重启次数限制是step的一个配置,一般来说,我们的Job失败,一定是在某一个step中失败了。但是这个step前面的操作可能已经成功了。
所以,下一次重启的时候,就会从失败的step接着执行,默认是不会重新执行已经完成的step的。
当然,如果说前后的step联系比较紧密,如果出现异常,那么某些必须的step就需要每次都执行,所以,需要在step中设置,允许重启已完成的step.
比如我们有两个step,然后给step1设置允许重启已完成。当然,step1不会抛出异常的。

在step2中抛出异常

抛出异常会导致Job失败。

因为step1是允许重启已完成的step的,所以我们重启,step1还是会执行
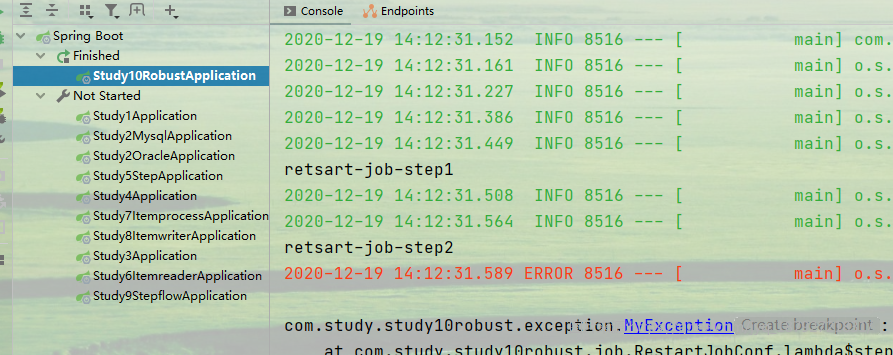
如果我们将step1的允许重启已完成的配置去掉,默认情况下,已完成的step不会重复执行

就像这样

重启次数限制
一般情况下,step已完成,但是Job失败时,step要么不需要重启执行,要么允许无限重启执行。
但是,还有一些允许重启执行的step来说,在执行次数上也有限制。
比如我们允许step1重启已完成。

在默认情况下是可以先限制的重启执行step1.但是如果有重启次数限制,那么就可以限制。比如限制3次
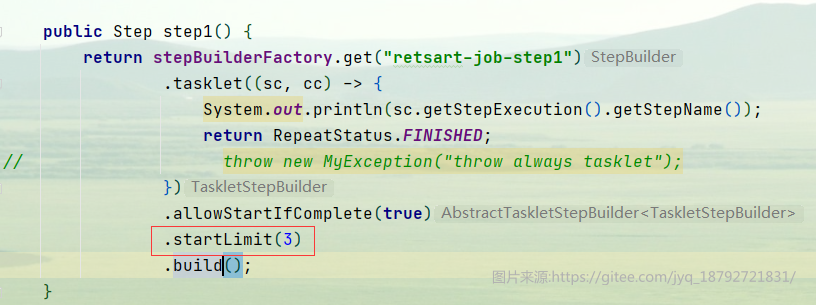
接着我们多次重启
第一次

第4次的时候
就会抛出异常
