简书里的文章有分专题,如
然后随便进入一个专题:
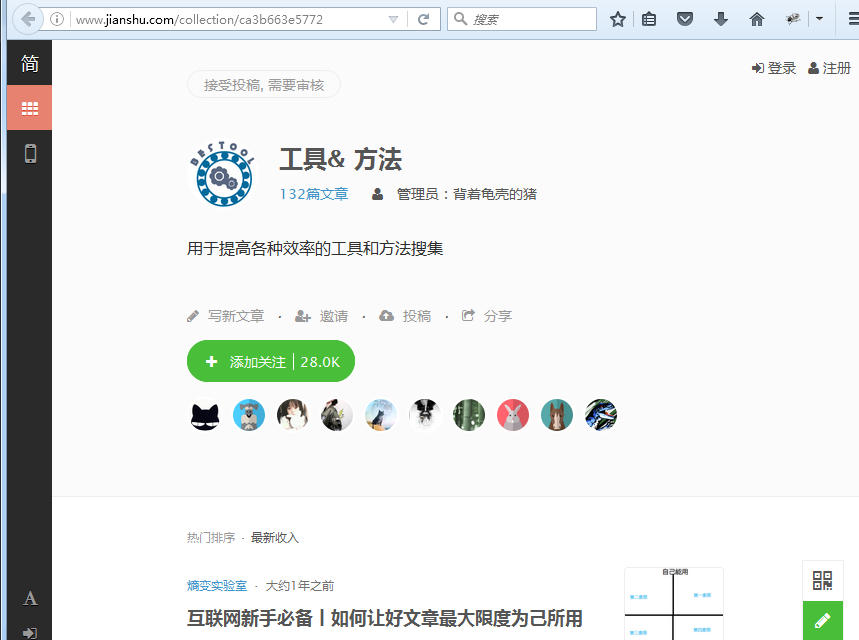
然后问题来,这个专题里面总共有132篇文章,但是先看看它的源代码,里面的有一篇文章居然在源码里搜不到!这也就意味着这篇文章的链接就提取不到了!它的源码里只有到《别再信息偏食……》的内容
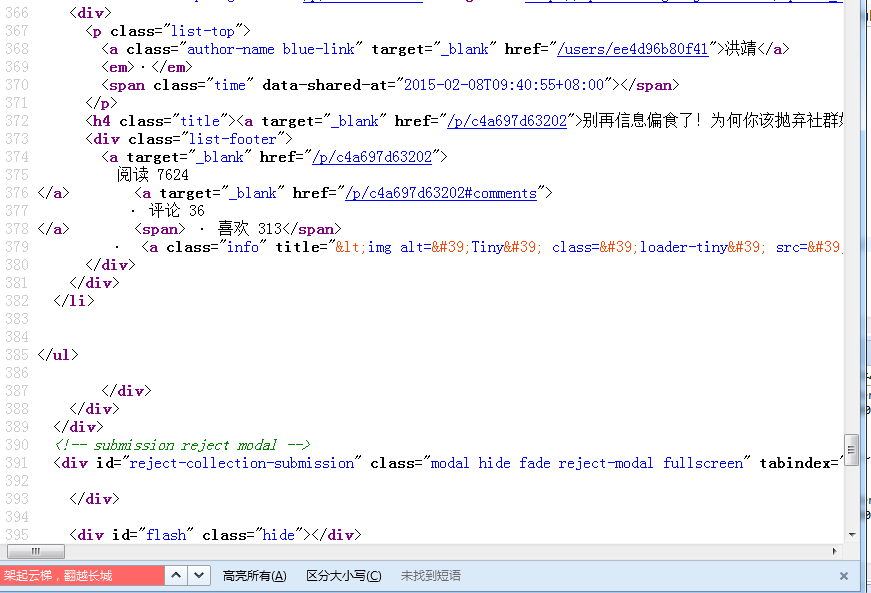
好吧,那么要怎么才能把一个专题给爬取完全呢?先开启浏览器网络模式,随着鼠标下滑,发现页面进行了新的载入。
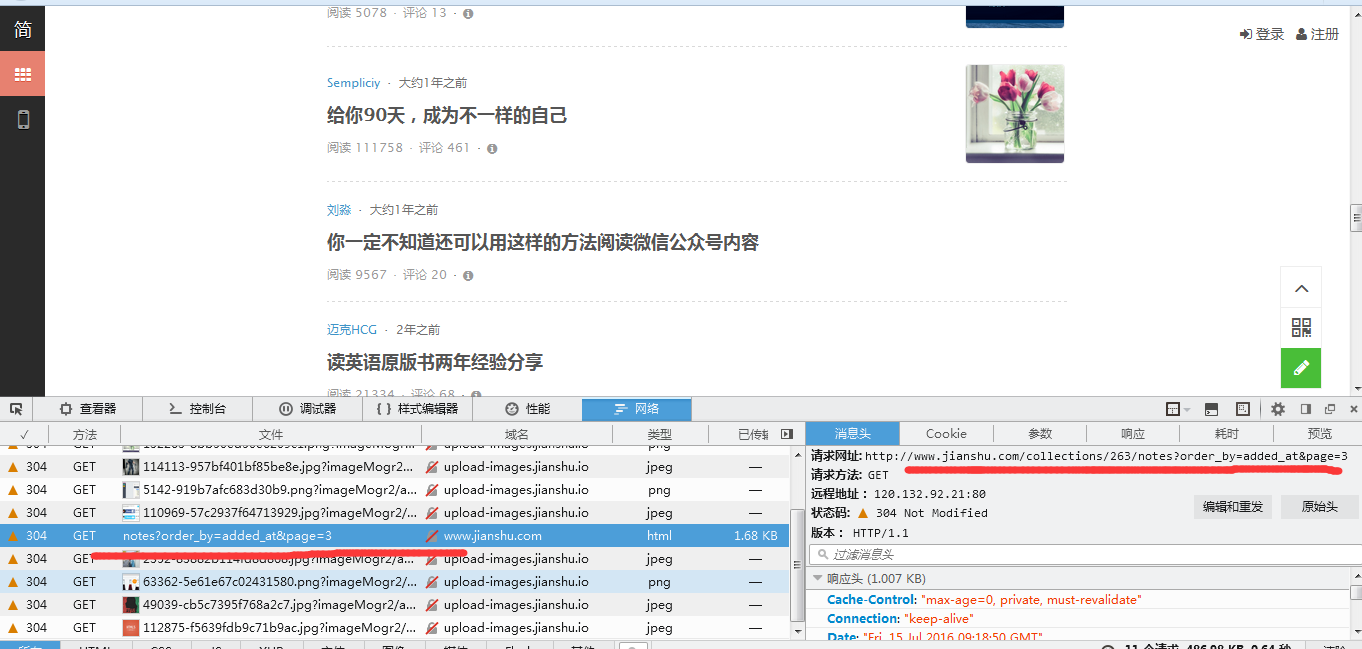
分析新的url,发现专题是通过page来实现页面载入了,那就好办了。在上篇介绍的爬取代码里稍作修改即可:
import java.io.FileWriter;
import java.io.IOException;
import java.util.Vector;
import com.hpre.spider.common.Function;
import com.hpre.spider.tools.Tools;
public class Download_jianshuxiahua {
public static void main(String[] args) throws IOException {
String url = "http://www.jianshu.com/collection/ca3b663e5772"; //专题url
byte[] information = Function.download(url);
// System.out.println(new String(information));
Vector<String> hrefs = new Vector<String>();
Vector<String> title = new Vector<String>();
FileWriter writer;
Tools.getMultiResultsByOneXpathPattern(information, "utf-8",
"//div[@id='list-container']//li[@class='have-img']/div/h4/a/text()", title);
Tools.getMultiResultsByOneXpathPattern(information, "utf-8",
"//div[@id='list-container']//li[@class='have-img']/div/h4/a/@href", hrefs);
