准备工作
- 去maven仓库下载jsoup的jar包或者在maven工程添加依赖
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
- 去找王者荣耀网址爬取英雄图片
https://pvp.qq.com/web201605/herolist.shtml
-
打开开发者工具(右键检查),找到Elements定位到图片的区域
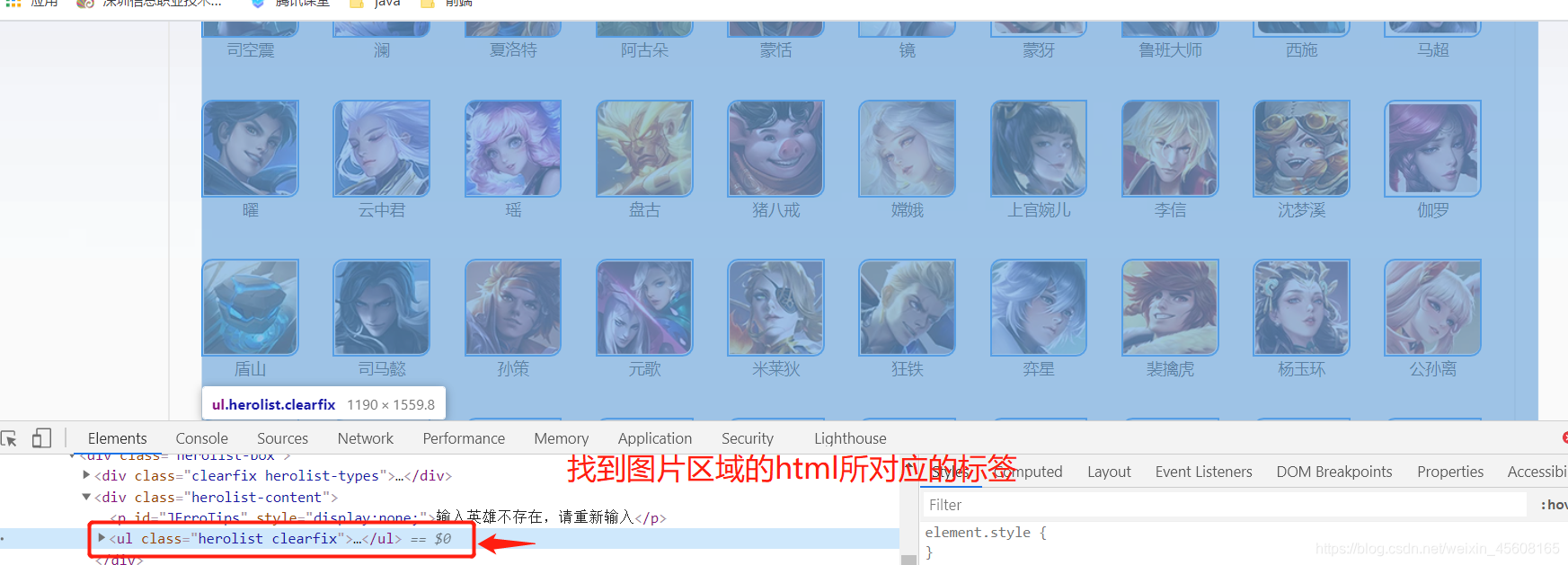
-
通过Jsoup类中静态方法connect()连接网址https://pvp.qq.com/web201605/herolist.shtml
-
通过Connection对象获取Document对象(即文档对象)
-
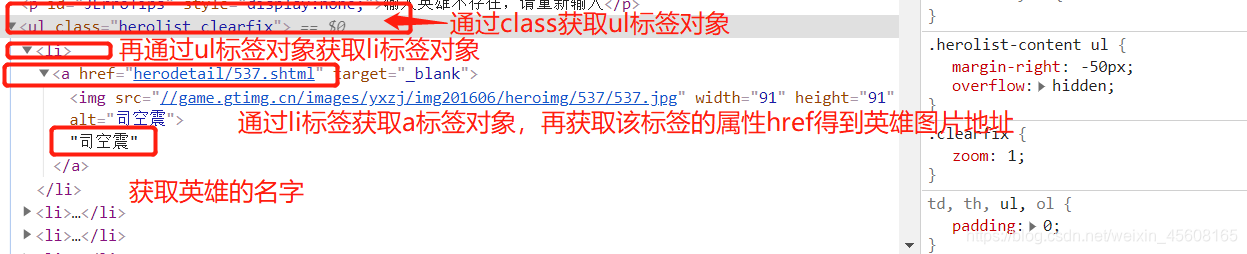
通过Document对象获取标签Elements对象
-
遍历所有的li标签,得到该英雄的图片地址
-
通过获取所有得到的新地址,再通过定位得到图片对应的jpg格式

-
通过输入输出流将图片读取到本地
代码
public class TestMain {
public static void crawlingPictures() throws IOException {
//连接网址
Connection connect = Jsoup.connect("https://pvp.qq.com/web201605/herolist.shtml");
//获取网址的Document对象
Document document = connect.get();
//获取照片的ul中class标签
Elements byClass = document.getElementsByClass("herolist clearfix");
//通过ul中class标签中的li标签获取照片的地址
Elements li = byClass.select("li");
//循环遍历每一个li标签的照片地址
for (Element element : li) {
//找到li中的a标签
Elements a = element.getElementsByTag("a");
//通过a标签中的href属性获取相应的值
String hrefs = a.attr("href");
//拼接成一个完整的图片新地址
String path="https://pvp.qq.com/web201605/"+hrefs;
//获取照片text中的名字
String text = a.text();
//通过新照片地址打开另一个网址(拼接好的英雄图片地址)
Connection connection = Jsoup.connect(path);
//获取新照片地址的Document对象
Document doc = connection.get();
//获取照片div中的class对象
Elements picclass = doc.getElementsByClass("zk-con1 zk-con");
//获取div中的属性style
String attr = picclass.attr("style");
//截取属性值的字符串表示形式
String substring = attr.substring(attr.indexOf("'") + 1, attr.lastIndexOf("'"));
//拼接成一个URL的照片地址
String newUrl="https:"+substring;
//通过拼接好的字符串构建成URL对象
URL url=new URL(newUrl);
//InputStream inputStream = url.openStream();
byte[] bytes=new byte[1024];
//通过URL打开输入流读取数据
BufferedInputStream bis=new BufferedInputStream(url.openStream());
int read =bis.read(bytes);
//通过输出流写入图片数据
BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream("D:\\下载\\test\\"+text+".jpg"));
//读取的数据不为-1
while (read!=-1){
//写入本地
bos.write(bytes,0,read);
bos.flush();
read=bis.read(bytes);
}
//关闭流操作
bos.close();
bis.close();
bis.close();
}
}
public static void main(String[] args) {
try {
crawlingPictures();
} catch (Exception e) {
e.printStackTrace();
}
}
}
**测试结果,读取完毕 **