for (int j = 0 ;j<=4000;j++){
String page_url = "http://www.jianshu.com/collections/263/notes?order_by=added_at&page="+(j+2);
byte[] more_information = Function.download(page_url);
if (more_information.length<=13192){
break;
}
Tools.getMultiResultsByOneXpathPattern(more_information, "utf-8",
"//div[@id='list-container']//li[@class='have-img']/div/h4/a/text()", title);
Tools.getMultiResultsByOneXpathPattern(more_information, "utf-8",
"//div[@id='list-container']//li[@class='have-img']/div/h4/a/@href", hrefs);
}
for (int i = 0;i<hrefs.size();i++){
Vector<String> content = new Vector<String>();
String new_href = "http://www.jianshu.com" + hrefs.get(i);
byte[] detail_information = Function.download(new_href);
Tools.getMultiResultsByOneXpathPattern(detail_information, "utf-8",
"//div[@class='show-content']//p/text()", content);
System.out.println(content.toString());
writer = new FileWriter("C://Users//Administrator//Desktop//gongju//"+title.get(i).trim().replace("|", "")
.replace("?", "")+".txt");
for (int n = 0;n<content.size();n++){
String lines = content.get(n).trim() + "\r\n";
writer.write(lines);
}
writer.flush();
writer.close();
}
}
}
成果如下,是不是so easy: